
3.3: Alineación global vs. alineación local vs. alineación semi-global
- Page ID
- 54230

Una alineación global se define como la alineación de extremo a extremo de dos cadenas s y t.
Una alineación local de cadenas s y t es una alineación de subcadenas de s con subcadenas de t.
En general se utilizan para encontrar regiones de alta similitud local. A menudo, estamos más interesados en encontrar locales
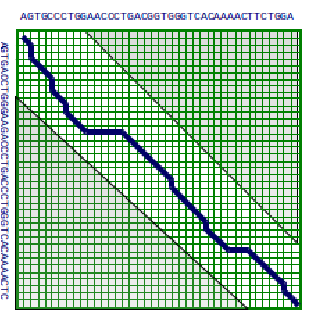
alineaciones porque normalmente no conocemos los límites de los genes y sólo se puede conservar un pequeño dominio del gen. En tales casos, no queremos hacer cumplir que otras partes (potencialmente no homólogas) de la secuencia también se alineen. El alineamiento local también es útil cuando se busca un gen pequeño en un cromosoma grande o para detectar cuándo una secuencia larga puede haber sido reordenada (Figura 4).
Una alineación semi-global de cadena s y t es una alineación de una subcadena de s con una subcadena de t.
Esta forma de alineación es útil para la detección de solapamientos cuando no deseamos penalizar las brechas iniciales o finales. Para encontrar una alineación semi-global, las distinciones importantes son inicializar la fila superior y la columna más a la izquierda a cero y terminar el extremo en la fila inferior o la columna más a la derecha.
El algoritmo es el siguiente:
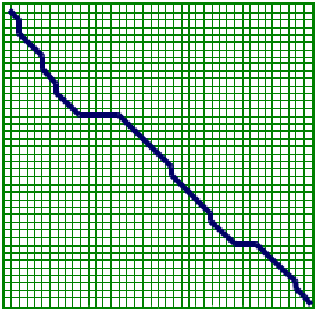
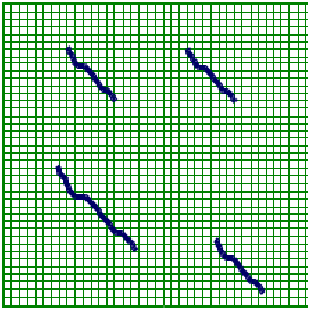
Figura 3.3: Alineación local
\ [
\ begin {array} {l}
\ text {Inicialización}:\ begin {aligned}
F (i, 0) =0\\
F (0, j) =0
\ end {alineado}\\
\ qquad\ begin {alineado}
\ text {iteración}: & F (i, j) =\ max\ left\ {\ begin {alineado}
F (i-1, j) -d\\
F (i, j-1) -d &\\
F (i-1, j-1) +s\ izquierda (x_ {i}, y_ {j}\ derecha)
\ end {alineada}\ derecha.
\ end {alineado}
\ end {array}
\]
\[\text{Termination : Bottom row or Right column} \nonumber \]
Uso de la programación dinámica para alineaciones locales
En esta sección veremos cómo encontrar alineaciones locales con una modificación menor del algoritmo de Needleman-Wunsch que se discutió en el capítulo anterior para encontrar alineaciones globales.
Para encontrar alineaciones globales, se utilizó el siguiente algoritmo de programación dinámica (algoritmo Needleman-Wunsch):
\[ \text {Initialization : F(0,0)=0} \nonumber \]
\[\begin{aligned} \text { Iteration } &: F(i, j)=\max \left\{\begin{aligned} F(i-1, j)-d \\ F(i, j-1)-d \\ F(i-1, j-1)+s\left(x_{i}, y_{j}\right) \end{aligned}\right.\end{aligned}\]
\[\text{Termination : Bottom right} \nonumber \]
Para encontrar alineaciones locales solo necesitamos modificar ligeramente el algoritmo de Needleman-Wunsch para comenzar de nuevo y encontrar una nueva alineación local siempre que la puntuación de alineación existente sea negativa. Dado que una alineación local puede comenzar en cualquier lugar, inicializamos la primera fila y columna de la matriz a ceros. El paso de iteración se modifica para incluir un cero para incluir la posibilidad de que iniciar una nueva alineación sea más económico que tener muchos desajustes. Además, dado que la alineación puede terminar en cualquier lugar, necesitamos atravesar toda la matriz para encontrar la puntuación de alineación óptima (no solo en la esquina inferior derecha). El resto del algoritmo, incluido el rastreo, permanece sin cambios, con rastreo indicando un final en cero, indicando el inicio de la alineación óptima.
Estos cambios dan como resultado el siguiente algoritmo de programación dinámica para la alineación local, que también se conoce como:
\ [\ begin {array} {ll}
\ text {Inicialización}: & F (i, 0) =0\\
& F (0, j) =0
\ end {array}\ nonumber\]
\ [\ text {Iteración}:\ quad F (i, j) =\ max\ izquierda\ {\ begin {array} {c}
0\\
F (i-1, j) -d\\
F (i, j-1) -d\\
F (i-1, j-1) +s\ left (x_ {i}, y_ {j}\ right)
\ end {array}\ derecha. \ nonumber\]
\[ Termination : Anywhere \nonumber \]
Variaciones algorítmicas
A veces puede resultar costoso tanto en tiempo como en espacio ejecutar estos algoritmos de alineación. Por lo tanto, en esta sección se presentan algunas variaciones algorítmicas para ahorrar tiempo y espacio que funcionan bien en la práctica.
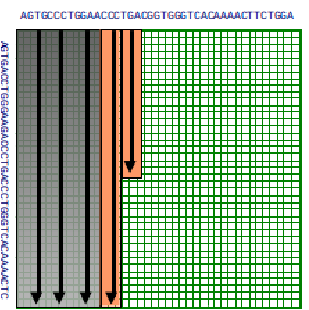
Un método para ahorrar tiempo, es la idea de delimitar el espacio de alineaciones a explorar. La idea es que las buenas alineaciones generalmente se mantengan cerca de la diagonal de la matriz. Así podemos simplemente explorar celdas de matriz dentro de un radio de k desde la diagonal. El problema con esta modificación es que se trata de una heurística y puede conducir a una solución subóptima ya que no incluye los casos límite mencionados al inicio del capítulo. Sin embargo, esto funciona muy bien en la práctica. Además, dependiendo de las propiedades de la matriz de puntuación, puede ser posible argumentar la corrección del algoritmo de espacio rebotado. Este algoritmo requiere\( O(k ∗ m) \) espacio y\( O(k ∗ m) \) tiempo.
Anteriormente vimos que para calcular la solución óptima, necesitábamos almacenar la puntuación de alineación en cada celda así como el puntero reflejando la elección óptima que conduce a cada celda. Sin embargo, si solo nos interesa la puntuación óptima de alineación, y no la alineación real en sí, existe un método para calcular la solución mientras se ahorra espacio. Para calcular la puntuación de cualquier celda solo necesitamos las puntuaciones de la celda anterior, a la izquierda, y a la diagonal izquierda de la celda actual. Al guardar la columna anterior y actual en la que estamos calculando puntuaciones, la solución óptima se puede calcular en el espacio lineal.
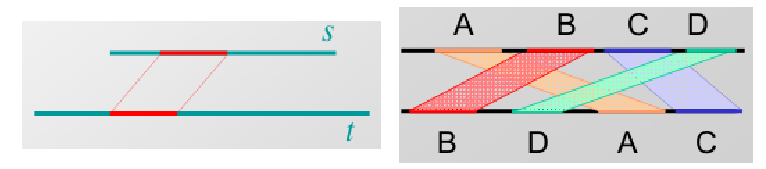
Si utilizamos el principio de dividir y conquistar, en realidad podemos encontrar la alineación óptima con el espacio lineal. La idea es que calculemos las alineaciones óptimas desde ambos lados de la matriz, es decir, de izquierda a derecha, y viceversa. Vamos\( u=\left\lfloor\frac{n}{2}\right\rfloor \). Digamos que podemos identificar v tal que la célula\( (u, v) \) está en el óptimo
© fuente desconocida. Todos los derechos reservados. Este contenido está excluido de nuestra licencia Creative Commons. Para obtener más información, consulte http://ocw.mit.edu/help/faq-fair-use/.
trayectoria de alineación. Eso significa que v es la fila donde la alineación cruza la columna u de la matriz. Podemos encontrar la alineación óptima concatenando las alineaciones óptimas de (0,0) a (u, v) más la de (u, v) a (m, n), donde m y n es la celda inferior derecha (nota: las puntuaciones de alineación de las subalineaciones concatenadas usando nuestro esquema de puntuación son aditivas. Así que hemos aislado nuestro problema a dos problemas separados en las esquinas superior izquierda e inferior derecha de la matriz DP. Entonces podemos seguir dividiendo recursivamente estos subproblemas en subproblemas más pequeños, hasta que estemos abajo a alinear secuencias de longitud 0 o nuestro problema sea lo suficientemente pequeño como para aplicar el algoritmo DP regular. Para encontrar v la fila en la columna central donde se cruza la alineación óptima simplemente agregamos las puntuaciones entrantes y salientes para esa columna.
Un inconveniente de este enfoque de dividir y conquistar es que tiene un tiempo de ejecución más largo. Sin embargo, el tiempo de ejecución no se incrementa drásticamente. Dado que v se puede encontrar usando una pasada de DP regular, podemos encontrar v para cada columna en\( O(mn) \) tiempo y espacio lineal ya que no necesitamos realizar un seguimiento de los punteros de rastreo para este paso. Luego al aplicar el enfoque dividir y conquistar, los subproblemas tardan la mitad del tiempo ya que solo necesitamos hacer un seguimiento de las celdas diagonalmente a lo largo de la trayectoria de alineación óptima (la mitad de la matriz del paso anterior) Eso da un tiempo de ejecución total de\( O\left(m n\left(1+\frac{1}{2}+\frac{1}{4}+\ldots\right)\right)=O(2 M N)=O(m n) \) (usando la suma de series geométricas), para darnos un tiempo de ejecución cuadrática (dos veces más lento que antes, pero sigue siendo el mismo comportamiento asintótico). El tiempo total nunca superará\( 2MN \) (el doble del tiempo que el algoritmo anterior). Aunque el tiempo de ejecución se incrementa en un factor constante, una de las grandes ventajas del enfoque de dividir y conquistar es que el espacio se reduce drásticamente a\( O(N) \).
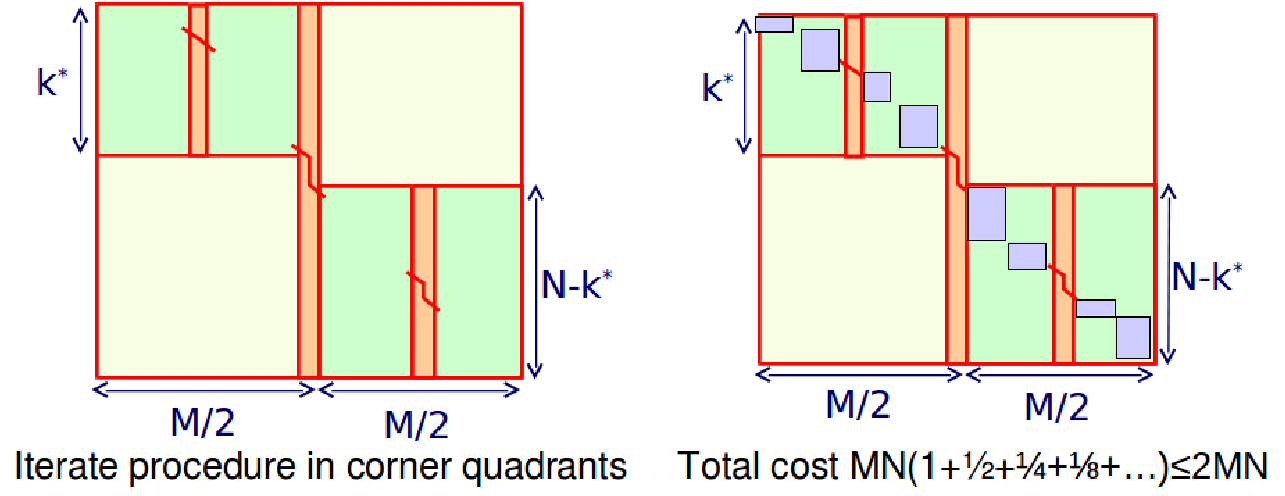
Figura 3.9: Divide y vencerás
P: ¿Por qué no usar la variación de espacio rebotado sobre la variación de espacio lineal para obtener tanto el tiempo lineal como el espacio lineal?
R: La variación del espacio rebotado es un enfoque heurístico que puede funcionar bien en la práctica pero no garantiza la alineación óptima.
Sanciones por brecha generalizada
Las penalizaciones por brecha determinan la puntuación calculada para una subsecuencia y así afectan qué alineación se selecciona. El modelo normal es usar a donde cada hueco individual en una secuencia de huecos de longitud k se penaliza por igual con valor p. Esta penalización puede modelarse como\( w(k) = k ∗ p \). Dependiendo de la situación, podría ser una buena idea penalizar de manera diferente por, digamos, brechas de diferentes longitudes. Un ejemplo de esto es un en el que la penalización incremental disminuye cuadráticamente a medida que crece el tamaño de la brecha. Esto se puede modelar como\( w(k) = p+q∗k+r∗k2 \). Sin embargo, la compensación es que también hay costos asociados con el uso de funciones de penalización de brecha más complejas al aumentar sustancialmente el tiempo de ejecución. Este costo puede mitigarse usando aproximaciones más simples a las funciones de penalización por brecha. El es un intermedio fino: se tiene una penalización fija para iniciar una brecha y un costo lineal para agregar a una brecha; esto se puede modelar como\( w(k) = p + q ∗ k \).
También se pueden considerar funciones más complejas que tomen en consideración las propiedades de las secuencias codificadoras de proteínas. En el caso del alineamiento de regiones codificadoras de proteínas, un hueco de longitud mod 3 puede ser menos penalizado porque no resultaría en un desplazamiento de marco.