
17.1: Representación de Motivos y Contenido de Información
- Page ID
- 54210

En lugar de una Matriz de Perfil, también podemos representar Motivos usando la teoría de la información. En la teoría de la información, la información sobre un determinado evento se comunica a través de un mensaje. La cantidad de información transportada por un mensaje se mide en bits. Podemos determinar los bits de información transportados por un mensaje observando la distribución de probabilidad del evento descrito en el mensaje. Básicamente, si no sabemos nada sobre el resultado del evento, el mensaje contendrá muchos bits. No obstante, si estamos bastante seguros de cómo va a llevarse a cabo el evento, y el mensaje sólo confirma nuestras sospechas, el mensaje lleva muy pocos bits de información. Por ejemplo, La sentencia 0un se levantará mañana” no es muy sorprendente, por lo que la información de esa sentencia si es bastante baja.. No obstante, la sentencia 0un no se levantará mañana” es muy sorprendente y tiene un alto contenido de información. Podemos calcular la cantidad específica de información en un mensaje dado con la ecuación: − log p.
La entropía de Shannon es una medida de la cantidad esperada de información contenida en un mensaje. En otras palabras, es la información contenida por un mensaje de cada evento que posiblemente pueda ocurrir ponderada por cada probabilidad de eventos. La entropía de Shannon viene dada por la ecuación:
\[ H(X)=-\sum_{i} p_{i} \log _{2} p_{i} \nonumber \]
La entropía es máxima cuando todos los eventos tienen la misma probabilidad de ocurrir. Esto se debe a que la Entropía nos dice la cantidad esperada de información que aprenderemos. Si cada uno incluso tiene las mismas posibilidades de ocurrir sabemos lo menos posible sobre el evento, por lo que se maximiza la cantidad esperada de información que aprenderemos. Por ejemplo, un volteo de moneda tiene una entropía máxima solo cuando la moneda es justa. Si la moneda no es justa, entonces sabemos más sobre el evento de la volteo de moneda, y el mensaje esperado del resultado del flip de moneda contendrá menos información.
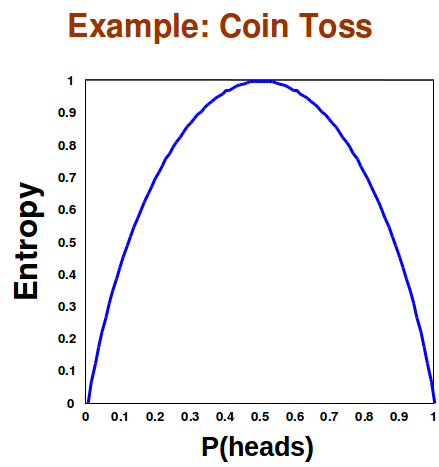
Figura 17.11: La entropía se maximiza cuando tanto la cabeza como la cola tienen la misma probabilidad de ocurrir
Podemos modelar un motivo por la cantidad de información que tenemos de cada posición después de aplicar Gibs Sampling o EM. En la siguiente figura, la altura de cada letra representa el número de bits de información que hemos aprendido sobre esa base. Las pilas más altas corresponden a una mayor certeza sobre cuál es la base en esa posición del motivo, mientras que las pilas inferiores corresponden a un mayor grado de incertidumbre. Con cuatro codones para elegir, la Entropía Shannon de cada posición es de 2 bits. Otra forma de observar esta figura es que la altura de una letra es proporcional a la frecuencia de la base en esa posición.

Figura 17.12: La altura de cada pila representa el número de bits de información que el muestreo de Gibbs o EM nos contó sobre la posición en el motivo
Hay una métrica de distancia en las distribuciones de probabilidad conocida como distancia Kullback-Leibler. Esto nos permite comparar la divergencia de la distribución de motivos con alguna distribución verdadera. La distancia K-L viene dada por
\[ D_{K L}\left(P_{\text {motif}} \mid P_{\text {background}}\right)=\Sigma_{A, T, G, C} P_{\text {motif}}(i) \log \underset{P \text {background}(i)}{P_{\text {motif}}(i)} \nonumber \]
En Plasmodium, hay un menor contenido de G-C. Si asumimos un contenido de G-C del 20%, entonces obtenemos la siguiente representación para el motivo anterior. Las bases C y G son mucho más inusuales, por lo que su prevalencia es muy inusual. Tenga en cuenta que en esta representación, se utilizó la distancia K-L, de manera que es posible que la pila sea superior a 2.
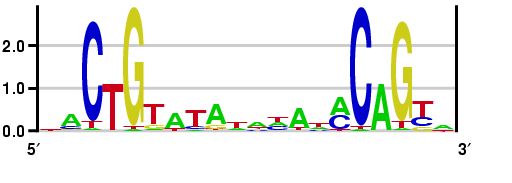
Figura 17.13: Sitio de unión LexA asumiendo bajo contenido de G-C y usando distancia K-L
Bibliografía
- [1] Timothy L. Bailey. Ajustar un modelo de mezcla por maximización de expectativas para descubrir motivos en biopolímeros. En Actas de la Segunda Conferencia Internacional sobre Sistemas Inteligentes para la Biología Molecular, páginas 28—36. Prensa AAAI, 1994.
- [2] C E Lawrence y A A Reilly. Un algoritmo de maximización de expectativas (em) para la identificación y caracterización de sitios comunes en secuencias de biopolímeros no alineados. Proteínas, 7 (1) :41—51, 1990.