
11.3: Colinealidad de genes y proteínas y codones tripletes
- Page ID
- 54105

Los serios esfuerzos para entender cómo se codifican las proteínas comenzaron después de que Watson y Crick utilizaron la evidencia experimental de Maurice Wilkins y Rosalind Franklin (entre otros) para determinar la estructura del ADN. La mayoría de las hipótesis sobre el código genético asumen que el ADN (es decir, los genes) y los polipéptidos eran colineales.
A. Colinealidad
Para genes y proteínas, colinealidad solo significa que la longitud de una secuencia de ADN en un gen es proporcional a la longitud del polipéptido codificado por el gen. Los experimentos de mapeo genético en E. coli ya discutidos apoyaron ciertamente esta hipótesis.
A continuación se ilustra el concepto de colinealidad.
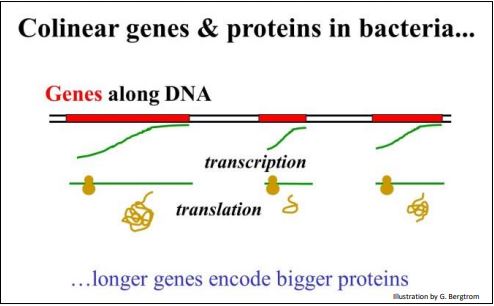
Si el código genético es colineal con los polipéptidos que codifica, entonces un codón de una base obviamente no funciona porque tal código solo representaría cuatro aminoácidos. Un código genético de dos bases tampoco funciona porque solo podría dar cuenta de 16 (4 2) de los veinte aminoácidos que se encuentran en las proteínas. Sin embargo, los codones de treenucleótidos podrían codificar un máximo de 43 o 64 aminoácidos, más que suficiente para codificar los 20 aminoácidos. Y por supuesto, también funciona un código de 4 bases; satisface la expectativa de que los genes y las proteínas sean colineales, con la 'ventaja' de que habría 256 codones posibles para elegir (es decir, 44 posibilidades).
B. ¿Cómo se 'lee' el código genético para dar cuenta de todos los genes de un órgano?
George Gamow (un físico ruso que trabaja en la Universidad George Washington) fue el primero en proponer codones tripletes para codificar los veinte aminoácidos, la hipótesis más simple para dar cuenta de la colinealidad de genes y proteínas, y para codificar 20 aminoácidos. Una preocupación que se planteó fue si hay suficiente ADN en el genoma de un organismo para ajustarse a todos los codones que necesita para elaborar todas sus proteínas. Suponiendo que los genomas no tenían mucho ADN extra por ahí, ¿cómo podría comprimirse la información genética en secuencias cortas de ADN de una manera que sea consistente con la colinealidad de genes y polipéptidos? Una idea asumió 44 codones de 3 bases sin sentido y 20 significativos (uno por cada aminoácido) y 44 codones sin sentido, y que los codones significativos en un gen (es decir, un ARNm) serían leídos y traducidos de manera superpuesta.
A continuación se muestra un código donde los codones se superponen por una base.

Se puede averiguar qué tan comprimido podría llegar un gen con codones que se superponen por dos bases. Sin embargo, tan atractiva como una hipótesis de codón superpuesto fue para lograr economías genómicas, ¡se hundió de su propio peso casi tan pronto como flotó! Si miras detenidamente el ejemplo anterior, puedes ver que cada aminoácido sucesivo tendría que comenzar con una base específica. Una mirada retrospectiva a la tabla de 64 codones tripletes muestra rápidamente que solo uno de los 16 aminoácidos, los que comienzan con una C pueden seguir al primero de la ilustración. Basado en secuencias de aminoácidos acumuladas en la literatura, prácticamente cualquier aminoácido podría seguir a otro en un polipéptido. Por lo tanto, los códigos genéticos superpuestos son insustentables. ¡El código genético debe ser no superpuesto!
Sidney Brenner y Frances Crick realizaron experimentos elegantes que demostraron directamente el código genético no superpuesto. Mostraron que las bacterias con una deleción de una sola base en la región codificante de un gen no lograron producir la proteína esperada. De igual manera, eliminando dos bases del gen. Por otro lado, las bacterias que contenían una versión mutante del gen en la que se eliminaron tres bases pudieron producir la proteína. La proteína que produjo fue ligeramente menos activa que las bacterias con genes sin deleciones.
El siguiente tema fue si solo había 20 codones significativos y 44 sin sentido. Si solo 20 tripletes realmente codificaran aminoácidos, ¿cómo reconocería la maquinaria de traducción los 20 codones correctos para traducir? ¿Qué impediría que la maquinaria traslacional 'leyera los trillizos equivocados', es decir, leer un ARNm desfasado? Si por ejemplo, si la maquinaria de traducción comenzara a leer un ARNm de la segunda o tercera bases de un codón, probablemente encontraría una secuencia de 3 bases sin sentido en poco tiempo.
Una especulación fue que el código estaba puntuado. Es decir, tal vez hubo el equivalente químico de comas entre los trillizos significativos. Las comas serían por supuesto, nucleótidos adicionales. En tal código puntuado, la maquinaria de traducción reconocería las 'comas' y no traduciría ningún triplete sin sentido de 3 bases, evitando intentos de traducción fuera de fase. Por supuesto, ¡un código con 'comas' de nucleótidos aumentaría en un tercio la cantidad de ADN necesaria para especificar un polipéptido!
Entonces, Crick propuso el Código Genético Commaless. Dividió los 64 trillizos en 20 codones significativos que codificaban los aminoácidos, y 44 sin sentido que no lo hicieron. El resultado fue tal que cuando los 20 codones significativos se colocan en cualquier orden, cualquiera de los trillizos leídos en superposición estaría entre los 44 codones sin sentido. De hecho, ¡podría arreglar varios conjuntos diferentes de 20 y 44 trillizos con esta propiedad! Crick había demostrado hábilmente cómo leer los tripletes en la secuencia correcta sin “comas” de nucleótidos.
202 Especulaciones sobre un Código Triplete
Como sabemos ahora, el código genético es efectivamente 'commaless'... pero no en el sentido que Crick había imaginado. Además, gracias a los experimentos que se describen a continuación, sabemos que los ribosomas leen los codones correctos en el orden correcto porque ¡saben exactamente por dónde empezar!
C. Rompiendo el Código Genético
Cuando en realidad se rompió el código genético, se encontró que 61 de los codones especifican aminoácidos y por lo tanto, que el código es degenerado. Romper el código comenzó cuando Marshall Nirenberg y Heinrich J. Matthaei decodificaron el primer triplete. Fraccionaron E. coli e identificaron qué fracciones tuvieron que volver a agregarse para obtener la síntesis de polipéptidos en un tubo de ensayo (traducción in vitro).
A continuación se resume el fraccionamiento celular.
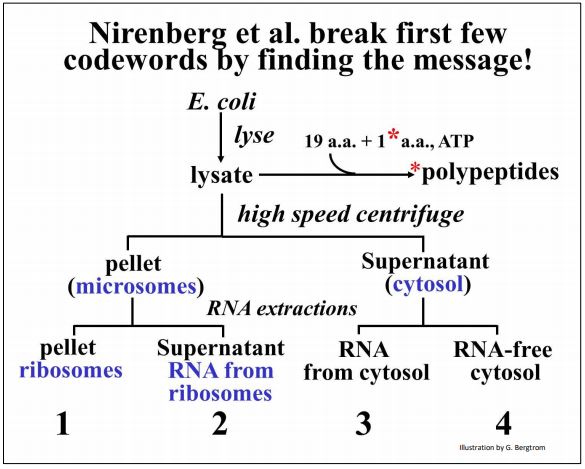
Echa un vistazo al trabajo original en el artículo clásico de Nirenberg MW y Matthaei JH [(1961) La dependencia de la síntesis de proteínas libres de células en E. coli sobre polinucleótidos naturales o sintéticos. Proc. Natl. Acad. Sci. USA 47:1588-1602]. Las diversas fracciones celulares aisladas por este protocolo se agregaron de nuevo junto con aminoácidos (uno de los cuales era radiactivo) y ATP como fuente de energía. Después de una breve incubación, Nirenberg y sus compañeros de trabajo buscaron la presencia de proteínas radiactivas de alto peso molecular como evidencia de síntesis de proteínas libres de células.
Encontraron que las cuatro subfracciones finales (1-4 arriba) deben agregarse juntas para hacer proteínas radiactivas en el tubo de ensayo. Una de las fracciones celulares esenciales consistió en ARN que había sido extraído suavemente del ribosoma (fracción 2 en la ilustración). Razonando que este ARN podría ser ARNm, sustituyeron una preparación sintética de poli (U) por esta fracción en su mezcla de síntesis de proteínas libres de células, esperando que poli (U) codifique un aminoácido de repetición simple.
Montaron 20 tubos de reacción, con un aminoácido diferente en cada..., y elaboraron solo polifenilalanina. El experimento se ilustra a continuación.
Entonces, el codón triplete UUU significa fenilalanina. Otros polinucleótidos fueron sintetizados por G. Khorana, y en rápida sucesión, se demostró que poli (A) y poli (C) producen poli-lisina y poli-prolina en este protocolo experimental. Así, AAA y CCC deben codificar lisina y prolina respectivamente. Con un poco más de dificultad e ingenio, también se utilizaron poli di- y tri-nucleótidos en el sistema libre de células para descifrar varios codones adicionales.
203 Descifrando el primer codón
M. W. Nirenberg, H. G. Khorana y R. W. Holley compartieron el Premio Nobel de Fisiología o Medicina 1968 por sus contribuciones a nuestra comprensión de la síntesis proteica. Descifrar el resto del código genético se basó en la comprensión de Crick de que químicamente, los aminoácidos no tienen atracción por el ADN o el ARN (o sus tripletes). En cambio, predijo la existencia de una molécula adaptador que contendría información de ácidos nucleicos y aminoácidos en la misma molécula. Hoy reconocemos esta molécula como ARNt, el dispositivo de decodificación genética.
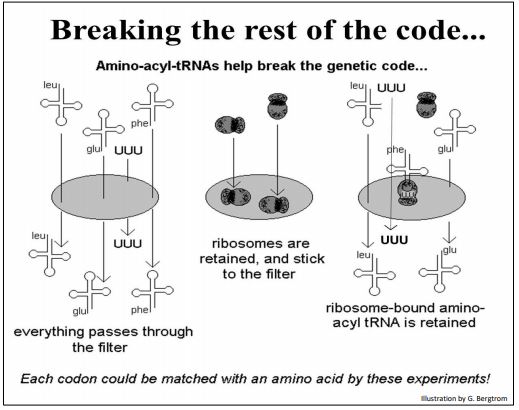
Nirenberg y Philip Leder diseñaron el experimento que prácticamente rompió el resto del código genético. Lo hicieron agregando aminoácidos individuales a tubos de ensayo separados que contenían ARNt, provocando en efecto la síntesis de aminoacil-ARNt específicos.
Luego mezclaron sus ARNt unidos a aminoácidos con ribosomas aislados y tripletes sintéticos. Como ya habían demostrado que los fragmentos sintéticos de tres nucleótidos se unirían a los ribosomas, plantearon la hipótesis de que los ribosomas unidos a tripletes, a su vez, se unirían a los ARNt apropiados unidos a aminoácidos. El experimento se muestra a continuación.
Varias combinaciones de ARNt, ribosomas y aminoacil-ARNt se colocaron sobre un filtro. Nirenberg y Leder sabían que los aminoacil-ARNt solos pasaban por el filtro y que los ribosomas no lo hacían. Predijeron entonces, que los tripletes se asociarían con los ribosomas, y además, que este complejo uniría el ARNt con el aminoácido codificado por el triplete unido. Este complejo de 3 partes también sería retenido por el filtro, permitiendo la identificación del aminoácido retenido en el filtro, y por lo tanto la palabra clave triplete que había permitido unir el aminoácido al ribosoma.
204 Descifrando todos los 64 codones de triplete
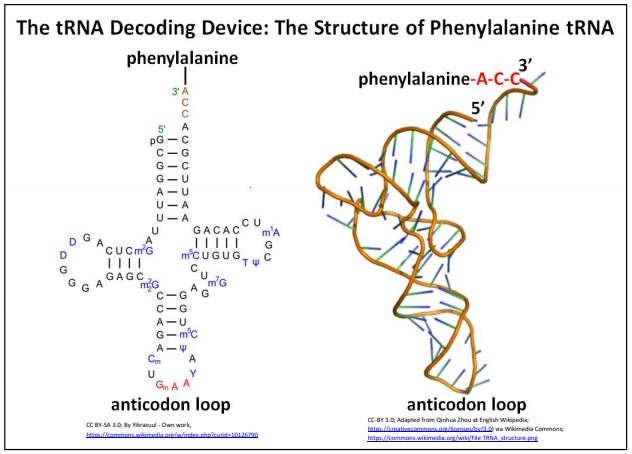
Después de que el código fue ampliamente descifrado, Robert Holley en realidad secuenció un ARNt de levadura, y a partir de regiones de complementariedad interna, predijo la estructura plegada del ARNt. Esta primera secuenciación exitosa de un ácido nucleico fue posible porque el ARNt era corto, y contenía varias bases modificadas que facilitaron la química de secuenciación. Holley encontró el aminoácido alanina en un extremo del ARNt y encontró uno de los anticodones para un codón de alanina aproximadamente en el medio de la secuencia de ARNt. Holley predijo que este (y otros) ARNt se plegarían y asumirían una estructura tallo-bucle o trébol con un bucle anticodón central. La siguiente ilustración muestra esta estructura para un ARNt de fenilalanina junto con estructuras posteriores generadas por computadora (abajo a la derecha) que muestran una molécula ahora familiar en forma de “L” con un sitio de unión de aminoácidos en el extremo 3' en la parte superior de la molécula, y el bucle anticodón en el otro, 'extremo' inferior
205 Modificaciones de estructura y base de ARNt
Después de una breve descripción general de la traducción, desglosaremos la traducción en sus 3 pasos y veremos cómo funcionan los aminoacil-ARNt en las etapas de iniciación y elongación de la traducción, así como el papel especial de un ARNt iniciador.