
20.7: Redes neuronales
- Page ID
- 54835

Las redes neuronales salieron modelando el cerebro y el sistema nervioso en un intento de lograr un aprendizaje similar al del cerebro. Son muy paralelos y al aprender conceptos simples podemos lograr comportamientos muy complejos. En relevancia para este libro, también han demostrado ser muy buenos modelos biológicos (no es de extrañar dar de dónde surgieron).
Redes de alimentación directa
En una red neuronal mapeamos la entrada a la salida pasando por estados ocultos que son parametrizados por aprendizaje.
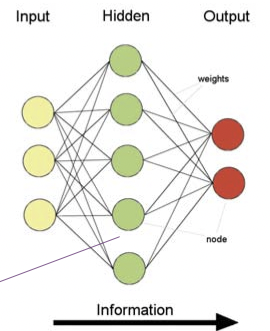
• El flujo de información es unidireccional
• Los datos se presentan a la capa de entrada
• Pasado a capa oculta
• Pasado a capa de salida
• La información se distribuye
• El procesamiento de la información es paralelo
Back-propagación
La retropropagación es uno de los resultados más influyentes para entrenar redes neuronales y permitirnos lidiar fácilmente con redes multicapa.
• Requiere conjunto de entrenamiento (pares de entrada-salida)
• Comienza con pequeños pesos aleatorios
• Error se usa para ajustar pesos (aprendizaje supervisado)
Básicamente realiza descenso de gradiente en el paisaje de error tratando de minimizar el error. Así, la retropropagación puede ser lenta.
Aprendizaje Profundo
El aprendizaje profundo es una colección de técnicas estadísticas de aprendizaje automático utilizadas para aprender jerarquías de características. A menudo se basa en redes neuronales artificiales. Las redes neuronales profundas tienen más de una capa oculta. Cada capa sucesiva en una red neuronal utiliza entidades en la capa anterior para aprender entidades más complejas. Uno de los objetivos (relevantes) de los métodos de aprendizaje profundo es realizar la extracción jerárquica de características. Esto hace que el aprendizaje profundo sea un enfoque atractivo para modelar procesos generativos jerárquicos como se encuentran comúnmente en la biología de sistemas.
Ejemplo: DeepBind (Alipanahi et al. 2015)
DeepBind [1] es una herramienta de aprendizaje automático desarrollada por Alipanahi et al. para predecir las especificidades de secuencia de proteínas de unión a ADN y ARN utilizando métodos basados en el aprendizaje profundo.
Los autores señalan tres diferencias encontradas cuando se entrenan modelos de secuencia de especificidades sobre los grandes volúmenes de datos de secuencia producidos por tecnologías modernas de alto rendimiento: (a) los datos vienen en formas cualitativamente diferentes, incluyendo microarrays de unión a proteínas, ensayos RNACompete, ChIP- seq y HT -SELEX, (b) la cantidad de datos es muy grande (los experimentos típicos miden de diez a cien mil secuencias y (c) cada tecnología de adquisición de datos tiene sus propios formatos y perfil de error y por lo tanto se necesita un algoritmo que sea robusto a estos efectos no deseados.
El método DeepBind es capaz de resolver estas diferencias mediante (a) implementación paralela en una unidad de procesamiento gráfico, (b) tolerar un grado moderado de ruido y datos de entrenamiento mal clasificados y (c) entrenar el modelo predictivo de manera automática evitando la necesidad de afinación manual. Las siguientes figuras ilustran aspectos del pipeline Deep Bind.
Para abordar la preocupación por el sobreajuste, los autores utilizaron varios regularizadores, incluyendo deserción, decaimiento de peso y parada temprana.
Deserción: Prevención de Sobre-Ajuste
La deserción escolar [5] es una técnica para abordar el problema del sobreajuste en los datos de entrenamiento en el contexto de grandes redes. Debido a la multiplicación de gradientes en el cálculo de la regla de cadena, se coadaptan pesos unitarios ocultos, lo que puede conducir a un sobreajuste. Una forma de evitar la co-adaptación de pesos unitarios ocultos es simplemente soltar unidades (aleatoriamente). Una consecuencia beneficiosa de la caída de unidades es que las redes neuronales más grandes son más intensivas computacionalmente para entrenar.
No obstante, este enfoque toma un poco más de tiempo con respecto a la formación. Además, afinar el tamaño del paso es un desafío. Los autores proporcionan un Apéndice, en el que (en la parte (A)) proporcionan una útil “Guía práctica para formar redes de deserción escolar”. Señalan que los valores típicos para el parámetro dropout p (que
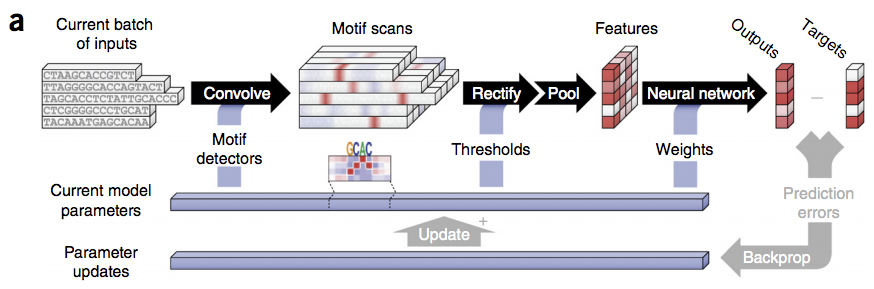
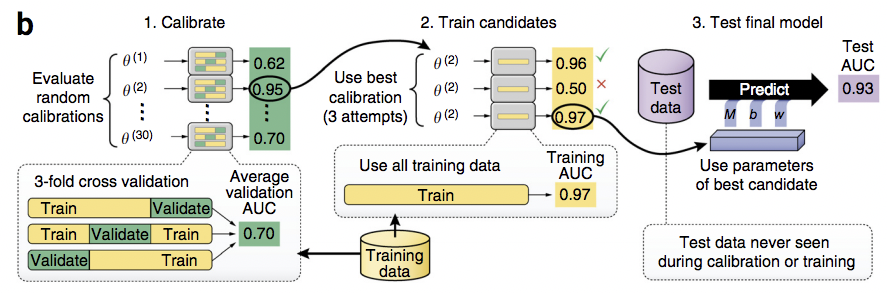
Cortesía de Macmillan Publishers Limited. Usado con permiso.
Fuente: Alipanahi, Babak, Andrew Delong, et al. “Predecir las especificidades de secuencia de
Proteínas de unión a ADN y ARN por Deep Learning”. Biotecnología de la naturaleza (2015)
determina la probabilidad de que se caiga un nodo) están entre 0.5 y 0.8 para las capas ocultas y 0.8 para las capas de entrada.