9.5: Ejercicio: hacer que ICA funcione mejor
- Última actualización
- Guardar como PDF
- Page ID
- 151906

Nuestro primer intento de corrección de parpadeo basada en ICA fue bastante simplista, y como resultado la descomposición no fue muy buena (como lo demuestran los mapas de cuero cabelludo de forma irregular para algunos de los CI en la captura de pantalla 9.2). La razón principal de esto es que nuestro conjunto de datos (como la mayoría de los conjuntos de datos de EEG) contiene alguna actividad realmente grande que es difícil de manejar para ICA porque es poco frecuente o carece de una distribución consistente en el cuero cabelludo (por ejemplo, potenciales de la piel). En este ejercicio, veremos un enfoque que minimizará los efectos de esas grandes fuentes de ruido y también hará que la descomposición se ejecute más rápido. ¡Es un ganar-ganar!
Hay varios pasos para hacer que la descomposición de ICA funcione mejor. Algunos de ellos se basan en un truco, que es crear un nuevo conjunto de datos en el que hemos eliminado señales que serán problemáticas para ICA, hacer la descomposición en este nuevo conjunto de datos y luego transferir los pesos ICA de nuevo al conjunto de datos original. Este enfoque fue polémico cuando escribí mi otro libro, así que no lo recomendé en el Capítulo 6 de Suerte (2014). Sin embargo, el campo ha convergido en gran medida en la idea de que este enfoque es a la vez teóricamente justificado y prácticamente útil.
Lo primero que vamos a hacer es filtrar fuertemente los datos, usando configuraciones de filtro que normalmente nunca usaría para experimentos ERP. Sin embargo, los datos filtrados se usarán solo para hacer la descomposición ICA, y luego transferiremos esos pesos ICA a los datos originales.
Por qué el filtrado pesado es correcto para la descomposición ICA
Los filtros cambian el curso temporal de un CI subyacente, pero no la distribución del cuero cabelludo, por lo tanto, el filtrado pesado es fino para los datos utilizados para la descomposición de ICA, porque solo nos importan las distribuciones del cuero cabelludo en esta etapa, no el momento. Una vez que tengamos los pesos IC, los transferiremos de nuevo a los datos originales sin la distorsión temporal causada por el filtrado.
Para comenzar, salga y reinicie EEGLAB y luego cargue el conjunto de datos original para Subject 10 (10_mmn_preprocessed). Seleccione EEGLAB > ERPLAB > Herramientas de filtro y frecuencia > Filtros para datos EEG, especificando un corte de paso alto de 1 Hz y un corte de paso bajo de 30 Hz, con una pendiente de 48 dB/octava. Ejecute la rutina y guarde el conjunto de datos resultante como 10_mmn_preprocessed_filt. Ahora hemos eliminado la mayoría de los potenciales cutáneos y EMG, los cuales pueden violar los supuestos de ICA e interferir con la descomposición.
Nuestro siguiente paso es reducir la muestra de los datos a 100 Hz. Esto solo hace que la descomposición ICA se ejecute más rápido (al igual que la reducción del ruido producido por el filtrado). Para ello, seleccione EEGLAB > Herramientas > Cambiar frecuencia de muestreo, ingrese 100 como la nueva frecuencia de muestreo y luego nombre el conjunto de datos resultante 10_mmn_preprocessed_filt_100Hz.
Lo siguiente que vamos a hacer para mejorar ICA es eliminar los segmentos de datos durante los descansos, cuando los participantes pueden estar moviéndose, rascándose la cabeza, masticando, etc. Los voltajes producidos por estas acciones suelen ser grandes pero no tienen una distribución consistente en el cuero cabelludo. EEGLAB le permite seleccionar y eliminar manualmente estos períodos de tiempo de un conjunto de datos continuo. ERPLAB agrega un procedimiento automatizado para ello. Simplemente encuentra periodos de tiempo sin ningún código de evento y los elimina. Vamos a darle una oportunidad.
Seleccione EEGLAB > ERPLAB > EEG de preproceso > Eliminar segmentos de tiempo (EEG continuo). En la ventana que aparece, especifique 1500 como Umbral de Tiempo. Esto le dice a la rutina que elimine segmentos en los que no haya códigos de evento durante al menos 1500 ms. Los códigos de evento en el experimento MMN ocurren cada ~500 ms, por lo que los periodos de 1500 ms sin código de evento deben ser descansos. Por supuesto, necesitarías usar un valor más largo para experimentos con una tasa más lenta de estímulos. También especifique 500 como la cantidad de tiempo anterior al primer código de evento en un bloque de ensayos. Esto asegurará que tengamos al menos 500 ms para el periodo basal del prestimulo para el primer evento en un bloque de ensayo. De igual manera, especificamos 1500 ms como el periodo de tiempo posterior al último código de evento en un bloque para que tengamos un buen periodo de datos siguiendo este código de evento.
Ingrese 1 en el campo para Excepciones de código de evento. Esto le dice a la rutina que ignore este código de evento. Nuestro programa de presentación de estímulos envió algunos códigos de eventos con un valor de 1 durante los descansos, y queremos que esos sean ignorados al buscar periodos de descanso. Del mismo modo, marque la casilla para ignorar eventos de límite. Los eventos límite ocurren siempre que hay una discontinuidad temporal en los datos. Más comúnmente, esto sucede cuando tienes un archivo de datos separado para cada bloque y luego los concatenas en un solo archivo. Al hacer esto, se inserta un evento de límite en el punto temporal de la transición entre un bloque y el siguiente. Los eventos de límite suelen ocurrir durante los descansos, por lo que queremos que se ignoren cuando buscamos largos periodos entre los códigos de eventos. Asegúrese de que el botón Mostrar EEG esté marcado y haga clic en EJECUTAR.
Luego verá dos nuevas ventanas, una para mostrar el conjunto de datos de EEG y otra para guardar el nuevo conjunto de datos. Si te desplazas por los datos, verás un fondo rojo durante los primeros ~25 segundos y los últimos ~3 segundos, que son los periodos de descanso al inicio y al final del bloque de prueba (solo tenemos un bloque de prueba en este experimento). Estos son los periodos de tiempo que se eliminarán. Siempre debes verificar que funcionó correctamente, y luego puedes guardar el nuevo conjunto de datos como 10_MMN_Preprocessed_Filt_100HZ_DEL.
Por último, vamos a lidiar con los malos canales. F7 y PO4 muestran un comportamiento loco en este conjunto de datos. Si los dejamos en los datos, terminaremos con un IC que apenas representa F7 y otro que apenas representa PO4. De hecho, puedes ver esto en nuestra descomposición ICA original en Screenshot 9.2, donde IC 3 solo representa el canal F7 e IC 17 solo representa el canal PO4. Vamos a interpolar estos canales eventualmente, entonces ¿por qué incluirlos en la descomposición ICA? Podríamos interpolarlos antes de la descomposición ICA, pero eso podría crear una dependencia lineal entre los canales que estropearía la descomposición. En su lugar, simplemente los excluiremos del proceso de descomposición ICA, y luego podremos interpolarlos después de que se complete la corrección de artefactos.
Ahora vamos a aplicar la descomposición ICA a este conjunto de datos seleccionando EEGLAB > Herramientas > Descomponer datos por ICA. Vamos a excluir los Canales 3 y 24 (los canales para F7 y PO4, respectivamente), y también vamos a excluir los Canales 32 y 33 (los canales bipolares EOG). Para ello, escriba 1 2 4:23 25:31 en el campo Tipo (s) de canal o índices. Como antes, asegúrese de usar runica como algoritmo ICA y que 'extended', 1 se especifica en el campo para opciones (consulte la documentación de ICA de EEGLAB para una explicación de esta opción). Después ejecuta la rutina. Si no quieres esperar a que termine, puedes simplemente cargar el conjunto de datos que creé después de ejecutar la descomposición, llamado 10_mmn_preprocessed_filt_100hz_del_icaweights.
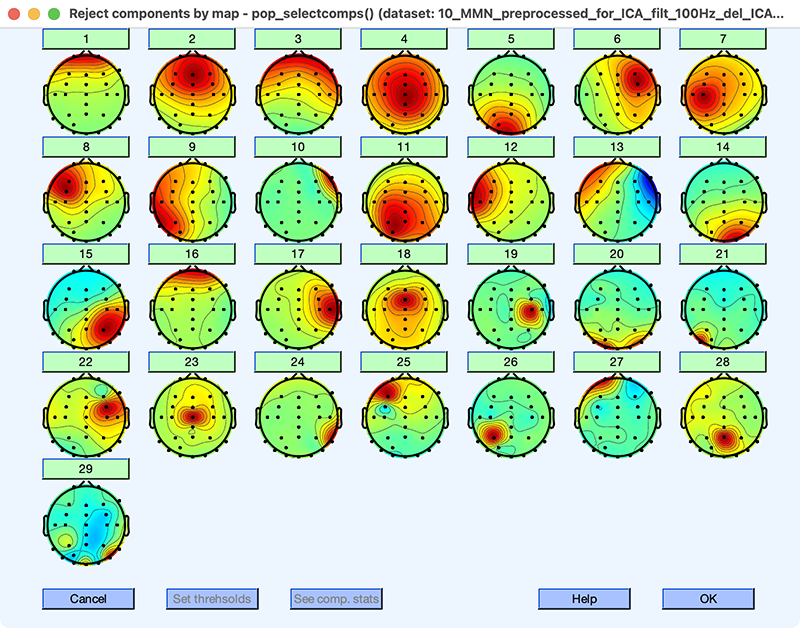
Una vez que tenga los pesos, puede ver los resultados con EEGLAB > Herramientas > Inspección/etiqueta componentes por mapa. El resultado que obtuve se muestra en la Captura de Pantalla 9.6 (sus resultados pueden diferir ligeramente, especialmente el orden y polaridad de los CI). Estos mapas son mucho más agradables que nuestros mapas originales (Captura de pantalla 9.2). Casi todos tienen un solo foco con una disminución en gran medida monótona (por ejemplo, IC 1 e IC 2) o una configuración bipolar (por ejemplo, IC 13 e IC 15). IC 20 tiene dos focos que son aproximadamente simétricos especulares a través de los hemisferios izquierdo y derecho, lo que también es un patrón perfectamente normal (y surge cuando los dos hemisferios operan sincrónicamente). El único mapa irregular es para IC 29. Debido a que los mapas están ordenados de acuerdo a la cantidad de varianza que explican, no debes preocuparte si el último par de mapas no son perfectos.
Captura 9.6