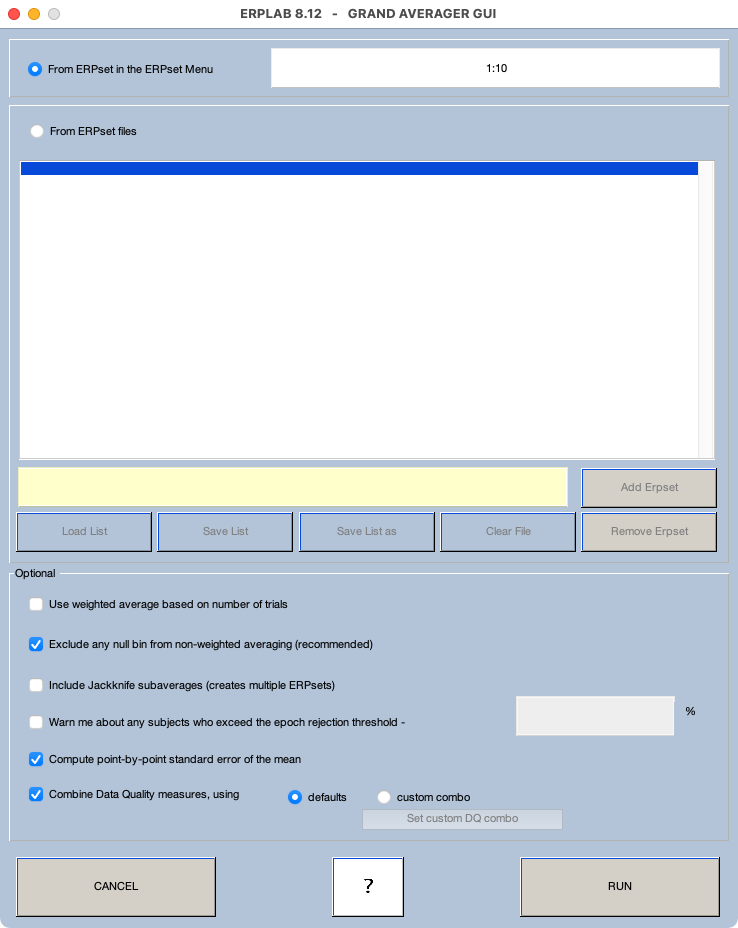
Aunque es importante observar las formas de onda ERP de un solo participante, será más fácil ver efectos sutiles promediando las formas de onda entre los participantes para crear formas de onda de gran promedio para cada bin. Para hacer esto, asegúrese de que los ERPSets de los 10 participantes estén cargados (que puede verificar mirando el menú ERPSets), y luego seleccione EEGLAB > ERPLAB > Promedio a través de ERPSets (Gran Promedio). Se abrirá una nueva ventana que parece algo así como Captura de pantalla 3.3.
Captura de pantalla 3.3
Es necesario especificar qué ERPSets se promediarán juntos. Puede hacerlo especificando un conjunto de ERPSets que ya se han cargado (usando los números ERPSet en el menú ERPSets) o especificando los nombres de archivo para ERPsets que se han almacenado en archivos. En este ejercicio, especificaremos los ERPSets que ya se han cargado. Si solo tienes los 10 ERPSets de nuestros 10 participantes de ejemplo en tu menú ERPSets, puedes especificar 1:10 (como en la Captura de Pantalla 3.3). En Matlab, se puede indicar una lista de números consecutivos proporcionando los números primero y último, separados por dos puntos. Entonces, 1:10 es igual a 1 2 3 4 5 6 7 8 9 10. Si estos no son los ERPsets correctos (porque tienes otros también cargados en ERPLAB), solo proporciona una lista de los diez números para los ERPSets que quieres promediar juntos.
Puede dejar las otras opciones establecidas en sus valores predeterminados (asegurándose de que coincidan con la Captura de pantalla 3.3). Después haga clic en EJECUTAR Luego verá la ventana habitual para guardar el nuevo ERPset que ha creado. Denle el nombre Grand_N400 (y guárdalo como archivo para que lo tengas para los ejercicios posteriores). Ahora deberías ver Grand_N400 en el menú ERPSets.
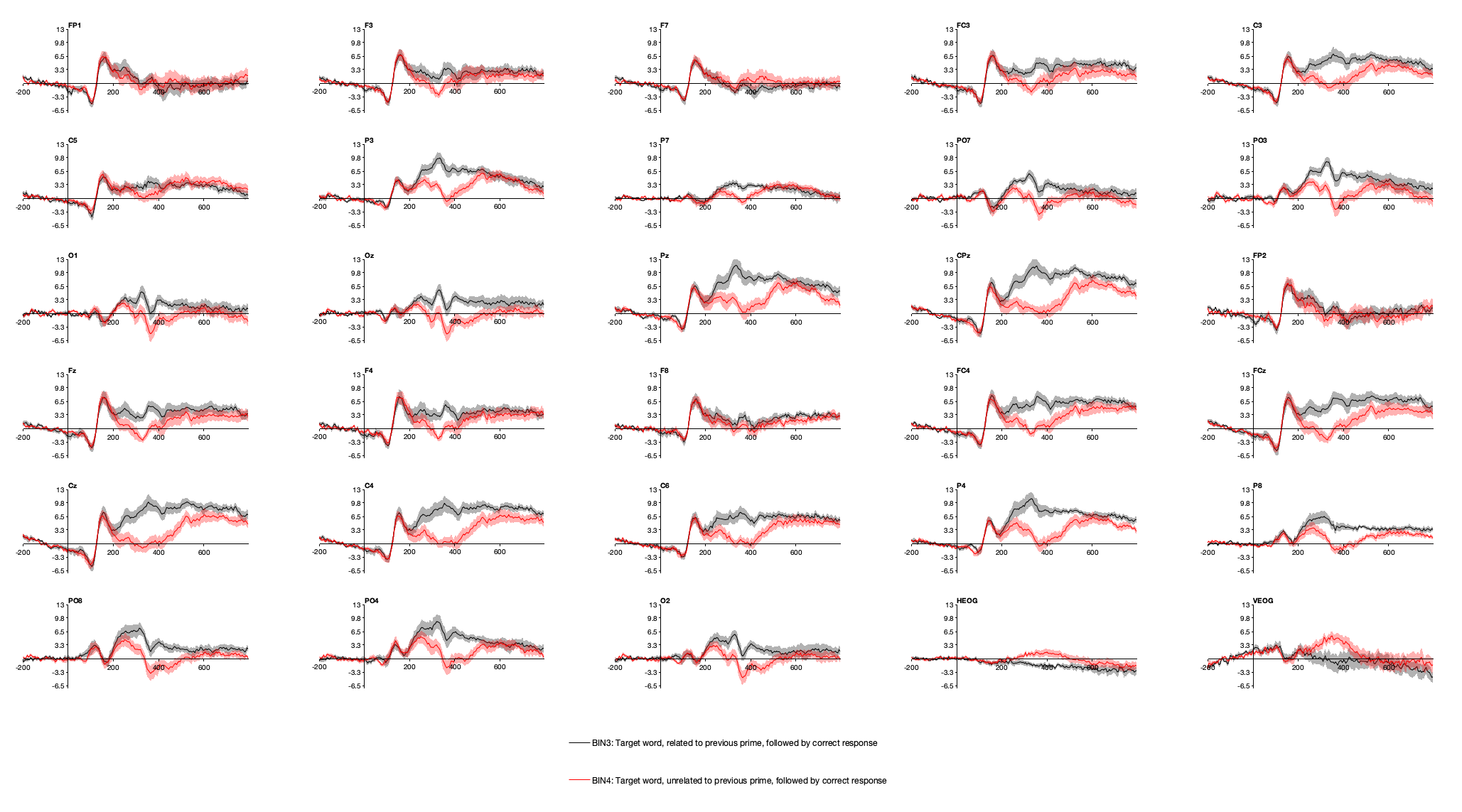
Ahora, grafique los ERPs de los Bins 3 y 4 (usando EEGLAB > ERPLAB > Trazar ERPs > Trazar formas de onda ERP). Pero agreguemos algo nuevo: Marque la casilla etiquetada show standard error (y asegúrate de que el nivel de transparencia esté establecido en 0.7). Debería ver algo como Captura de pantalla 3.4, con un voltaje más negativo para los objetivos no relacionados que para los objetivos relacionados en CPz y sitios de electrodos circundantes. El sombreado de luz alrededor de las formas de onda es el error estándar de la media en cada punto de tiempo (consulte el cuadro a continuación para obtener más información).
Captura de pantalla 3.4
Ahora parcela Bins 1 y 2. Las formas de onda para estos contenedores deben estar acostadas una encima de la otra, siendo las diferencias pequeñas en relación con el SEM. Recuerde, estos son los bins para primos que son seguidos por objetivos relacionados versus no relacionados, y a menos que los participantes tengan ESP, no pueden diferir en función de algo que sucede después. Como resultado, cualquier diferencia entre ellos es simplemente el resultado del ruido.
Por último, eche un vistazo a los valores de calidad de datos de ASMe para el promedio general (EEGLAB > ERPLAB > Opciones de calidad de datos > Mostrar medidas de calidad de datos en una tabla). Cuando hiciste el gran promedio, la configuración predeterminada provocó que los valores ASMe de los participantes individuales se combinaran usando algo llamado la raíz cuadrada media (RMS). Esto es como tomar el promedio del ASMe de un solo participante, excepto que el valor RMS está más directamente relacionado con el impacto de la calidad de los datos de cada participante con el tamaño del efecto (ver Luck et al., 2021). Estos valores ASMe son como un error estándar, pero son el error estándar del voltaje medio en una ventana de tiempo de 100 ms en lugar del SEM en un solo punto de tiempo (vea el cuadro a continuación). Si observa la tabla de valores de ASMe, verá que los valores en el rango de tiempo N400 están alrededor de 1.5 µV. Eso es razonablemente pequeño en relación con la gran diferencia en el voltaje medio entre los objetivos no relacionados y relacionados. En otras palabras, la calidad de los datos es bastante buena para nuestro objetivo de detectar diferencias entre estos dos tipos de objetivos.
Trazando el error estándar
Trazar el error estándar de la media (SEM) en cada punto temporal en una forma de onda ERP, como en la Captura de Pantalla 3.4, puede ser útil para evaluar si las diferencias entre condiciones son razonablemente grandes en relación con la variabilidad entre los participantes. Estos valores de error estándar son como las barras de error que podrías ver en un gráfico de barras. En cada punto temporal, la forma de onda ERP promedio es simplemente la media de los valores de voltaje entre los participantes en ese momento. El SEM es solo la desviación estándar (DE) de los valores de un solo participante dividida por la raíz cuadrada del número de participantes (que es exactamente como suele calcularse el SEM en otros contextos).
También puede ver el SEM cuando traza las formas de onda ERP promediadas de un solo participante. En este caso, la forma de onda muestra la media entre los ensayos en lugar de la media entre los participantes, y el SEM refleja la variabilidad entre los ensayos en lugar de la variabilidad entre los puntos de tiempo.
Aunque el SEM puede ser útil, tiene algunas desventajas. Primero, imagine que el voltaje a 400 ms es exactamente 3 µV más negativo para objetivos no relacionados que para objetivos relacionados en cada participante (es decir, el efecto experimental es extremadamente consistente entre los participantes). Pero imagínese que el voltaje general a 400 ms es mucho más positivo en algunos participantes que en otros, lo que lleva a bastante variabilidad en el voltaje para cada condición. Debido a esta variabilidad, el SEM para cada forma de onda sería bastante grande a 400 ms. Esto haría que pareciera que la diferencia de medias entre condiciones era pequeña en relación con el SEM, a pesar de que la diferencia para cada participante fue sumamente consistente. En la investigación conductual, este problema se aborda mediante el SEM dentro de los sujetos (Cousineau, 2005; Morey, 2008). ERPLAB no tiene esta versión del SEM incorporada, pero se puede lograr el mismo resultado haciendo una onda de diferencia entre las condiciones (por ejemplo, objetivos no relacionados menos objetivos relacionados) y obteniendo el SEM de la onda de diferencia. Esto es exactamente lo que se hizo en los grandes promedios del estudio completo (ver Figura 2.1C en el Capítulo 2).
Otra desventaja del SEM es que puede ser muy grande si hay mucho ruido de alta frecuencia en los datos, a pesar de que este ruido tiene un impacto mínimo cuando cuantificamos el N400 como el voltaje medio entre 300 y 500 ms (como haremos más adelante en este capítulo). El valor ASMe proporcionado en nuestras medidas de Calidad de Datos no tiene esta desventaja, ya que proporciona el error estándar de la tensión media durante un período de tiempo en lugar del error estándar de los valores en puntos de tiempo individuales. Ver Luck et al. (2021) para una discusión más detallada.