Ahora vamos a realizar un simple análisis estadístico de las puntuaciones de amplitud N400 que obtuviste en el ejercicio anterior. Tenemos dos puntuaciones de amplitud para cada participante, una para objetivos relacionados y otra para objetivos no relacionados, y queremos saber si las puntuaciones son significativamente diferentes para estas dos condiciones experimentales. La forma más sencilla de hacerlo es con una prueba t pareada.
Utilicé el paquete estadístico JASP gratuito para ejecutar la prueba t, pero puedes usar cualquier paquete que te resulte cómodo. Asegúrese de especificar una prueba t pareada en lugar de una prueba t de muestras independientes. Los resultados se muestran en la Captura de Pantalla 3.8. Antes de mirar los valores t y p, siempre debe mirar las estadísticas descriptivas. Una vez que lleguemos a análisis más complejos, será muy fácil cometer errores en el análisis estadístico. El error más común es especificar incorrectamente qué variable se encuentra en qué columna del archivo de datos. Por ejemplo, podría pensar que los objetivos no relacionados y relacionados se almacenan en la primera y segunda columnas, respectivamente, invirtiendo el orden real. Este tipo de error se vuelve más probable y más probable de llevar a conclusiones incorrectas cuando su diseño tiene varios factores y cada fila del archivo de datos tiene una docena o más columnas. Al comparar las medias grupales desde el análisis estadístico hasta las formas de onda de gran promedio, a menudo se pueden detectar estos errores.
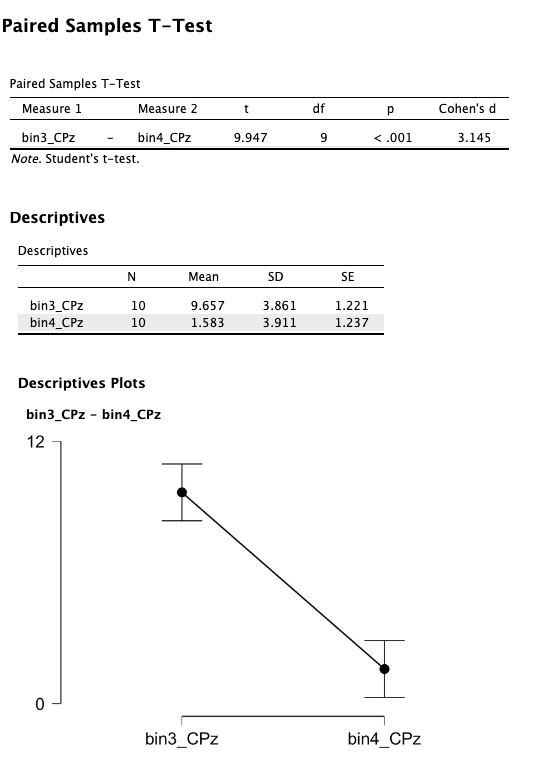
Captura de pantalla 3.8
Si observa las medias de grupo en la Captura de Pantalla 3.8, verá una media de 9.657 µV para los objetivos relacionados (Bin 3) y 1.583 µV para los objetivos no relacionados (Bin 4). Esos valores coinciden al menos aproximadamente con lo que puede ver para el canal CpZ de 300-500 ms en las formas de onda de gran promedio que se muestran en la Captura de Pantalla 3.4.
Ahora que hemos verificado que las estadísticas descriptivas parecen correctas, podemos observar los valores t y p. El efecto fue significativo en el nivel p < .001 y el tamaño del efecto (d de Cohen) fue enorme. El tamaño del efecto de 3.145 indica que la diferencia entre las medias grupales para objetivos relacionados y no relacionados fue 3.145 veces mayor que la desviación estándar de las puntuaciones. No encontrarás efectos tan grandes en la mayoría de los experimentos, pero el experimento N400 ERP CORE fue cuidadosamente diseñado para maximizar los efectos experimentales, y elegimos un paradigma que se sabía que producía efectos grandes. Además, elegí 10 participantes con efectos muy claros para los ejercicios de este capítulo; el tamaño del efecto era “solo” 2.33 en la muestra completa de 40 participantes (pero este seguía siendo un tamaño de efecto enorme).
Límites para comparar estadísticas descriptivas con formas de onda de gran promedio
Cuando puntuamos la amplitud de un componente ERP como voltaje medio en una ventana de tiempo fija, podemos comparar directamente los valores medios grupales del análisis estadístico con las formas de onda ERP de gran promedio. Esto se debe a que este método de puntuación es una operación lineal (para una definición y más información, consulte el Apéndice en Luck, 2014). El orden de las operaciones no importa para las operaciones lineales. Esto significa que podemos obtener nuestra puntuación de amplitud media a partir de las formas de onda de un solo sujeto y luego calcular la media de estas puntuaciones, y obtendremos exactamente el mismo valor que obtendríamos al anotar la amplitud media a partir de la forma de onda de gran promedio.
Desafortunadamente, la mayoría de los otros métodos de puntuación no son lineales. Por ejemplo, la amplitud máxima en una ventana de tiempo dada no es lineal. Si obtenemos la amplitud máxima a partir de las formas de onda de un solo sujeto y luego calculamos la media de estas puntuaciones, el resultado no será el mismo que la amplitud máxima de la forma de onda de gran promedio. Sin embargo, aún debe comparar las medias grupales de su análisis estadístico con las formas de onda de gran promedio. Si hay un gran desajuste, entonces es posible que haya cometido un error al especificar el orden de las variables en su análisis estadístico, o su forma de onda de gran promedio puede no representar adecuadamente lo que está sucediendo en el nivel de un solo sujeto. En cualquier caso, ¡quieres saber!