Ahora vamos a cuantificar estos efectos y luego ver si son estadísticamente significativos. En este ejercicio, tomaremos el enfoque que muchos estudios (incluido el mío) utilizaron hace muchos años pero que se ha vuelto menos común a medida que la gente descubrió un enfoque que es a la vez más simple y mejor. Comenzaremos con el enfoque obsoleto porque eso le permitirá ver mejor (a) por qué es mejor el enfoque más nuevo y (b) cómo el enfoque más nuevo proporciona información equivalente sobre las preguntas clave.
Comencemos puntuando la amplitud LRP de las formas de onda ERP de cada participante. Hay muchas formas diferentes de puntuar la amplitud o latencia de un componente ERP, como se describe en detalle en el Capítulo 9 de la Suerte (2014). En la mayoría de los casos, la amplitud media es la mejor manera de cuantificar las amplitudes ERP. En el presente ejercicio mediremos la amplitud media de 200-250 ms. Esto solo significa que la rutina de puntuación sumará los valores de voltaje para cada punto de tiempo en este rango de latencia y luego se dividirá por el número de puntos de tiempo. ¡Así de simple! La simplicidad de la amplitud media significa que es muy fácil de entender e incluso hacer pruebas matemáticas sobre, y tiene algunas propiedades muy bonitas que veremos a medida que avanzamos en los próximos ejercicios.
Uno de los temas más importantes involucrados en la puntuación de los ERPs es la elección de la ventana de tiempo. Elegí 200-250 ms para este ejercicio porque este es el rango de tiempo aproximado en el que normalmente se ve el efecto de polaridad opuesta para ensayos incompatibles.
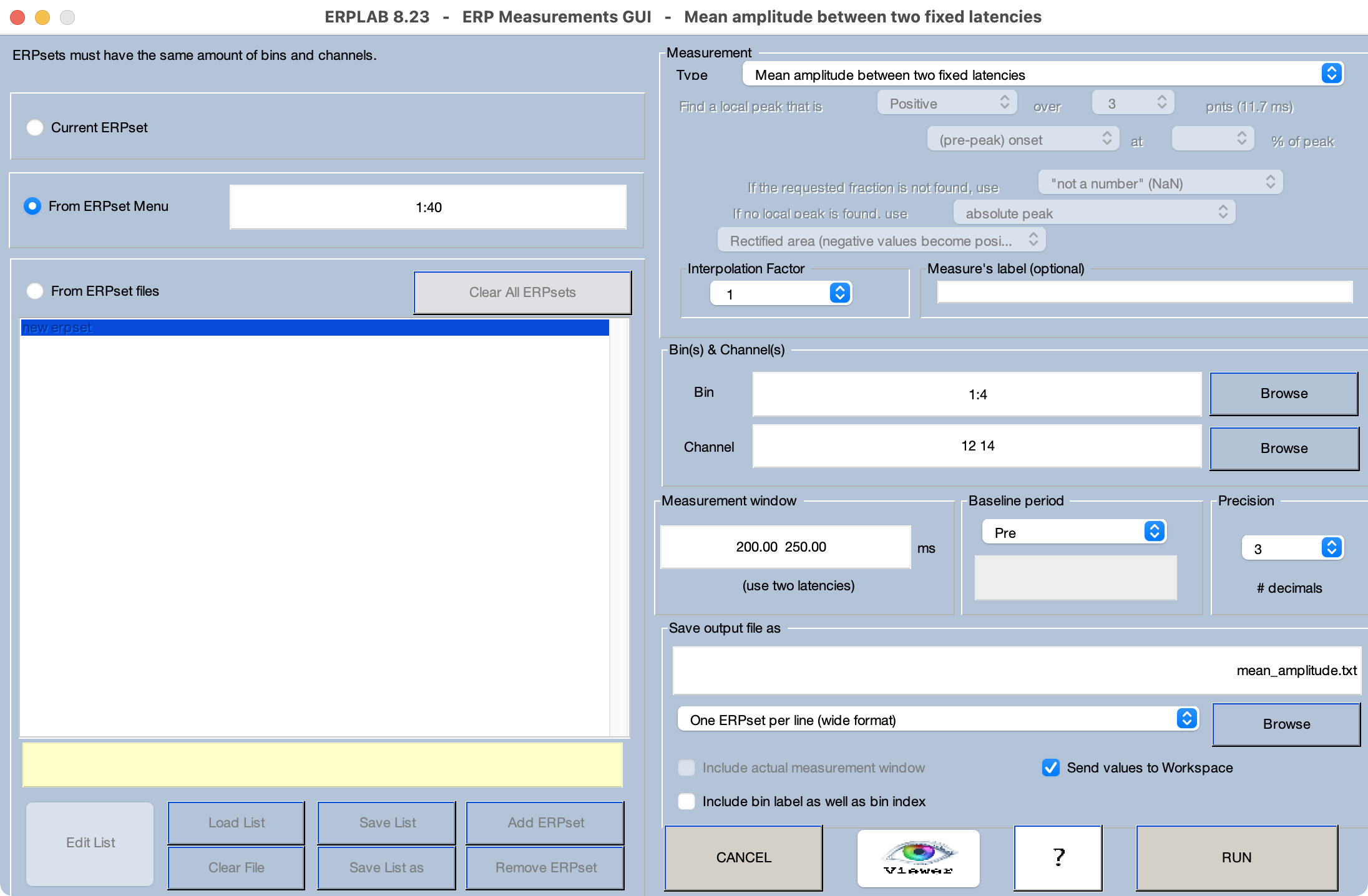
Salga y reinicie EEGLAB, asegúrese de que Chapter_10 sea la carpeta actual de Matlab y luego cargue los 40 ERPSets desde la carpeta Chapter_10 > Data > ErpSETS_CI. Luego seleccione EEGLAB > ERPLAB > ERP Measurement Tool e ingrese los parámetros que se muestran en la Captura de Pantalla 10.1. El lado izquierdo de la GUI se utiliza para indicar qué ERPSets deben ser puntuados. Vamos a medir a partir de los 40 ERPSets que acabas de cargar. El lado derecho de la GUI controla el algoritmo de puntuación. Especificarás que el algoritmo básico es Amplitud media entre dos latencias fijas, e indicarás que las latencias de inicio y detención son 200 250. Esta es la ventana de medición. Vamos a medir desde los canales C3 y C4 (12 14) en los cuatro bins (1:4). Vamos a guardar las partituras en un archivo de texto llamado mean_amplitude.txt.
Captura de pantalla 10.1
Es realmente tentador presionar el botón RUN y obtener las puntuaciones, pero siempre debes verificar primero las mediciones con las formas de onda ERP. Puedes hacer esto haciendo clic en el botón Visor. Se abrirá la herramienta Visor, y verás la forma de onda ERP desde el primer bin y el primer canal en el primer ERPSet. La ventana de medición está indicada por la región amarilla, y el valor producido por el algoritmo de puntuación (5.628 µV) se muestra en la ventana en la parte inferior.
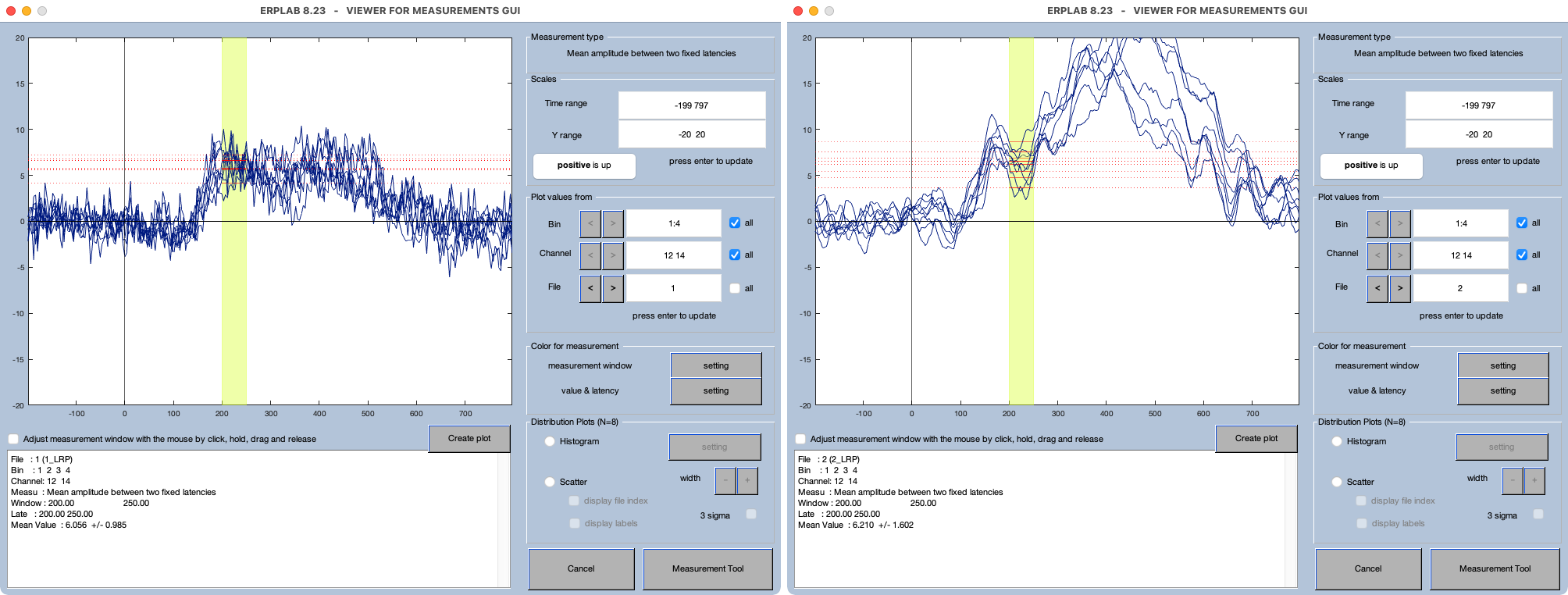
Luego puede recorrer los diferentes bins, canales y ERPSets para verificar que el algoritmo funcione de manera sensata. Puede que le resulte conveniente observar múltiples formas de onda por pantalla. En los dos casos mostrados en la Captura de Pantalla 10.2, por ejemplo, hice clic en el cuadro all para Bin y Channel para superponer los dos bins y los dos canales.
No mucho puede salir mal con el algoritmo para medir la amplitud media, pero puede encontrar puntuaciones sorprendentes y problemáticas para algunos participantes cuando usa otros algoritmos (por ejemplo, amplitud pico o latencia máxima). Incluso con la amplitud media, es humilde e informativo ver cuánto varían las formas de onda ERP entre los participantes. Por ejemplo, el participante de la derecha en la Captura de Pantalla 10.2 tiene formas de onda que son similares a las del promedio general (Figura 10.2) —con picos distintos P2, N2 y P3— y la ventana de medición atraviesa el pico N2. Por el contrario, el participante de la izquierda no tiene picos muy distintos, y la ventana de medición se encuentra en el momento de un pico positivo.
Captura 10.2
Esto trae a colación un punto importante sobre las ERPs (y la mayoría de los otros métodos utilizados en las ciencias de la mente y del cerebro): Los promedios son una ficción conveniente. Las formas de onda ERP que obtenemos promediando juntas múltiples épocas de ensayo único pueden no ser una buena representación de lo que sucedió en los ensayos individuales, y una forma de onda de gran promedio entre los participantes puede no ser una buena representación de los participantes individuales. Sin embargo, es difícil evitar promediar (o métodos que son generalizaciones de la misma idea subyacente, como la regresión). Los capítulos 2 y 8 de Luck (2014) discuten este tema con más detalle.
Una vez que haya terminado de escanear todas las formas de onda ERP usando el Visor, haga clic en el botón Herramienta de medición para volver a la Herramienta de medición y luego haga clic en EJECUTAR para obtener las puntuaciones. Suponiendo que Chapter_10 sigue siendo la carpeta actual en Matlab, ahora debería estar presente un archivo llamado mean_amplitude.txt en la carpeta Chapter_10. Haga doble clic en este archivo en el panel Carpeta actual de Matlab para abrirlo en el editor de texto de Matlab. Verás que consiste en un conjunto de columnas separadas por tabuladores. El editor de texto de Matlab no maneja muy bien las pestañas, por lo que es posible que los encabezados de las columnas no se alineen correctamente. Recomiendo abrirlo en cambio en un programa de hoja de cálculo como Excel. Así es como deberían verse las primeras líneas:
Bin1_c3
BIN1_C4
Bin2_c3
Bin2_C4
Bin3_c3
Bin3_C4
Bin4_c3
Bin4_c4
ERPset
5.628
4.124
6.818
5.741
6.623
5.66
7.247
6.607
1_LRP
6.902
7.534
4.72
8.7
3.629
6.546
6.178
5.47
2_LRP
3.149
5.122
1.19
1.962
4.361
4.309
4.441
4.638
3_LRP
Cada fila contiene los datos de un participante, y cada columna contiene la puntuación (valor de amplitud media) para una combinación bin/canal para ese participante. La Herramienta de Medición también puede generar las mediciones en un formato “largo” en el que cada partitura está en una línea separada. Este formato largo es particularmente bueno para usar tablas dinámicas para resumir los datos en Excel, y funciona bien con algunos paquetes estadísticos. El formato “ancho” que se muestra en la tabla anterior es ideal para paquetes estadísticos en los que se espera que todos los datos de un participante determinado estén en una sola fila (por ejemplo, SPSS, JASP).
Ahora que tenemos los puntajes, hagamos un análisis estadístico utilizando un ANOVA tradicional. Puedes usar cualquier paquete estadístico que te guste. Como mencioné anteriormente, te recomiendo JASP si aún no tienes un paquete que pueda hacer pruebas t básicas y ANOVA dentro de sujetos.
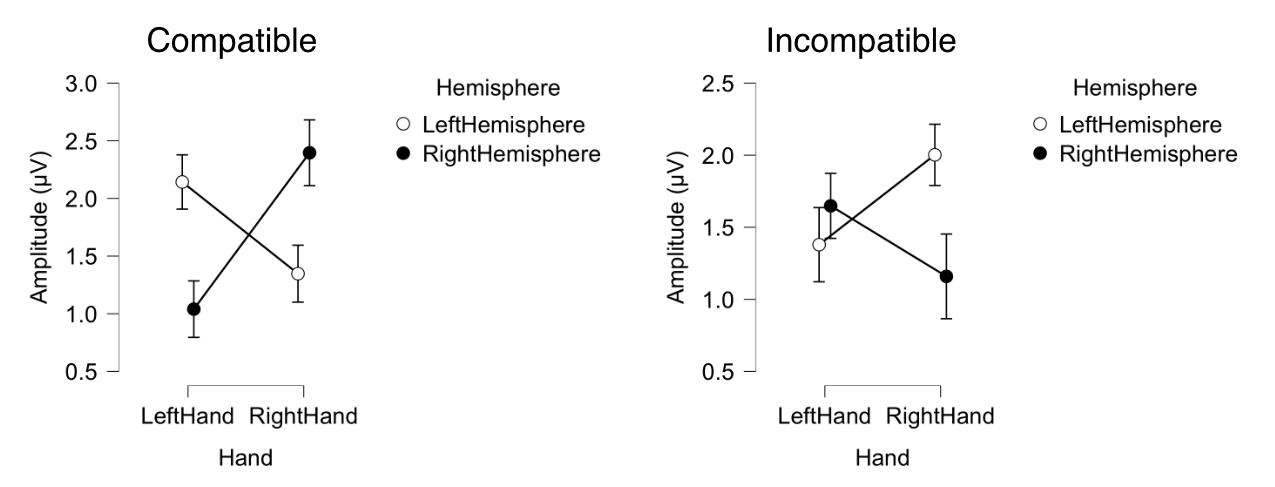
El ANOVA debe tener tres factores dentro de los sujetos, cada uno con dos niveles: Hemisferio de Electrodo (izquierdo o derecho), Mano de Respuesta (izquierda o derecha) y Compatibilidad (Compatible o Incompatible). Cuando carga los datos en su software estadístico y especifica las variables, es muy fácil obtener las columnas en el orden equivocado. Por lo tanto, su primer paso en el análisis estadístico debe ser examinar la tabla o gráfica de las estadísticas descriptivas proporcionadas por su software estadístico para que pueda asegurarse de que los datos se organizaron correctamente. La Figura 10.3 muestra lo que obtuve en JASP.
Figura 10.3. Medias de cada celda del diseño, obtenidas con JASP. Las barras de error muestran el error estándar de la media en cada celda.
Pero, ¿cómo sabes cuáles deben ser los valores correctos? Resulta que con las puntuaciones de amplitud media (pero no la mayoría de las otras puntuaciones), se obtiene el mismo resultado promediando las puntuaciones de un solo sujeto y obteniendo las puntuaciones de las formas de onda de gran promedio (ver el Apéndice en Luck, 2014 para más detalles). Cargue el promedio general que creó anteriormente (grand.erp) y vuelva a ejecutar la Herramienta de medición, pero especificando que debe medir solo a partir de este ERPSet y guardar los resultados en un archivo llamado mean_amplitude_grand.txt. A continuación, se pueden comparar esos números con los valores de la tabla o figura de la estadística descriptiva. Aquí están los valores que obtuve:
Bin1_c3
BIN1_C4
Bin2_c3
Bin2_C4
Bin3_c3
Bin3_C4
Bin4_c3
Bin4_c4
ERPset
2.143
1.04
1.348
2.396
1.379
1.649
2.002
1.159
grandioso
Estos valores coinciden exactamente con las medias mostradas en la Figura 10.3. ¡Éxito! Tenga en cuenta que si usa algún otro algoritmo de puntuación (por ejemplo, amplitud máxima) en sus propios estudios, los valores no coincidirán exactamente. Sin embargo, al menos puedes asegurarte de que el patrón sea el mismo.
¡Este proceso de verificación es muymuy muy importante! Estimo que encontrarás un error al menos el 10% del tiempo si tienes tres o más factores en tu diseño.
Antes de mirar las estadísticas inferenciales, pensemos qué efectos principales e interacciones esperaríamos ver. Primero considere la condición Compatible, en la que el voltaje debería ser más negativo para el hemisferio contralateral que para el hemisferio ipsilateral. Esto nos da un voltaje más negativo para las respuestas de la izquierda que para las respuestas de la derecha sobre el hemisferio derecho, y el patrón inverso sobre el hemisferio izquierdo. Es decir, la presencia de la LRP es capturada en el ANOVA como una interacción entre Hemisferio y Mano. Durante este periodo de tiempo de 200-250 ms, esperamos ver un efecto contrario para los ensayos incompatibles (porque el voltaje es más negativo sobre el hemisferio contralateral a la respuesta incorrecta, lo que lo hace más positivo contralateral a la respuesta correcta). En consecuencia, la diferencia entre los ensayos Compatible e Incompatible debería conducir a una interacción de tres vías entre Compatibilidad, Hemisferio y Mano.
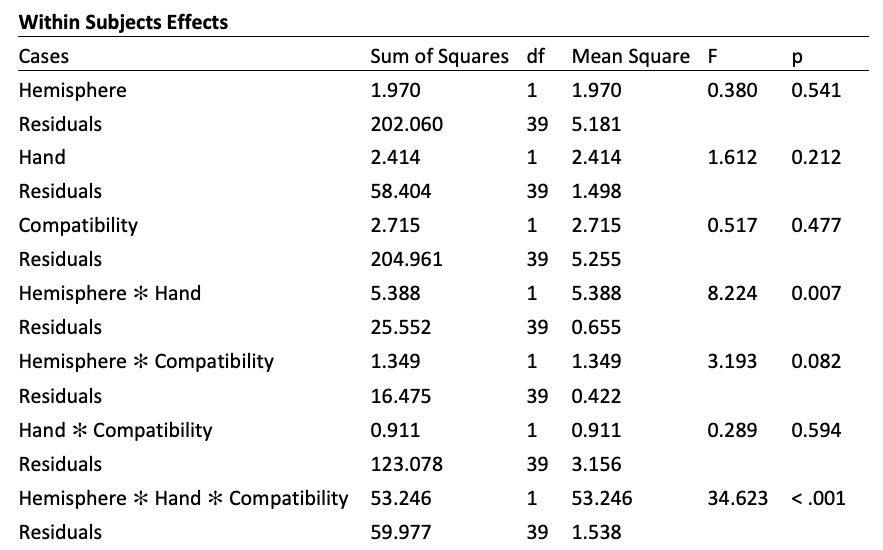
En el Cuadro 10.1 se muestran los estadísticos inferenciales I obtenidos de JASP. Se puede ver que los principales efectos de Mano y Hemisferio no son significativos, consistente con el hecho de que la Figura 10.3 muestra poca o ninguna diferencia general entre las respuestas izquierda y derecha o entre los hemisferios izquierdo y derecho. El efecto principal de Compatibilidad tampoco es significativo, consistente con el hecho de que el voltaje promedio a través de las celdas para la condición Compatible fue aproximadamente el mismo que el voltaje promedio entre celdas para la condición Incompatible.
Por el contrario, la interacción entre Hemisferio y Mano fue significativa. Esta interacción equivale a preguntar sobre la contralateralidad del voltaje si promediamos a través de ensayos compatibles e incompatibles. Estas dos condiciones produjeron efectos de dirección opuesta que se cancelan parcialmente entre sí. Sin embargo, la negatividad contralateral para los ensayos compatibles fue mayor que la positividad contralateral para los ensayos Incompatibles, y esto nos da una interacción global significativa. Pero esta interacción no tiene sentido en el mejor de los casos y engañosa en el peor, porque los patrones fueron opuestos para los ensayos Compatible e Incompatible, como lo indica la significativa interacción de tres vías entre Hemisferio, Mano y Compatibilidad. Este tipo de complicaciones es una de las razones por las que muchos investigadores han dejado de usar este enfoque y han pasado al enfoque más simple descrito en el siguiente ejercicio.
Cuadro 10.1. Estadística inferencial de JASP.
El siguiente paso en nuestro análisis estadístico sería realizar contrastes específicos para que podamos ver, por ejemplo, si la interacción Hemisferio x Mano es significativa cuando los ensayos Compatible e Incompatible se analizan por separado. No obstante, no vamos a dar ese siguiente paso, porque esta forma de analizar los datos es menos que ideal. Primero, el tamaño del LRP es capturado por la interacción Hemisferio x Mano en lugar de un efecto principal, lo que dificulta la comprensión de las cosas. En segundo lugar, este enfoque genera muchos valores de p, lo que significa que la probabilidad de que obtengamos uno o más efectos bogus pero significativos es bastante alta. Si ejecuta un ANOVA de tres vías, obtiene 7 valores p (como se muestra en la Tabla 10.1), y tendrá aproximadamente un 30% de probabilidad de obtener al menos un efecto bogus-pero-significativo (si la hipótesis nula es realmente cierta para todos los 7 efectos). Entonces, es importante minimizar el número de factores en tus análisis (ver Luck & Gaspelin, 2017 para una discusión detallada de este tema). El siguiente ejercicio te mostrará un mejor enfoque.
Efectos Bogus
Cuando un efecto en los datos es solo resultado de una variación aleatoria y no refleja un efecto verdadero en la población, me gusta referirme a ese efecto como falso. Y si el efecto es estadísticamente significativo, me refiero a él como un efecto bogus-pero-significativo. El término técnico para esto es un error de Tipo I. Pero esa es una forma seca, abstracta y difícil de recordar de describir una conclusión incorrecta que podría estar permanentemente grabada en la literatura científica.