
13.1: La prueba z de una muestra
- Page ID
- 151818

En esta sección voy a describir una de las pruebas más inútiles en todas las estadísticas: la prueba z. En serio — esta prueba casi nunca se usa en la vida real. Su único propósito real es que, al enseñar estadística, sea un paso muy conveniente en el camino hacia la prueba t, que es probablemente la herramienta más (más) utilizada en todas las estadísticas.
problema de inferencia que aborda la prueba
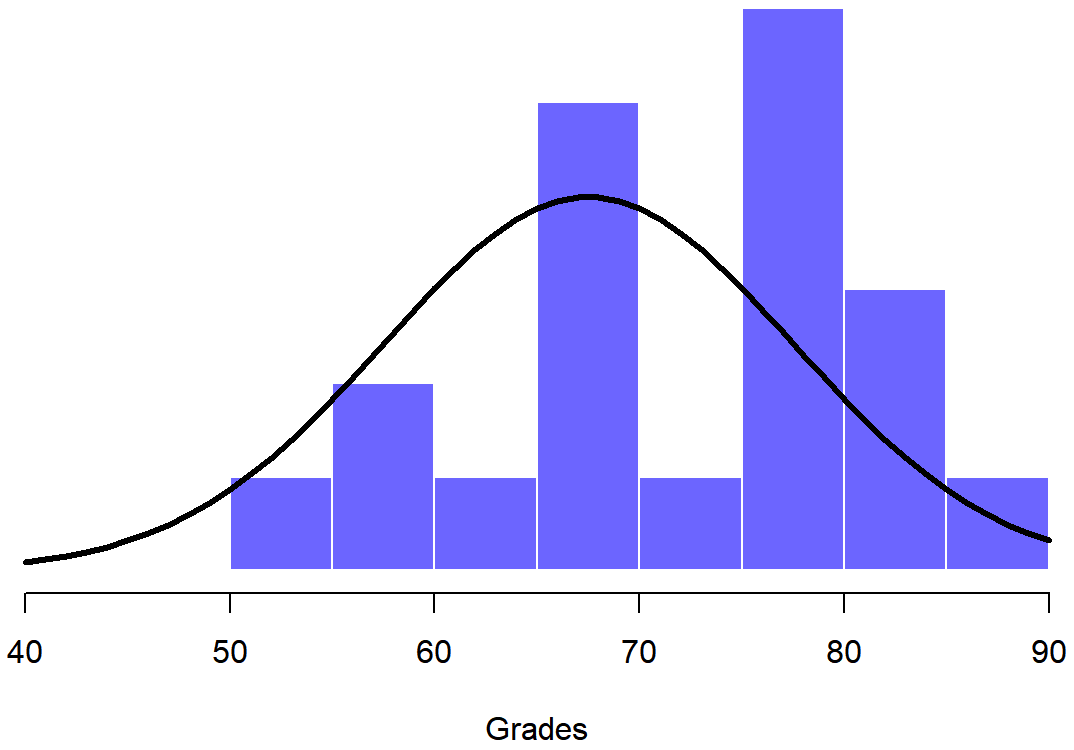
Para introducir la idea detrás de la prueba z, usemos un ejemplo sencillo. Un amigo mío, el Dr. Zeppo, califica su clase introductoria de estadística en una curva. Supongamos que la nota promedio en su clase es de 67.5, y la desviación estándar es 9.5. De sus muchos cientos de alumnos, resulta que 20 de ellos también toman clases de psicología. Por curiosidad, me encuentro preguntándome: ¿los estudiantes de psicología tienden a obtener las mismas calificaciones que todos los demás (es decir, significan 67.5) o tienden a obtener calificaciones más altas o menores? Me envía por correo electrónico el archivo Zeppo.rdata, que utilizo para sacar las calificaciones de esos alumnos,
load( "./rbook-master/data/zeppo.Rdata" )
print( grades )## [1] 50 60 60 64 66 66 67 69 70 74 76 76 77 79 79 79 81 82 82 89y calcular la media:
mean( grades )## [1] 72.3Hm. Podría ser que los estudiantes de psicología estén puntuando un poco más alto de lo normal: esa media muestral de\(\bar{X}\) = 72.3 es un poco más alta que la media poblacional hipotética de μ=67.5, pero por otro lado, un tamaño muestral de N=20 no es tan grande. A lo mejor es pura casualidad.
Para responder a la pregunta, ayuda poder anotar qué es lo que creo que sé. En primer lugar, sé que la media muestral es\(\bar{X}\) =72.3. Si estoy dispuesto a asumir que los estudiantes de psicología tienen la misma desviación estándar que el resto de la clase entonces puedo decir que la desviación estándar de la población es σ=9.5. También asumiré que dado que el Dr. Zeppo está calificando a una curva, las calificaciones de los estudiantes de psicología normalmente se distribuyen.
A continuación, ayuda tener claro lo que quiero aprender de los datos. En este caso, mi hipótesis de investigación se relaciona con la media poblacional μ para las calificaciones de los estudiantes de psicología, lo cual se desconoce. Específicamente, quiero saber si μ=67.5 o no. Dado que esto es lo que sé, ¿podemos idear una prueba de hipótesis para resolver nuestro problema? Los datos, junto con la distribución hipotética de la que se piensa que surgen, se muestran en la Figura 13.1. No del todo obvio cuál es la respuesta correcta, ¿verdad? Para ello, vamos a necesitar algunas estadísticas.
Construyendo la prueba de hipótesis
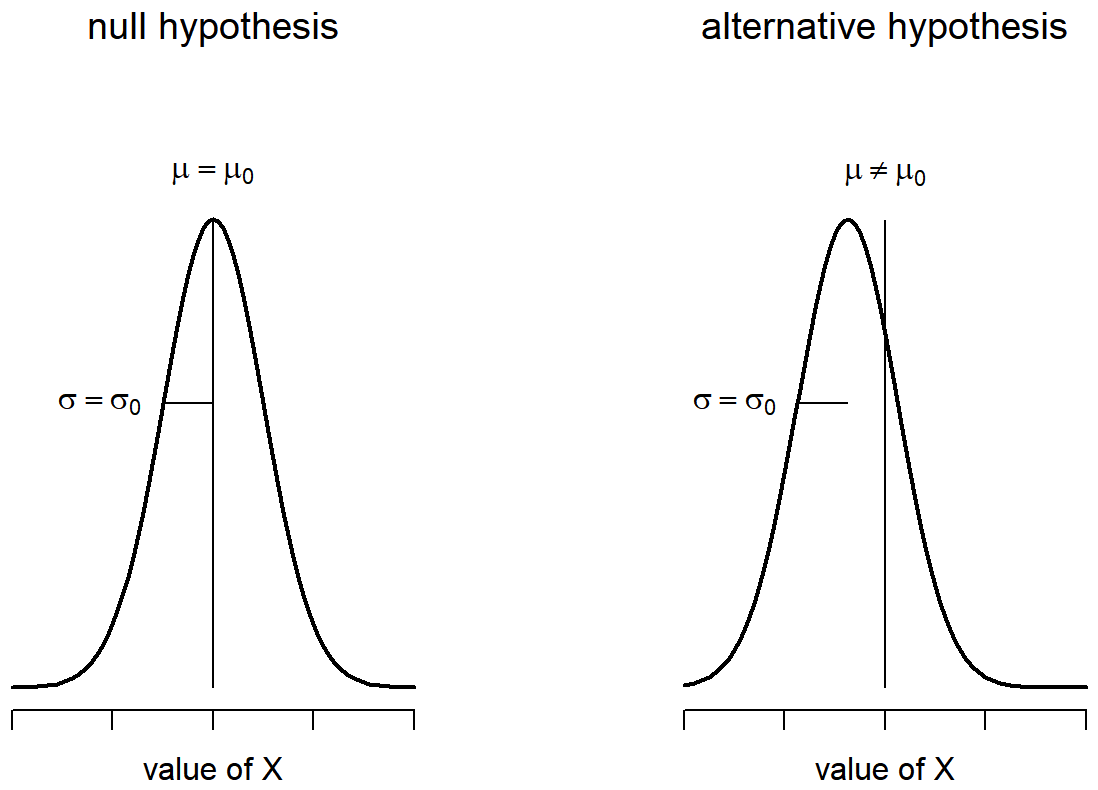
El primer paso para construir una prueba de hipótesis es tener claro cuáles son las hipótesis nulas y alternativas. Esto no es muy difícil de hacer. Nuestra hipótesis nula, H 0, es que la verdadera media poblacional μ para las calificaciones de los estudiantes de psicología es 67.5%; y nuestra hipótesis alternativa es que la media poblacional no es 67.5%. Si escribimos esto en notación matemática, estas hipótesis se convierten,
H 0:μ=67.5
H 1:μ≠ 67.5
aunque para ser honesto esta notación no agrega mucho a nuestra comprensión del problema, es solo una forma compacta de escribir lo que estamos tratando de aprender de los datos. Las hipótesis nulas H0 y la hipótesis alternativa H1 para nuestra prueba se ilustran en la Figura 13.2. Además de proporcionarnos estas hipótesis, el escenario descrito anteriormente nos proporciona una buena cantidad de conocimientos previos que podrían ser útiles. Específicamente, hay dos piezas especiales de información que podemos agregar:
1 Normalmente se distribuyen los grados de psicología. 1 Se sabe que la verdadera desviación estándar de estas puntuaciones σ es 9.5.
Por el momento, actuaremos como si estos fueran hechos absolutamente confiables. En la vida real, este tipo de conocimientos de fondo absolutamente confiables no existe, y así que si queremos confiar en estos hechos solo tendremos que hacer la suposición de que estas cosas son ciertas. Sin embargo, dado que estas suposiciones pueden estar justificadas o no, es posible que tengamos que verificarlas. Por ahora, sin embargo, vamos a mantener las cosas simples.
El siguiente paso es averiguar cuál sería una buena opción para una estadística de prueba diagnóstica; algo que nos ayudaría a discriminar entre H 0 y H 1. Dado que todas las hipótesis se refieren a la media poblacional μ, te sentirías bastante seguro de que la media muestral\(\bar{X}\) sería un lugar bastante útil para comenzar. Lo que podríamos hacer, es mirar la diferencia entre la media muestral\(\bar{X}\) y el valor que la hipótesis nula predice para la media poblacional. En nuestro ejemplo, eso significaría que calculamos\(\bar{X}\) - 67.5. De manera más general, si dejamos que μ 0 se refiera al valor que la hipótesis nula afirma que es nuestra media poblacional, entonces nos gustaría calcular
\(\bar{X}-\mu_{0}\)
Si esta cantidad es igual o está muy cerca de 0, las cosas se ven bien para la hipótesis nula. Si esta cantidad está muy lejos de 0, entonces parece menos probable que valga la pena retener la hipótesis nula. Pero, ¿a qué distancia de cero debería estar para nosotros rechazar H 0?
Para resolverlo, necesitamos ser un poco más astutos, y tendremos que confiar en esos dos conocimientos de fondo que escribí anteriormente, es decir, que los datos brutos se distribuyen normalmente, y conocemos el valor de la desviación estándar poblacional σ. Si la hipótesis nula es realmente verdadera, y la verdadera media es μ 0, entonces estos hechos juntos significan que conocemos la distribución poblacional completa de los datos: una distribución normal con media μ 0 y desviación estándar σ. Adoptando la notación de la Sección 9.5, un estadístico podría escribir esto como:
X∼Normal (μ 0, σ 2)
Bien, si eso es cierto, entonces ¿qué podemos decir sobre la distribución de\(\bar{X}\)? Bueno, como comentamos anteriormente (ver Sección 10.3.3), la distribución muestral de la media también\(\bar{X}\) es normal, y tiene media μ. Pero la desviación estándar de esta distribución de muestreo SE (\(\bar{X}\)), que se denomina error estándar de la media, es
\(\operatorname{SE}(\bar{X})=\dfrac{\sigma}{\sqrt{N}}\)
En otras palabras, si la hipótesis nula es verdadera entonces la distribución muestral de la media se puede escribir de la siguiente manera:
\(\bar{X}\)∼Normal (μ 0, SE (\(\bar{X}\)))
Ahora viene el truco. Lo que podemos hacer es convertir la media de la muestra\(\bar{X}\) en una puntuación estándar (Sección 5.6). Esto se escribe convencionalmente como z, pero por ahora me voy a referir a ello como\(z_{\bar{X}}\). (La razón para usar esta notación expandida es para ayudarle a recordar que estamos calculando la versión estandarizada de una media de muestra, no una versión estandarizada de una sola observación, que es a lo que generalmente se refiere una puntuación z). Cuando lo hacemos, la puntuación z para nuestra media muestral es
\(\ z_{\bar{X}} = {{\bar{X}-\mu_{0}} \over SE(\bar{X})}\)
o, equivalentemente
\(\ z_{\bar{X}} = {{\bar{X}-\mu_{0}} \over \sigma/ \sqrt{N} }\)
Este puntaje z es nuestro estadístico de prueba. Lo bueno de usar esto como nuestro estadístico de prueba es que, como todas las puntuaciones z, tiene una distribución normal estándar:
\(\ z_{\bar{X}}\)∼Normal (0,1)
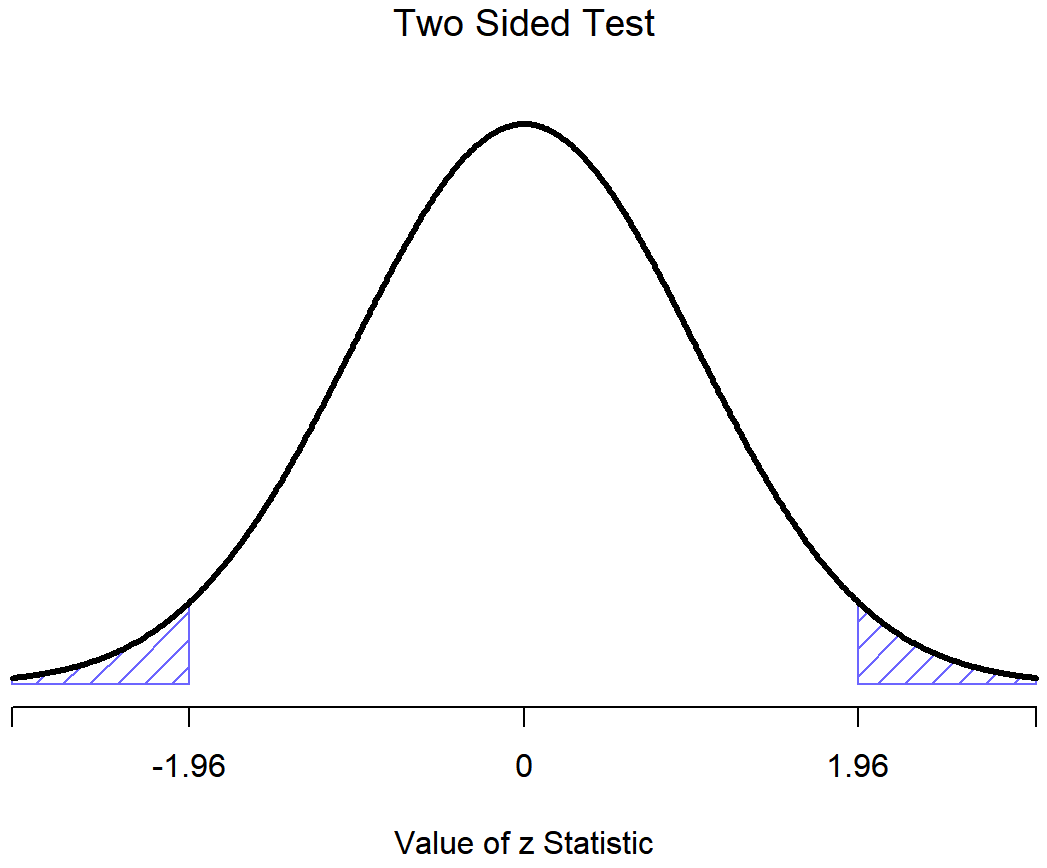
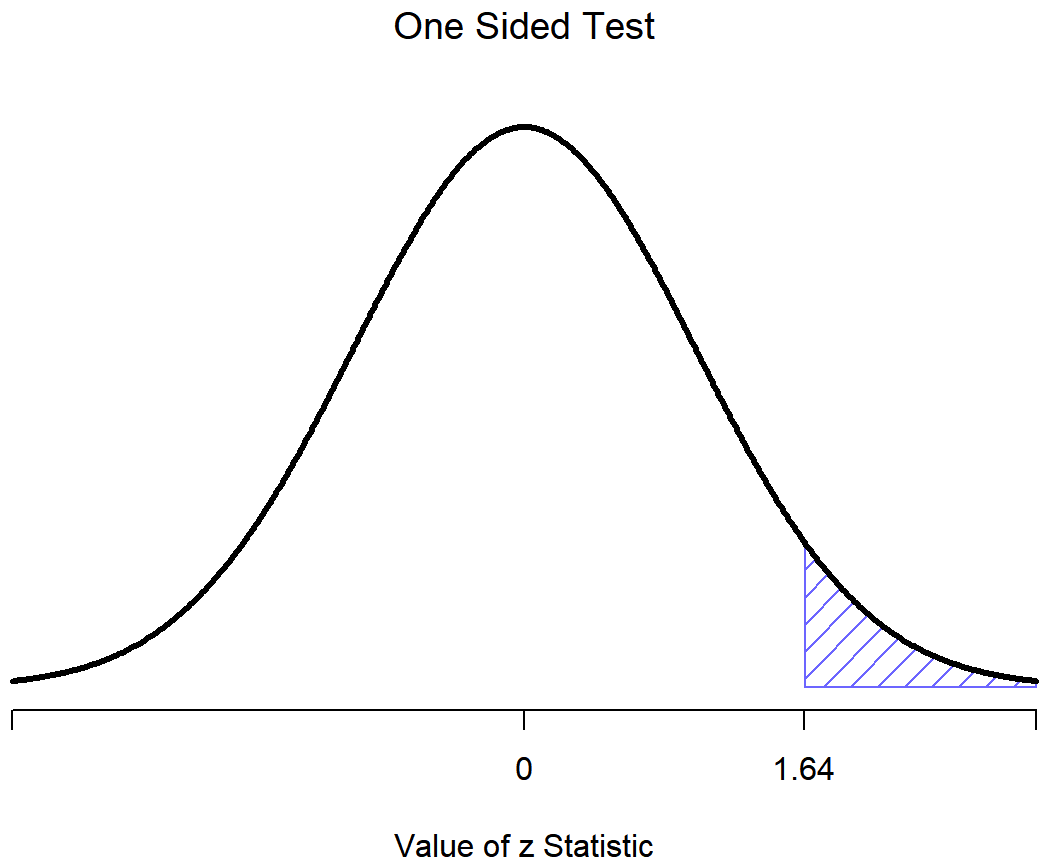
(de nuevo, vea la Sección 5.6 si ha olvidado por qué esto es cierto). Es decir, independientemente de la escala en la que estén los datos originales, el estadístico z mismo siempre tiene la misma interpretación: es igual al número de errores estándar que separan la media muestral observada\(\bar{X}\) de la media poblacional μ 0 predicha por la hipótesis nula. Mejor aún, independientemente de cuáles sean realmente los parámetros poblacionales para los puntajes brutos, las regiones críticas de 5% para la prueba z son siempre las mismas, como se ilustra en las Figuras 13.4 y 13.3. Y lo que esto significaba, ya en los días en que la gente hacía todas sus estadísticas a mano, es que alguien pudiera publicar una tabla como esta:
| nivel α deseado | prueba de dos caras | prueba unilateral |
|---|---|---|
| .1 | 1.644854 | 1.281552 |
| .05 | 1.959964 | 1.644854 |
| .01 | 2.575829 | 2.326348 |
| .001 | 3.290527 | 3.090232 |
lo que a su vez significó que los investigadores pudieran calcular su estadística z a mano, y luego buscar el valor crítico en un libro de texto. Eso fue algo increíblemente útil para poder hacer en ese entonces, pero es un poco innecesario en estos días, ya que es trivialmente fácil hacerlo con software como R.
ejemplo trabajado usando R
Ahora, como mencioné antes, la prueba z casi nunca se usa en la práctica. Es tan raramente utilizado en la vida real que la instalación básica de R no tiene una función incorporada para ello. Sin embargo, la prueba es tan increíblemente simple que es realmente fácil hacer una manualmente. Volvamos a los datos de la clase del Dr. Zeppo. Habiendo cargado los datos de calificaciones, lo primero que tengo que hacer es calcular la media muestral:
sample.mean <- mean( grades )
print( sample.mean )## [1] 72.3Luego, creo variables correspondientes a la desviación estándar poblacional conocida (σ=9.5), y el valor de la población media que especifica la hipótesis nula (μ 0 =67.5):
mu.null <- 67.5
sd.true <- 9.5Creemos también una variable para el tamaño de la muestra. Podríamos contar el número de observaciones nosotros mismos, y escribir N <- 20 en el símbolo del sistema, pero contar es tedioso y repetitivo. Consigamos que R haga el tedioso bit repetitivo usando la función length (), que nos dice cuántos elementos hay en un vector:
N <- length( grades )
print( N ) ## [1] 20A continuación, calculemos el error estándar (verdadero) de la media:
sem.true <- sd.true / sqrt(N)
print(sem.true) ## [1] 2.124265Y finalmente, calculamos nuestro puntaje z:
z.score <- (sample.mean - mu.null) / sem.true
print( z.score ) ## [1] 2.259606En este punto, tradicionalmente buscaríamos el valor 2.26 en nuestra tabla de valores críticos. Nuestra hipótesis original era bilateral (realmente no teníamos ninguna teoría sobre si los estudiantes de psicología serían mejores o peores en estadística que otros estudiantes) por lo que nuestra prueba de hipótesis también es bilateral (o de dos colas). Mirando la mesita que mostré anteriormente, podemos ver que 2.26 es mayor que el valor crítico de 1.96 que se requeriría para ser significativo en α=.05, pero menor que el valor de 2.58 que se requeriría para ser significativo a un nivel de α=.01. Por lo tanto, podemos concluir que tenemos un efecto significativo, que podríamos escribir diciendo algo como esto:
Con una nota media de 73.2 en la muestra de estudiantes de psicología, y asumiendo una verdadera desviación estándar poblacional de 9.5, podemos concluir que los estudiantes de psicología tienen puntuaciones estadísticas significativamente diferentes a la media de clase (z=2.26, N=20, p<.05).
Sin embargo, ¿y si quieres un valor p exacto? Bueno, en el pasado, las tablas de valores críticos eran enormes, y así podrías buscar tu valor z real, y encontrar el valor más pequeño de α para el cual tus datos serían significativos (que, como se discutió anteriormente, es la definición misma de un valor p). Sin embargo, buscar cosas en los libros es tedioso, y escribir cosas en computadoras es increíble. Entonces hagámoslo usando R en su lugar. Ahora bien, observe que el nivel α de una prueba z (o cualquier otra prueba, para el caso) define el área total “bajo la curva” para la región crítica, ¿verdad? Es decir, si establecemos α=.05 para una prueba bilateral, entonces la región crítica se configura de tal manera que el área bajo la curva para la región crítica es .05. Y, para la prueba z, el valor crítico de 1.96 se elige de esa manera porque el área en la cola inferior (es decir, por debajo de −1.96) es exactamente .025 y el área debajo de la cola superior (es decir, por encima de 1.96) es exactamente .025. Entonces, dado que nuestra estadística z observada es 2.26, ¿por qué no calcular el área bajo la curva por debajo de −2.26 o por encima de 2.26? En R podemos calcular esto usando la función pnorm (). Para la cola superior:
upper.area <- pnorm( q = z.score, lower.tail = FALSE )
print( upper.area )## [1] 0.01192287El bajo.cola = FALSO es yo diciéndole a R que calcule el área bajo la curva desde 2.26 y hacia arriba. Si le hubiera dicho que lower.tail = VERDADERO, entonces R calcularía el área desde 2.26 y abajo, y me daría una respuesta 0.9880771. Alternativamente, para calcular el área desde −2.26 y por debajo, obtenemos
lower.area <- pnorm( q = -z.score, lower.tail = TRUE )
print( lower.area )## [1] 0.01192287Así obtenemos nuestro valor p:
p.value <- lower.area + upper.area
print( p.value )## [1] 0.02384574Supuestos de la prueba z
Como ya he dicho antes, todas las pruebas estadísticas hacen suposiciones. Algunas pruebas hacen suposiciones razonables, mientras que otras pruebas no. La prueba que acabo de describir —la prueba z de una muestra— hace tres suposiciones básicas. Estos son:
- Normalidad. Como se suele describir, la prueba z supone que la verdadera distribución poblacional es normal. 186 suele ser bastante razonable, y no sólo eso, es una suposición que podemos comprobar si nos sentimos preocupados por ello (ver Sección 13.9).
- Independencia. El segundo supuesto de la prueba es que las observaciones en su conjunto de datos no están correlacionadas entre sí, o relacionadas entre sí de alguna manera divertida. Esto no es tan fácil de verificar estadísticamente: se basa un poco en un buen diseño experimental. Un ejemplo obvio (y estúpido) de algo que viola esta suposición es un conjunto de datos donde “copias” la misma observación una y otra vez en tu archivo de datos: así terminas con un “tamaño de muestra” masivo, que consiste en una sola observación genuina. De manera más realista, hay que preguntarse si es realmente plausible imaginar que cada observación es una muestra completamente aleatoria de la población que le interesa. En la práctica, esta suposición nunca se cumple; pero hacemos nuestro mejor esfuerzo para diseñar estudios que minimicen los problemas de los datos correlacionados.
- Desviación estándar conocida. El tercer supuesto de la prueba z es que la verdadera desviación estándar de la población es conocida por el investigador. Esto es simplemente estúpido. En ningún problema de análisis de datos del mundo real conoces la desviación estándar σ de alguna población, pero son completamente ignorantes sobre la media μ. En otras palabras, esta suposición siempre es errónea.
Ante la estupidez de suponer que σ es conocida, veamos si podemos vivir sin ella. Esto nos saca del lúgubre dominio de la prueba z, y al reino mágico de la prueba t, con unicornios y hadas y duendes, y um...