
16.2: ANOVA factorial 2- Diseños equilibrados, interacciones permitidas
- Page ID
- 151301

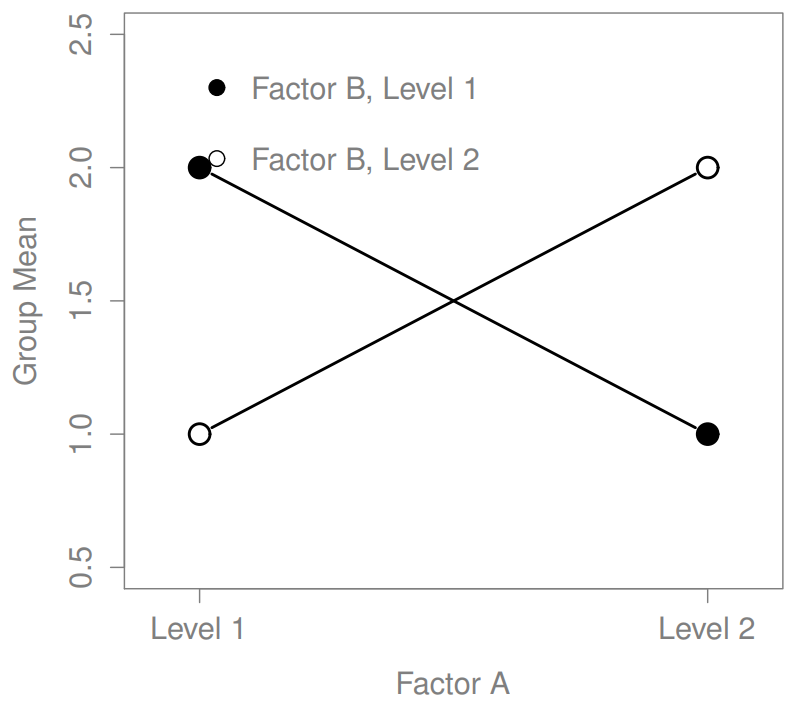
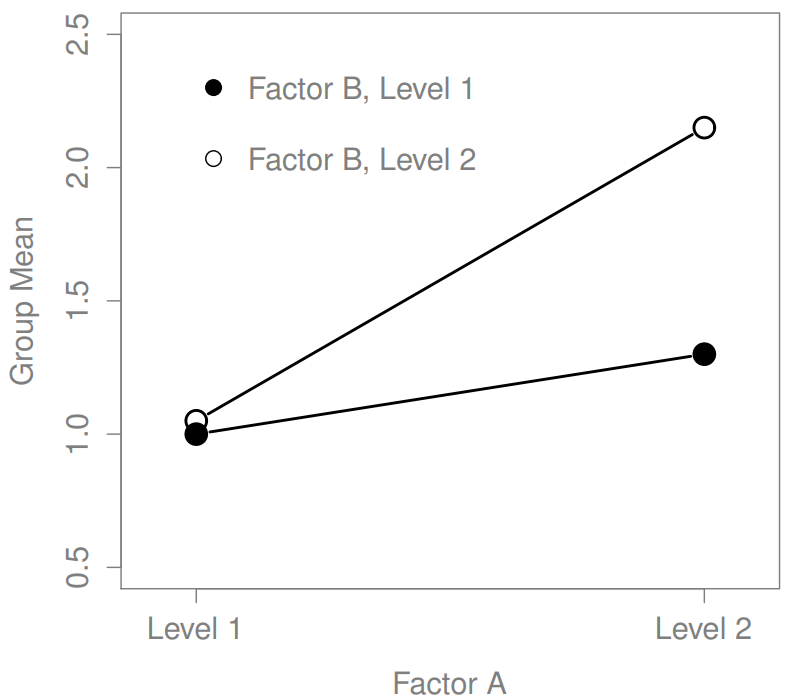
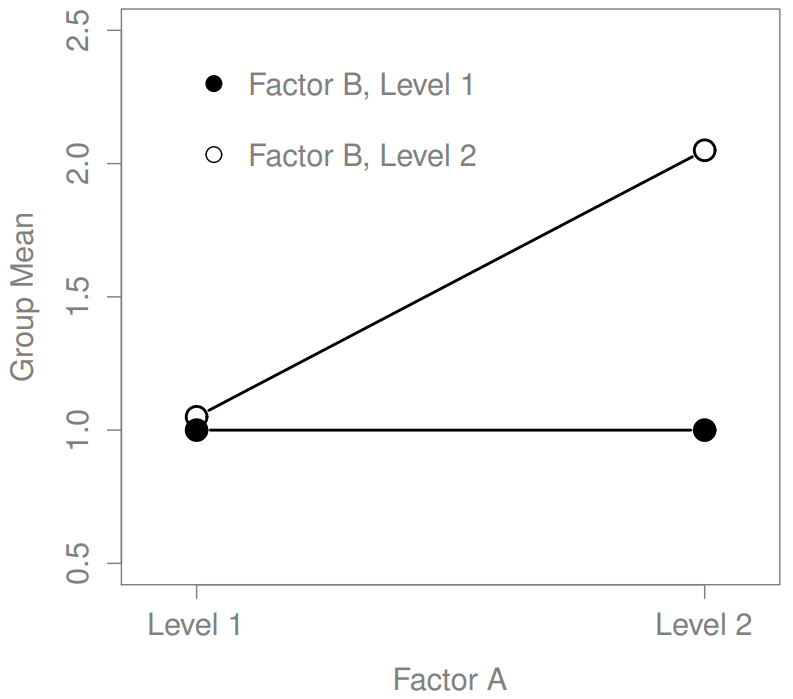
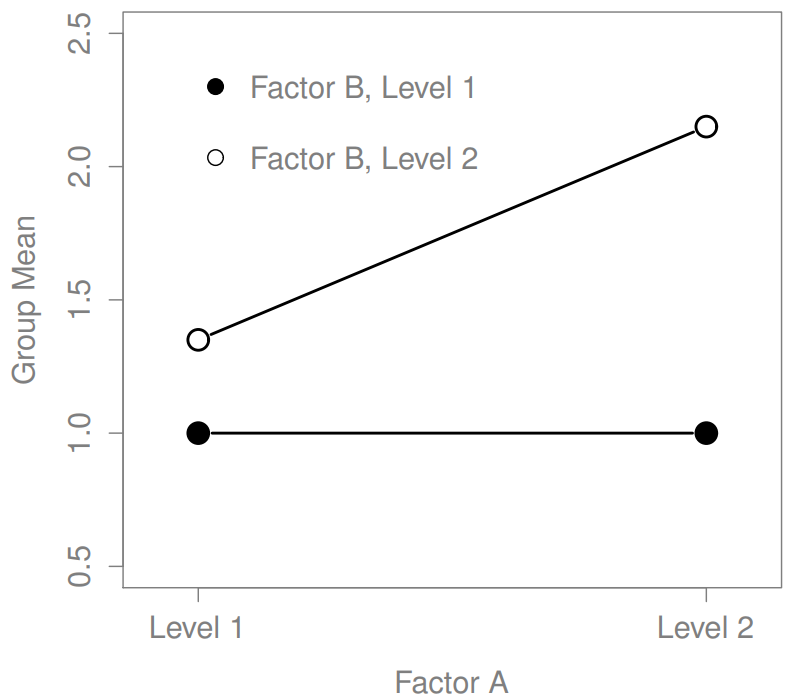
Los cuatro patrones de datos mostrados en la Figura?? son todos bastante realistas: hay muchos conjuntos de datos que producen exactamente esos patrones. Sin embargo, no son toda la historia, y el modelo ANOVA del que hemos estado hablando hasta este punto no es suficiente para dar cuenta a cabalidad de una tabla de medias grupales. ¿Por qué no? Bueno, hasta ahora tenemos la capacidad de hablar sobre la idea de que las drogas pueden influir en el estado de ánimo, y la terapia puede influir en el estado de ánimo, pero no hay forma de hablar sobre la posibilidad de una interacción entre ambos. Se dice que una interacción entre A y B ocurre siempre que el efecto del Factor A es diferente, dependiendo del nivel de Factor B del que estemos hablando. Varios ejemplos de un efecto de interacción con el contexto de un ANOVA de 2 x 2 se muestran en la Figura?? . Para dar un ejemplo más concreto, supongamos que la operación de Anxifree y Joyzepam se rige por mecanismos fisiológicos bastante diferentes, y una consecuencia de esto es que mientras Joyzepam tiene más o menos el mismo efecto sobre el estado de ánimo independientemente de si uno está en terapia, Anxifree es en realidad mucho más efectivo cuando se administra junto con TCC. El ANOVA que desarrollamos en la sección anterior no capta esta idea. Para tener una idea de si una interacción realmente está sucediendo aquí, ayuda a trazar los diversos medios grupales. Hay bastantes formas diferentes de dibujar estas gráficas en R. Una forma fácil es usar la función interaction.plot (), pero esta función no dibujará barras de error por ti. Una función bastante simple que incluirá barras de error para usted es la función LinePlot.ci () en el paquete sciplots (ver Sección 10.5.4). El comando
library(sciplot)
library(lsr)
lineplot.CI( x.factor = clin.trial$drug,
response = clin.trial$mood.gain,
group = clin.trial$therapy,
ci.fun = ciMean,
xlab = "drug",
ylab = "mood gain" )produce la salida se muestra en la Figura 16.9 (no olvide que la función CIMean está en el paquete lsr, por lo que necesita tener lsr cargado!). Nuestra principal preocupación se relaciona con el hecho de que las dos líneas no son paralelas. El efecto de la TCC (diferencia entre la línea continua y la línea punteada) cuando el medicamento es Joyzepam (lado derecho) parece estar cerca de cero, incluso menor que el efecto de la TCC cuando se usa un placebo (lado izquierdo). Sin embargo, cuando se administra Anxifree, el efecto de la TCC es mayor que el placebo (medio). ¿Este efecto es real, o esto es solo una variación aleatoria debido al azar? Nuestro ANOVA original no puede responder a esta pregunta, porque no permitimos la idea de que ¡las interacciones incluso existen! En esta sección, solucionaremos este problema.
¿Cuál es exactamente el efecto de interacción?
La idea clave que vamos a introducir en esta sección es la de un efecto de interacción. Lo que eso significa para nuestras fórmulas R es que vamos a anotar modelos así aunque solo hay dos factores involucrados en nuestro modelo (es decir, fármaco y terapia), hay tres términos distintos (es decir, fármaco, terapia y fármaco:terapia). Es decir, además de los principales efectos de la droga y la terapia, tenemos un nuevo componente al modelo, que es nuestro término de interacción fármaco:terapia. Intuitivamente, la idea detrás de un efecto de interacción es bastante simple: solo significa que el efecto del Factor A es diferente, dependiendo del nivel de Factor B del que estemos hablando. Pero, ¿qué significa eso en términos de nuestros datos? Figura?? representa varios patrones diferentes que, aunque bastante diferentes entre sí, contarían como un efecto de interacción. Así que no es del todo sencillo traducir esta idea cualitativa en algo matemático con lo que un estadístico pueda trabajar. En consecuencia, la forma en que se formaliza la idea de un efecto de interacción en términos de hipótesis nulas y alternativas es un poco difícil, y supongo que muchos lectores de este libro probablemente no estarán tan interesados. Aun así, voy a tratar de dar la idea básica aquí.
Para empezar, necesitamos ser un poco más explícitos sobre nuestros principales efectos. Considere el efecto principal del Factor A (medicamento en nuestro ejemplo de funcionamiento). Originalmente formulamos esto en términos de la hipótesis nula de que las dos medias marginales μ r. son todas iguales entre sí. Obviamente, si todos estos son iguales entre sí, entonces también deben ser iguales a la gran media μ.. también, ¿verdad? Entonces lo que podemos hacer es definir el efecto del Factor A en el nivel r para que sea igual a la diferencia entre la media marginal μ r. y la gran media μ.. .
Denotemos este efecto por α r, y notemos que
α r =μ r. −μ..
Ahora bien, por definición todos los valores α r deben sumar a cero, por la misma razón que el promedio de las medias marginales μ r. debe ser la gran media μ.. . De manera similar podemos definir el efecto del Factor B en el nivel i como la diferencia entre la media marginal de columna μ .c y la gran media μ..
β c =μ .c −μ..
y una vez más, estos valores β c deben sumar a cero. La razón por la que a veces a los estadísticos les gusta hablar de los efectos principales en términos de estos valores αr y β c es que les permite ser precisos sobre lo que significa decir que no hay efecto de interacción. Si no hay interacción en absoluto, entonces estos valores α r y β c describirán perfectamente las medias del grupo μ rc. Específicamente, significa que
μ rc =μ.. +α r +β c
Es decir, no hay nada especial en el grupo, significa que no podrías predecir perfectamente conociendo todos los medios marginales. Y esa es nuestra hipótesis nula, ahí mismo. La hipótesis alternativa es que
μ rc ≠ μ.. +α r +β c
para al menos un grupo r c en nuestra tabla. Sin embargo, a los estadísticos a menudo les gusta escribir esto de manera ligeramente diferente. Por lo general, definirán la interacción específica asociada con el grupo r c como algún número, torpemente referido como (αβ) rc, y luego dirán que la hipótesis alternativa es que
μ rc =μ.. +α r +β c + (αβ) rc
donde (αβ) rc es distinto de cero para al menos un grupo. Esta notación es un poco fea a la vista, pero es útil como veremos en la siguiente sección al discutir cómo calcular la suma de cuadrados.
## Warning: package 'sciplot' was built under R version 3.5.2## Warning: package 'lsr' was built under R version 3.5.2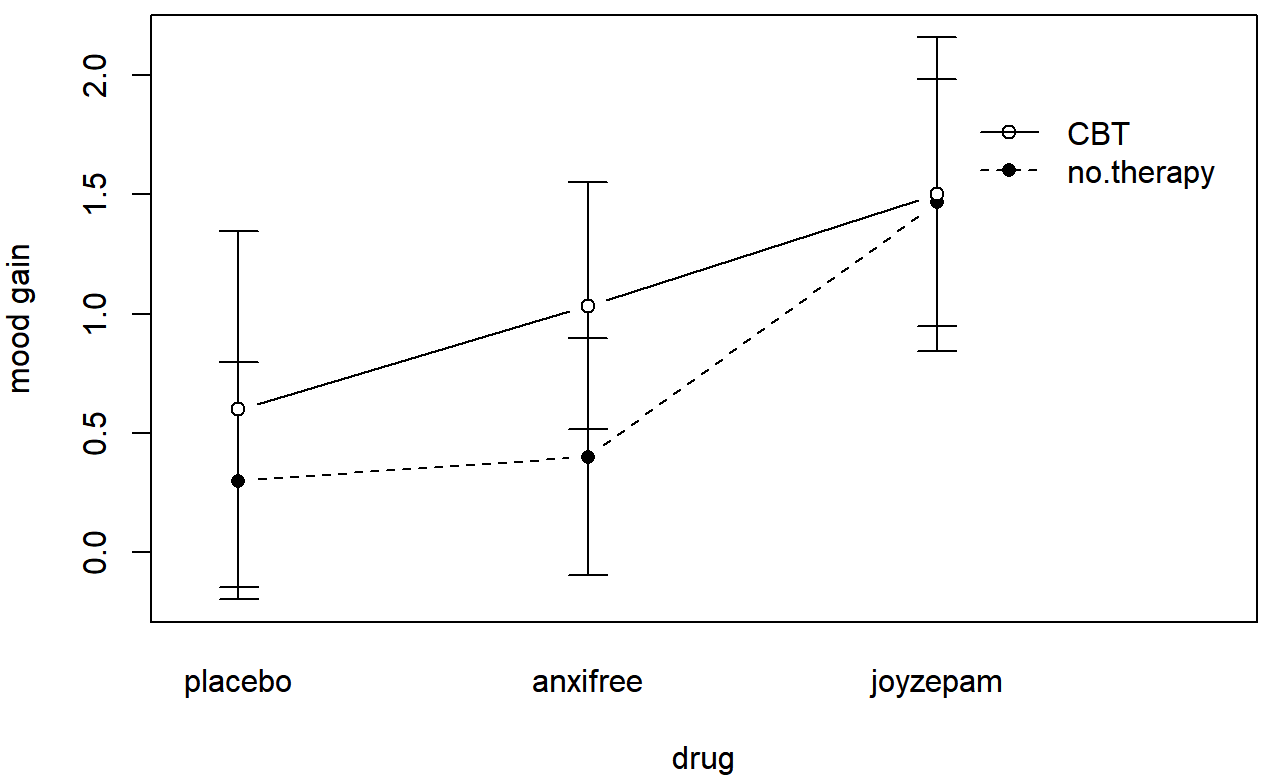
x.leg y y.leg: ¿type? Lineplot.ci para más detalles.Cálculo de sumas de cuadrados para la interacción
¿Cómo se debe calcular la suma de cuadrados para los términos de interacción, SS A:B? Bueno, antes que nada, ayuda notar cómo la sección anterior definió el efecto de interacción en términos de la medida en que las medias grupales reales difieren de lo que cabría esperar con solo mirar las medias marginales. Por supuesto, todas esas fórmulas se refieren a parámetros de población más que a estadísticas de muestra, por lo que en realidad no sabemos cuáles son. Sin embargo, podemos estimarlos usando medias muestrales en lugar de medias poblacionales. Entonces para el Factor A, una buena manera de estimar el efecto principal en el nivel r como la diferencia entre la media marginal de la muestra\(\ \bar{Y_{rc}}\) y la gran media de la muestra\(\ \bar{Y_{...}}\). Es decir, usaríamos esto como nuestra estimación del efecto:
\ (\\ hat {\ alpha_r} =\ bar {Y_ {r.}} -\ bar {Y
_ {..}}\)
De igual manera, nuestra estimación del efecto principal del Factor B en el nivel c puede definirse de la siguiente manera:
\(\ \hat{\beta_c} = \bar{Y_{.c}} - \bar{Y_{..}}\)
Ahora bien, si vuelves a las fórmulas que usé para describir los valores SS para los dos efectos principales, notarás que estos términos de efecto son exactamente las cantidades que estábamos cuadrando y sumando! Entonces, ¿cuál es el análogo de esto para términos de interacción? La respuesta a esto se puede encontrar reordenando primero la fórmula para el grupo significa μ rc bajo la hipótesis alternativa, para que obtengamos esto:
\(\begin{aligned}(\alpha \beta)_{r c} &=\mu_{r c}-\mu_{..}-\alpha_{r}-\beta_{c} \\ &=\mu_{r c}-\mu_{. .}-\left(\mu_{r .}-\mu_{. .}\right)-\left(\mu_{. c}-\mu_{..}\right) \\ &=\mu_{r c}-\mu_{r .}-\mu_{. c}+\mu_{..} \end{aligned}\)
Entonces, una vez más, si sustituimos nuestras estadísticas de muestra en lugar de las medias poblacionales, obtenemos lo siguiente como nuestra estimación del efecto de interacción para el grupo rc, que es
\(\ \hat{(\alpha\beta)_{rc}} = \bar{Y_{rc}} - \bar{Y_{r.}} - \bar{Y_{.c}} + \bar{Y_{..}}\)
Ahora todo lo que tenemos que hacer es sumar todas estas estimaciones en todos los niveles R del Factor A y todos los niveles C del Factor B, y obtenemos la siguiente fórmula para la suma de cuadrados asociados con la interacción en su conjunto:
\(\mathrm{SS}_{A: B}=N \sum_{r=1}^{R} \sum_{c=1}^{C}\left(\bar{Y}_{r c}-\bar{Y}_{r .}-\bar{Y}_{. c}+\bar{Y}_{. .}\right)^{2}\)
donde, multiplicamos por N porque hay N observaciones en cada uno de los grupos, y queremos que nuestros valores de SS reflejen la variación entre observaciones contabilizadas por la interacción, no la variación entre grupos.
Ahora que tenemos una fórmula para calcular SS A:B, es importante reconocer que el término de interacción es parte del modelo (por supuesto), por lo que la suma total de cuadrados asociados al modelo, SS M es ahora igual a la suma de los tres valores SS relevantes, SS A +SS B +SS A: B. La suma residual de cuadrados SS R todavía se define como la variación sobrante, es decir SS T -SS M, pero ahora que tenemos el término de interacción esto se convierte en
SS R = SS T − (SS A +SS B +SS A: B)
Como consecuencia, la suma residual de cuadrados SS R será menor que en nuestro ANOVA original que no incluyó interacciones.
Grados de libertad para la interacción
Calcular los grados de libertad para la interacción es, una vez más, un poco más complicado que el cálculo correspondiente para los efectos principales. Para empezar, pensemos en el modelo ANOVA en su conjunto. Una vez que incluimos los efectos de interacción en el modelo, permitimos que cada grupo tenga una media única, μ rc. Para un ANOVA factorial R×C, esto significa que hay cantidades R×C de interés en el modelo, y solo una restricción: todas las medias del grupo necesitan promediar a la gran media. Entonces el modelo en su conjunto necesita tener (R×C) −1 grados de libertad. Pero el efecto principal del Factor A tiene R−1 grados de libertad, y el efecto principal del Factor B tiene C−1 grados de libertad. Lo que significa que los grados de libertad asociados a la interacción son
\(\begin{aligned} d f_{A: B} &=(R \times C-1)-(R-1)-(C-1) \\ &=R C-R-C+1 \\ &=(R-1)(C-1) \end{aligned}\)
que es solo el producto de los grados de libertad asociados con el factor de fila y el factor de columna.
¿Y los grados residuales de libertad? Debido a que hemos agregado términos de interacción, que absorben algunos grados de libertad, quedan menos grados residuales de libertad. Específicamente, tenga en cuenta que si el modelo con interacción tiene un total de (R×C) −1, y hay N observaciones en su conjunto de datos que están restringidas para satisfacer 1 gran media, sus grados residuales de libertad ahora se convierten en N− (R×C) −1+1, o simplemente N− (R×C).
Ejecución del ANOVA en R
Agregar términos de interacción al modelo ANOVA en R es sencillo. Volviendo a nuestro ejemplo corriente del ensayo clínico, además de los términos de efecto principal de fármaco y terapia, incluimos el término de interacción fármaco:terapia. Entonces el comando R para crear el modelo ANOVA ahora se ve así:
model.3 <- aov( mood.gain ~ drug + therapy + drug:therapy, clin.trial )Sin embargo, R permite una taquigrafía conveniente. En lugar de escribir los tres términos, puedes acortar el lado derecho de la fórmula para drogar*terapia. El operador * dentro de la fórmula se toma para indicar que desea tanto los efectos principales como la interacción. Así que también podemos ejecutar nuestro ANOVA así, y obtener la misma respuesta:
model.3 <- aov( mood.gain ~ drug * therapy, clin.trial )
summary( model.3 )
## Df Sum Sq Mean Sq F value Pr(>F)
## drug 2 3.453 1.7267 31.714 1.62e-05 ***
## therapy 1 0.467 0.4672 8.582 0.0126 *
## drug:therapy 2 0.271 0.1356 2.490 0.1246
## Residuals 12 0.653 0.0544
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Resulta que, si bien tenemos un efecto principal significativo del fármaco (F 2,12 =31.7, p<.001) y el tipo de terapia (F 1,12 =8.6, p=.013), no hay interacción significativa entre los dos (F 2,12 =2.5, p=0.125).
Interpretación de los resultados
Hay un par de cosas muy importantes a considerar a la hora de interpretar los resultados del ANOVA factorial. En primer lugar, está el mismo tema que tuvimos con el ANOVA unidireccional, que es que si obtienes un efecto principal significativo de (digamos) droga, no te dice nada sobre qué medicamentos son diferentes entre sí. Para averiguarlo, es necesario realizar análisis adicionales. Hablaremos de algunos análisis que puedes ejecutar en las Secciones 16.7 y?? . Lo mismo ocurre con los efectos de interacción: saber que hay una interacción significativa no te dice nada sobre qué tipo de interacción existe. Nuevamente, necesitarás realizar análisis adicionales.
En segundo lugar, hay un tema de interpretación muy peculiar que surge cuando se obtiene un efecto de interacción significativo pero ningún efecto principal correspondiente. Esto sucede a veces. Por ejemplo, en la interacción cruzada que se muestra en la Figura?? , esto es exactamente lo que encontrarías: en este caso, ninguno de los efectos principales sería significativo, sino el efecto de interacción lo sería. Esta es una situación difícil de interpretar, y la gente a menudo se confunde un poco al respecto. El consejo general que a los estadísticos les gusta dar en esta situación es que no se debe prestar mucha atención a los efectos principales cuando hay una interacción presente. La razón por la que dicen esto es que, aunque las pruebas de los efectos principales son perfectamente válidas desde un punto de vista matemático, cuando hay un efecto de interacción significativo los efectos principales rara vez ponen a prueba hipótesis interesantes. Recordemos de la Sección 16.1.1 que la hipótesis nula para un efecto principal es que las medias marginales son iguales entre sí, y que una media marginal se forma promediando a través de varios grupos diferentes. Pero si tienes un efecto de interacción significativo, entonces sabes que los grupos que componen la media marginal no son homogéneos, así que no es realmente obvio por qué incluso te importarían esos medios marginales.
Esto es a lo que me refiero. Nuevamente, sigamos con un ejemplo clínico. Supongamos que tenemos un diseño 2×2 comparando dos tratamientos diferentes para fobias (por ejemplo, desensibilización sistemática vs inundación), y dos fármacos diferentes para reducir la ansiedad (por ejemplo, Anxifree vs Joyzepam). Ahora supongamos que lo que encontramos fue que Anxifree no tuvo efecto cuando la desensibilización era el tratamiento, y Joyzepam no tuvo efecto cuando la inundación era el tratamiento. Pero ambos fueron bastante efectivos para el otro tratamiento. Esta es una interacción cruzada clásica, y lo que encontraríamos al ejecutar el ANOVA es que no hay un efecto principal del fármaco, sino una interacción significativa. Ahora bien, ¿qué significa realmente decir que no hay ningún efecto principal? Bien, significa que, si promediamos sobre los dos tratamientos psicológicos diferentes, entonces el efecto promedio de Anxifree y Joyzepam es el mismo. Pero, ¿por qué a alguien le importaría eso? Al tratar a alguien por fobias, nunca ocurre que una persona pueda ser tratada usando un “promedio” de inundaciones y desensibilización: eso no tiene mucho sentido. O consigues uno o el otro. Para un tratamiento, un medicamento es efectivo; y para el otro, el otro medicamento es efectivo. La interacción es lo importante; el efecto principal es algo irrelevante.
Este tipo de cosas pasan mucho: el efecto principal son pruebas de medios marginales, y cuando una interacción está presente muchas veces nos encontramos no muy interesados en los medios marginales, porque implican promediar sobre cosas que la interacción nos dice ¡no deben promediarse! Por supuesto, no siempre se da el caso de que un efecto principal carezca de sentido cuando hay una interacción presente. A menudo se puede obtener un gran efecto principal y una interacción muy pequeña, en cuyo caso aún se pueden decir cosas como “el medicamento A es generalmente más efectivo que el medicamento B” (porque hubo un gran efecto de la droga), pero necesitaría modificarlo un poco agregando que “la diferencia en la efectividad fue diferente para diferentes tratamientos psicológicos”. En cualquier caso, el punto principal aquí es que cada vez que consigas una interacción significativa debes detenerte y pensar en lo que realmente significa el efecto principal en este contexto. No asuma automáticamente que el efecto principal es interesante.