
4.4: Técnicas de muestreo
- Page ID
- 151360

Al hacer investigación, es fundamental obtener una muestra que sea representativa de la población. Las muestras no representativas o sesgadas producirán inferencias inválidas, independientemente del tamaño de la muestra. Por ejemplo, es mucho mejor tener una muestra representativa de 500 observaciones, que una muestra sesgada de 50,000 observaciones. En esta sección exploraremos métodos de muestreo que tengan la mayor probabilidad de producir una muestra representativa.
Una advertencia: incluso si intenta cuidadosamente crear una muestra representativa, siempre existe la posibilidad de que seleccione una muestra atípica no representativa. Sin embargo, si usa uno de estos métodos de muestreo adecuados, tiene una pequeña probabilidad de seleccionar una muestra atípica.
Los mejores métodos de muestreo son aquellos en los que se puede calcular la probabilidad de obtener una muestra representativa. Los métodos se denominan métodos de muestreo probabilístico. Otros métodos de muestreo no probabilístico tienen un sesgo inconmensurable y deben evitarse al realizar investigaciones
Métodos de muestreo de probabilidad
Estos métodos suelen producir una muestra que es representativa de la población. Estos métodos también se denominan muestreo científico.
Muestreo Aleatorio Simple 46
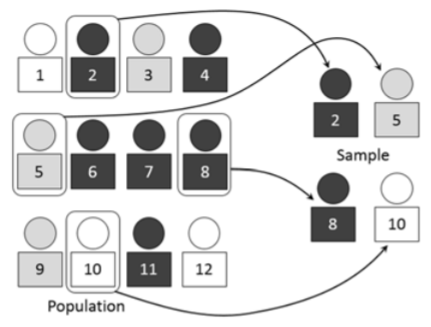
Una muestra aleatoria simple es un subconjunto de una población en la que todos los miembros de la población tienen las mismas posibilidades de ser elegidos y son mutuamente independientes entre sí. Piense en el muestreo aleatorio como una rifa o lotería en la que todos los nombres se ponen en un tazón y luego se seleccionan algunos nombres al azar.
Las muestras aleatorias en la práctica son casi imposibles de obtener ya que es difícil enumerar a todos los miembros de la población.
Ventajas del muestreo aleatorio simple:
- sin posibilidad de sesgo en el método de muestreo
- no se necesita conocimiento de demografía poblacional
- precisión fácil de medir
Desventajas del muestreo aleatorio simple:
- a menudo imposible de realizar debido a la dificultad de catalogar la población
- alto gasto
- a menudo menos precisa que una muestra estratificada
Ejemplo: Búsqueda de control personalizado
Antes de salir de la aduana en varios aeropuertos internacionales, todos los pasajeros deben presionar un botón. Si el botón es rojo, se le requerirá que realice una búsqueda intensiva. Si el botón es verde, no se le buscará. 47 El botón es totalmente aleatorio y tiene un 20% de posibilidades de ser rojo. Los pasajeros que están sujetos a la búsqueda intensiva son una verdadera muestra aleatoria simple de toda la población de pasajeros que llegan.

Muestreo sistemático 48
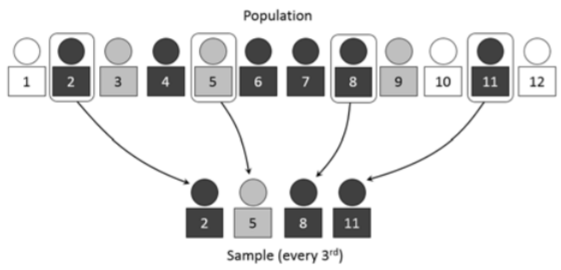
Una muestra sistemática es un subconjunto de la población en la que el primer miembro de la muestra se selecciona al azar y todos los miembros posteriores se eligen por un intervalo periódico fijo. Un ejemplo sería tener una lista de toda la población y luego tomar cada tercera persona de la lista.
Ventajas del Muestreo Sistemático:
- fácil de diseñar y explicar
- más económico que el muestreo aleatorio
- evita la agrupación aleatoria (varios valores adyacentes)
Desventajas del muestreo sistemático:
- puede estar sesgada si la población está modelada o tiene un rasgo periódico
- más fácil para el investigador influir erróneamente en los datos
- el tamaño de la población debe conocerse de antemano
Ejemplo: Pruebas de drogas aleatorias de empleados
Una compañía naviera tiene aproximadamente 20,000 empleados. La compañía decidió administrar una prueba de drogas aleatoria al 5% de los empleados, un tamaño de muestra de 1000. La empresa tiene una lista de todos los empleados ordenados por número de seguro social. Se selecciona un número aleatorio entre 1 y 20. A partir de esa persona, también se muestrean cada 20 personas posteriores. Por ejemplo, si el número seleccionado es 16, entonces la compañía seleccionaría a las personas 16, 36, 56, 76,..., 19996 para pruebas de drogas.
Muestreo estratificado 49
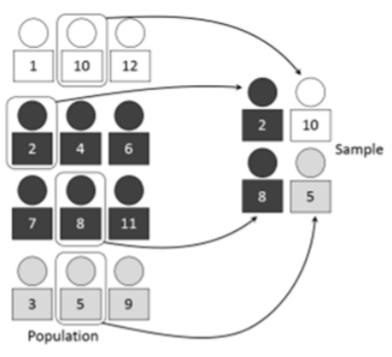
Se diseña una muestra estratificada dividiendo la población en subgrupos llamados estratos, para luego muestrear de manera que la proporción de cada subgrupo en la muestra coincida con la proporción de cada subgrupo en la población. Por ejemplo, si se sabe que una población es 60% femenina y 40% masculina, entonces una muestra de 1000 personas tendría 600 mujeres y 400 hombres.
Ventajas del Muestreo Estratificado:
- minimiza el sesgo de selección ya que todos los estratos están representados de manera justa
- cada subgrupo recibe una representación adecuada
- alta precisión (desviación estándar baja) en comparación con otros métodos
Desventajas del muestreo estratificado:
- alto conocimiento de la demografía poblacional necesario
- no todas las poblaciones se estratifican fácilmente
- consume mucho tiempo y es caro
Ejemplo: Conversaciones en redes sociales sobre raza
En 2016, Pew Research Center realizó un estudio para examinar cómo las personas usan las redes sociales como Twitter o Facebook. 50 El estudio se centró en el contenido y las etiquetas hash utilizadas en los comentarios de las personas sobre eventos que involucran ataques de motivación racial por parte de la policía y diferencias de opinión sobre grupos como Black Lives Matter.

Dado que el estudio involucró las opiniones de las personas sobre la raza, fue importante que Pew utilizara muestreo estratificado por raza. Se tuvo especial cuidado para asegurar que hubiera una representación adecuada en la muestra de grupos afroamericanos y latinos tradicionalmente submuestreados.
Muestreo en racimos
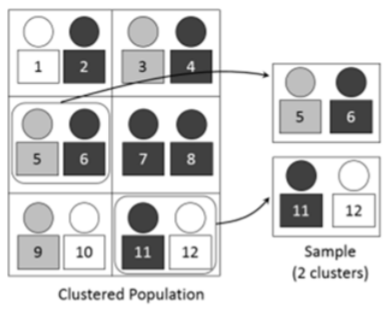
Se crea una muestra de conglomerados dividiendo primero la población en grupos llamados clusters, y luego tomando una muestra de clusters. Un ejemplo de muestreo por conglomerados es seleccionar aleatoriamente varias clases en una universidad y luego muestrear a todos los estudiantes en esas clases seleccionadas.
Ventajas del muestreo en racimo:
- forma de muestreo más económica porque solo los racimos necesitan ser aleatorizados
- el estudio se puede completar en menos tiempo
- adecuado para la topografía de poblaciones que están divididas en racimos naturales
Desventajas del muestreo en racimo:
- la muestra puede no ser tan diversa como la población
- los clústeres pueden tener un sesgo similar, haciendo que la muestra esté sesgada
- menos precisión (mayor desviación estándar)
Ejemplo: Actitudes policiales
En 2017, Pew Research Center realizó una encuesta a 8000 policías llamada Behind the Badge. 52 El objetivo era aprovechar las actitudes y experiencias de los policías especialmente a la luz de los asesinatos altamente publicitados y polémicos de afroamericanos por parte de la policía.

Para realizar esta encuesta, los investigadores tuvieron que seleccionar departamentos de policía en todo el país que consideraran representativos de la población de departamentos. Después encuestaron a policías de esos departamentos. Un problema potencial reportado por los investigadores fue que solo se muestrearon departamentos de policía con al menos 100 oficiales. Este es un ejemplo de sesgo de similitud potencial que a veces surge en el muestreo de conglomerados.
Ejemplo: Estudiantes sin hogar 53
El Centro Bill Wilson del Condado de Santa Clara brinda servicios sociales para niños, adolescentes y adultos. En 2017, el centro realizó un estudio documentando a las poblaciones juveniles sin hogar, encuestando tanto a estudiantes de secundaria como a estudiantes de colegios comunitarios. 54

Para los estudiantes de colegios comunitarios, los investigadores eligieron dos colegios comunitarios de los ocho en el condado de Santa Clara y encuestaron a estudiantes desde el invierno de 2017 hasta la primavera de 2017. Un hallazgo fue que un asombroso 44% de los estudiantes de colegios comunitarios encuestados en estos dos colegios reportaron que no tenían hogar. (Sin hogar en este estudio significa vivir en la calle, vivir en autos o surfear en el sofá).
Este estudio es un ejemplo de muestreo por conglomerados. De los ocho colegios comunitarios del condado de Santa Clara, los investigadores eligieron 2. Aunque no se reportó en el estudio, sería importante que la demografía de los dos colegios elegidos coincidiera con el promedio de todos los estudiantes de colegios comunitarios en el condado.
Métodos de muestreo no probabilístico
Actualmente se están llevando a cabo métodos no científicos de muestreo que tienen sesgos inconmensurables y no deben ser utilizados en la investigación científica. La única ventaja de estos métodos es que son económicos y pueden generar muestras muy grandes. Sin embargo, estas muestras a menudo no lograrán crear una muestra representativa y, por lo tanto, no tendrán valor en la investigación. Peor aún, estas muestras sesgadas pueden presentarse como más precisas o mejores que los estudios científicos debido al gran tamaño de la muestra. Sin embargo, una muestra sesgada de cualquier tamaño tiene poco o ningún valor ‐‐ una gran pila de basura sigue siendo basura.
Muestreo Conveniente
Una muestra de conveniencia es simplemente una muestra de personas que son de fácil acceso.
Ejemplo: Uso de marihuana
Un estudiante de 21 años quiere realizar una encuesta sobre el consumo de marihuana. Pide a sus amigos en Facebook que llenen una encuesta. Los resultados de su encuesta muestran que 65% de los encuestados consumen frecuentemente marihuana.

Los amigos de Facebook del estudiante fueron fáciles de probar pero no son representativos de la población. Por ejemplo, si el estudiante usa frecuentemente marihuana, es más probable que sus amigos de Facebook también usen marihuana.
Muestreo Self‐seleccionado
Una muestra autoseleccionada es aquella en la que los participantes se ofrecen como voluntarios para ser muestreados. Esto incluiría encuestas por Internet y estudios que anuncian para voluntarios.
No confundir el muestreo autoseleccionado con estudios científicos que soliciten voluntarios de una muestra representativa inicial. Los investigadores se encargan de evitar sesgos asegurándose de que la demografía de los voluntarios coincida con la demografía de la muestra representativa.
Ejemplo: Boaty McBoatface
El Natural Environment Research Council (NERC), una agencia del gobierno británico, decidió dejar que Internet sugiriera un nombre para un barco de investigación polar de 287 millones de dólares. Un profesional de relaciones públicas y ex empleado de la BBC inició un frenesí en las redes sociales al sugerir que la gente votara por el nombre “Boaty McBoatface”. 55

El resultado final de esta encuesta autoseleccionada mostró que Boady McBoatface fue el ganador abrumador. Se puede ver que las 20 entradas principales incluyeron muchas otras opciones humorísticas, junto con algunos nombres más tradicionales. 56

El NERC finalmente eligió un nombre más serio, el RSS Sir David Attenborough, pero como consuelo para los votantes, la agencia nombró a un buque de investigación submarino operado a distancia Boty McBoatface. 57
Los resultados de la encuesta no reflejan lo que el público quería. Lo que pasó en cambio fue que muchas personas, a través de las redes sociales, se inspiraron para votar por Boady McBoatface como broma.
Ejemplo: Clasificaciones de películas en línea
Muchas personas utilizan los servicios de calificación en línea, como Google, Yelp, Rotten Tomatoes, IMDb y Rate My Professor para tomar decisiones sobre restaurantes, productos, servicios, películas o qué clase universitaria tomar.
Todos estos sistemas de calificaciones son ejemplos de muestreo autoseleccionado ya que los usuarios se ofrecen como voluntarios para escribir reseñas. Esto puede llevar a calificaciones que pueden ser extremadamente inexactas.
La Base de Datos de Películas en Internet (IMDb) mantiene críticas de películas y calificaciones de los usuarios. Las películas están calificadas en una escala de 1 (la peor) a 10 (la mejor). El 28 de julio de 2017 se estrenó “An Inconvenient Sequel: Truth to Power” de Al Gore como seguimiento de su documental original sobre el cambio climático, “An Inconvenient Truth”. La valoración general de IMDb para la película fue de 5.2, que es la media de todas las valoraciones de los usuarios.
El sitio web fivethirtyeight.com realizó un análisis de esta calificación general comparando “Una secuela incómoda” con otras películas con calificaciones similares. 58
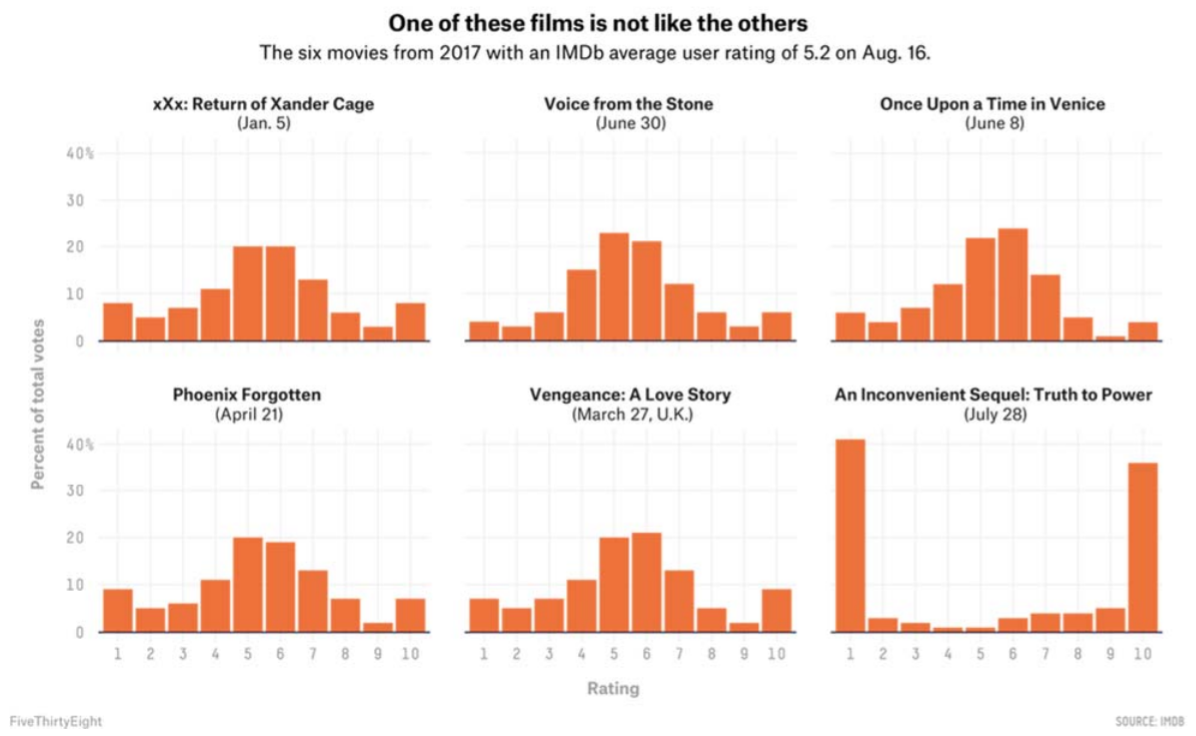
Es claro que la gráfica “Una secuela incómoda” fue muy diferente a las otras cinco películas con que también tuvieron una calificación promedio de 5.2; en este caso, la mayoría de la gente votó ya sea 1 o 10. El estudio fivethirtyeight.com también encontró que muchas de las críticas fueron escritas antes de la fecha de estreno de la película. Además, los críticos tradicionales calificaron la película mucho más alta. La calificación de IMDb en este caso no fue una verdadera calificación cinematográfica sino un intento de desacreditar o apoyar el cambio climático.
La conclusión de fivethirtyeight.com fue una advertencia sobre estos populares sistemas de clasificación en línea: “Di lo que quieras, pero además de ser polémico, “Una secuela incómoda” fue ambiciosa: Pocas películas involucran expediciones árticas, acceso interno a la Conferencia Climática de París, entrevistas con la sesión secretario de Estado y una mirada trotamundos a las condiciones climáticas catastróficas. Si las películas ambiciosas pero controvertidas se resumen a un solo número que las haga parecer idénticas a las películas mediocres, ¿qué incentivo tiene Hollywood para seguir invirtiendo en películas que desafían al público? “La democratización de las críticas cinematográficas ha sido uno de los cambios estructurales más sustanciales en el negocio cinematográfico en algún tiempo, pero hay efectos secundarios peligrosos. La gente que hace películas está aterrorizada. Las puntuaciones de IMDb representan a unos pocos miles de revisores en su mayoría hombres que podrían haber visto la película pero tal vez no, y están influyendo en el sistema de puntuación de uno de los sitios de entretenimiento más populares del planeta”.
Todos seguiremos utilizando los servicios de calificación en línea, pero debemos tener en cuenta que las críticas podrían ser falsas, manipuladas o extremadamente sesgadas.