
13.5: Comprensión de la Tabla ANOVA
- Page ID
- 151427

Al ejecutar Análisis de varianza, los datos generalmente se organizan en una tabla ANOVA especial, especialmente cuando se usa software de computadora.
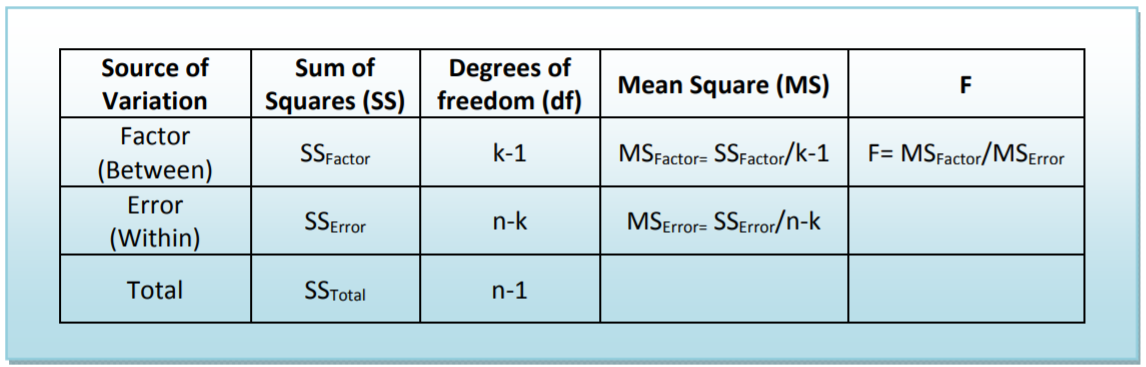
Suma de Cuadrados: La variabilidad total de los datos numéricos que se comparan se divide en la variabilidad entre grupos (\(\mathrm{SS}_{\text {Factor }}\)) y la variabilidad dentro de grupos (\(\mathrm{SS}_{\text {Error }}\)). Estas fórmulas son la parte más tediosa del cálculo. \(T_c\)representa la suma de los datos en cada población y\(n_c\) representa el tamaño muestral de cada población. Estas fórmulas representan el numerador de la fórmula de varianza.
\[\mathrm{SS}_{\text {Total }}=\Sigma\left(X^{2}\right)-\dfrac{(\Sigma X)^{2}}{n} \nonumber \]
\[\mathrm{SS}_{\text {Factor }}=\Sigma\left(\dfrac{T_{c}^{2}}{n_{c}}\right)-\dfrac{(\Sigma X)^{2}}{n} \nonumber \]
\[\mathrm{SS}_{\text {Error }}=\mathrm{SS}_{\text {Total }}-\mathrm{SS}_{\text {Factor }} \nonumber \]
Grados de libertad: Los grados totales de libertad también se dividen en los componentes Factor y Error.
Cuadrado medio: Esto representa el cálculo de la varianza dividiendo la Suma de Cuadrados por los grados de libertad apropiados.
\(\mathrm{F}\): Este es el estadístico de prueba para ANOVA: la relación de dos varianzas muestrales (cuadrados medios) que están estimando el mismo valor poblacional tiene una\(\mathrm{F}\) distribución. Los programas informáticos calcularán entonces el\(p\) ‐ valor que se utilizará para probar la Hipótesis Null de que todas las poblaciones tienen la misma media.
Party Pizza se especializa en comidas para estudiantes. Hsieh Li, presidente, desarrolló recientemente una nueva pizza de tofu.

Antes de hacerlo parte del menú regular decide probarlo en varios de sus restaurantes. A ella le gustaría saber si hay diferencia en el número medio de pizzas de tofu que se venden al día en las pizzerías Cupertino, San José y Santa Clara. Los datos se recopilarán durante cinco días en cada ubicación.
En el nivel de significancia .05 ¿puede Hsieh Li concluir que hay una diferencia en el número medio de pizzas de tofu que se venden al día en las tres pizzerías?
Solución
Diseño
Respuesta: pizzas de tofu vendidas
Factor: ubicación del restaurante
Niveles:\(k = 3\) (Cupertino, San Jose, Santa Clara)
Hipótesis de investigación:
\(H_o\): No hay diferencia en la media de pizzas de tofu vendidas debido a la ubicación del restaurante.
\(H_a\): Hay una diferencia en la media de pizzas de tofu vendidas debido a la ubicación del restaurante
\(H_o\):\(\mu_{1}=\mu_{2}=\mu_{3}\) (Las ventas medias son iguales en todos los restaurantes)
\(H_a\): Al menos\(\mu_{i}\) es diferente (Significa que las ventas no son las mismas en todos los restaurantes)
Supondremos que las varianzas poblacionales son iguales\(\sigma_{1}^{2}=\sigma_{2}^{2}=\sigma_{3}^{2}\), por lo que el modelo será ANOVA de un factor. Este modelo es apropiado si la distribución de las medias de la muestra es aproximadamente Normal a partir del Teorema del Límite Central.
El error de tipo I sería rechazar la Hipótesis Null y afirmar que las ventas medias son diferentes, cuando en realidad son las mismas. La prueba se ejecutará a un nivel de significancia (\(\alpha\)) del 5%.
El estadístico de prueba de la tabla será\(\mathrm{F}=\dfrac{\mathrm {MS}_\text{Factor }}{\mathrm {MS}_\text{Error }}\). Los grados de libertad para el numerador serán 3‐1=2, y los grados de libertad para denominador serán 13‐3=10. (El tamaño total de la muestra resultó ser solo 13, no 15 según lo planeado).
Valor Crítico para\(\mathrm{F}\) a\(\alpha\) de 5% con\(\mathrm{df}_{\text {num }}=2\) y\(\mathrm{df}_{\text {den }}=10\) es 4.10. Rechazar\(H_o\) si\(\mathrm{F}\) >4.10. También realizaremos esta prueba usando el método p‐value con software estadístico, como Minitab.
Datos/Resultados
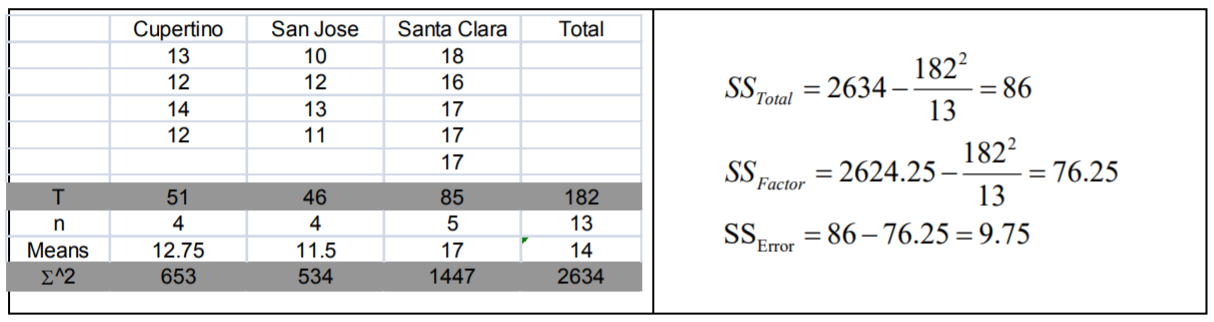
\(\mathrm{F}=38.125 / 0.975=39.10\), que es más que el valor crítico de 4.10, así que rechace\(H_o\). También a partir de la salida de Minitab,\(p\) ‐value = 0.000 < 0.05 que también soporta rechazo\(H_o\).
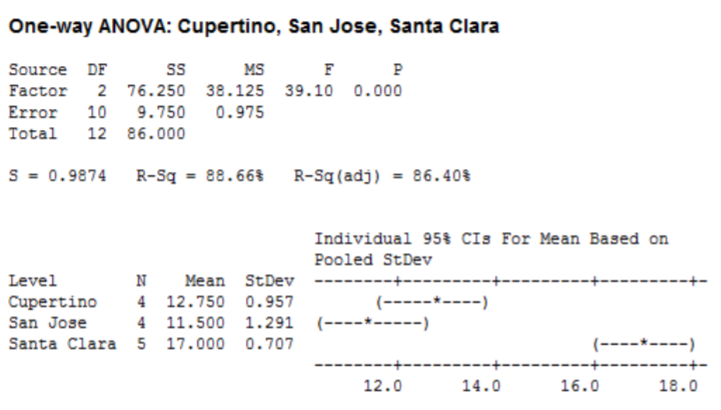
Conclusión
Hay una diferencia en el número medio de pizzas de tofu vendidas en las tres ubicaciones.