
14.1: Introducción a la Regresión Lineal
- Page ID
- 152312

Objetivos de aprendizaje
- Identificar errores de predicción en un diagrama de dispersión con una línea de regresión
En regresión lineal simple, predecimos puntuaciones en una variable a partir de las puntuaciones en una segunda variable. La variable que estamos prediciendo se llama la variable criterio y se la conoce como\(Y\). La variable en la que basamos nuestras predicciones se llama variable predictora y se la denomina\(X\). Cuando solo hay una variable predictora, el método de predicción se llama regresión simple. En regresión lineal simple, el tema de esta sección, las predicciones de\(Y\) cuando se trazan en función de\(X\) formar una línea recta.
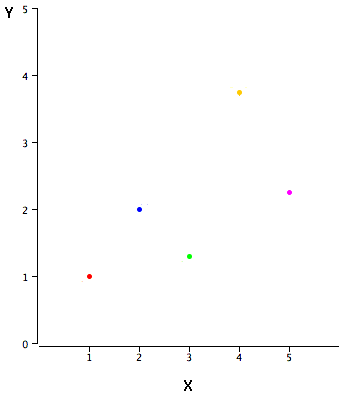
Los datos de ejemplo en la Tabla\(\PageIndex{1}\) se representan en la Figura\(\PageIndex{1}\). Se puede ver que existe una relación positiva entre\(X\) y\(Y\). Si fueras a predecir\(Y\) desde\(X\), cuanto mayor sea el valor de\(X\), mayor será tu predicción de\(Y\).
| X | Y |
|---|---|
| 1.00 | 1.00 |
| 2.00 | 2.00 |
| 3.00 | 1.30 |
| 4.00 | 3.75 |
| 5.00 | 2.25 |
La regresión lineal consiste en encontrar la línea recta que mejor se ajuste a través de los puntos. La línea de mejor ajuste se llama línea de regresión. La línea diagonal negra en la Figura\(\PageIndex{2}\) es la línea de regresión y consiste en la puntuación predicha\(Y\) para cada valor posible de\(X\). Las líneas verticales desde los puntos hasta la línea de regresión representan los errores de predicción. Como puede ver, el punto rojo está muy cerca de la línea de regresión; su error de predicción es pequeño. Por el contrario, el punto amarillo es mucho mayor que la línea de regresión y por lo tanto su error de predicción es grande.
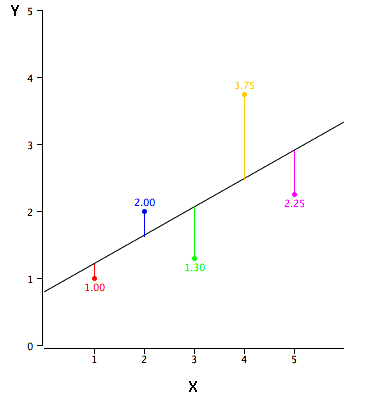
El error de predicción para un punto es el valor del punto menos el valor predicho (el valor en la línea). En la tabla se\(\PageIndex{2}\) muestran los valores predichos (\(Y'\)) y los errores de predicción (\(Y-Y'\)). Por ejemplo, el primer punto tiene un\(Y\) de\(1.00\) y un predicho\(Y\) (llamado\(Y'\)) de\(1.21\). Por lo tanto, su error de predicción es\(-0.21\).
| X | Y | Y' | Y-Y' | (Y-Y') 2 |
|---|---|---|---|---|
| 1.00 | 1.00 | 1.210 | -0.210 | 0.044 |
| 2.00 | 2.00 | 1.635 | 0.365 | 0.133 |
| 3.00 | 1.30 | 2.060 | -0.760 | 0.578 |
| 4.00 | 3.75 | 2.485 | 1.265 | 1.600 |
| 5.00 | 2.25 | 2.910 | -0.660 | 0.436 |
Es posible que hayas notado que no especificamos qué se entiende por “línea de mejor ajuste”. De lejos, el criterio más utilizado para la línea de mejor ajuste es la línea que minimiza la suma de los errores cuadrados de predicción. Ese es el criterio que se utilizó para encontrar la línea en la Figura\(\PageIndex{2}\). La última columna de la Tabla\(\PageIndex{2}\) muestra los errores cuadrados de predicción. La suma de los errores cuadrados de predicción que se muestran en la Tabla\(\PageIndex{2}\) es menor de lo que sería para cualquier otra línea de regresión.
La fórmula para una línea de regresión es
\[Y' = bX + A\]
donde\(Y'\) está la puntuación predicha,\(b\) es la pendiente de la línea, y\(A\) es la\(Y\) intersección. La ecuación para la línea en la Figura\(\PageIndex{2}\) es
\[Y' = 0.425X + 0.785\]
Para\(X = 1\),
\[Y' = (0.425)(1) + 0.785 = 1.21\]
Para\(X = 2\),
\[Y' = (0.425)(2) + 0.785 = 1.64\]
Computación de la línea de regresión
En la era de las computadoras, la línea de regresión se computa típicamente con software estadístico. No obstante, los cálculos son relativamente fáciles, y se dan aquí para cualquiera que esté interesado. Los cálculos se basan en las estadísticas que se muestran en la Tabla\(\PageIndex{3}\). \(M_X\)es la media de\(X\),\(M_Y\) es la media de\(Y\),\(s_X\) es la desviación estándar de\(X\),\(s_Y\) es la desviación estándar de\(Y\), y\(r\) es la correlación entre\(X\) y\(Y\).
Fórmula para desviación estándar
Fórmula para correlación
| M X | M Y | s X | s Y | r |
|---|---|---|---|---|
| 3 | 2.06 | 1.581 | 1.072 | 0.627 |
La pendiente (\(b\)) se puede calcular de la siguiente manera:
\[b = r \frac{s_Y}{s_X}\]
y la intercepción (\(A\)) se puede calcular como
\[A = M_Y - bM_X\]
Para estos datos,
\[b = \frac{(0.627)(1.072)}{1.581} = 0.425\]
\[A = 2.06 - (0.425)(3) = 0.785\]
Tenga en cuenta que todos los cálculos se han mostrado en términos de estadísticas de muestra en lugar de parámetros de población. Las fórmulas son las mismas; simplemente use los valores de los parámetros para las medias, las desviaciones estándar y la correlación.
Variables estandarizadas
La ecuación de regresión es más simple si las variables están estandarizadas de manera que sus medias sean iguales a\(0\) y las desviaciones estándar sean iguales a\(1\), para entonces\(b = r\) y\(A = 0\). Esto hace que la línea de regresión:
\[Z_{Y'} = (r)(Z_X)\]
donde\(Z_{Y'}\) está la puntuación estándar predicha para\(Y\),\(r\) es la correlación, y\(Z_X\) es la puntuación estandarizada para\(X\). Tenga en cuenta que la pendiente de la ecuación de regresión para las variables estandarizadas es\(r\).
Un verdadero ejemplo
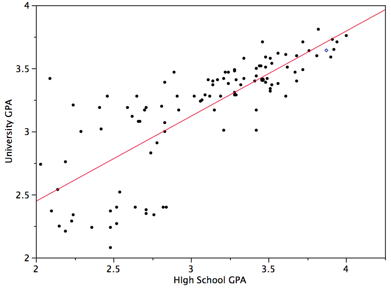
El estudio de caso “SAT y Colegio GPA” contiene calificaciones de secundaria y universidad para especializaciones en ciencias de la\(105\) computación en una escuela estatal local. Ahora consideramos cómo podríamos predecir el GPA universitario de un estudiante si conociéramos su GPA de secundaria.
La figura\(\PageIndex{3}\) muestra un diagrama de dispersión del GPA universitario en función del GPA de secundaria. Se puede ver por la figura que existe una fuerte relación positiva. La correlación es\(0.78\). La ecuación de regresión es:
\[\text{University GPA'} = (0.675)(\text{High School GPA}) + 1.097\]
Por lo tanto, un estudiante con un GPA de preparatoria de se\(3\) predeciría tener un GPA universitario de
\[\text{University GPA'} = (0.675)(3) + 1.097 = 3.12\]
Supuestos
Puede que te sorprenda, pero los cálculos que se muestran en esta sección están libres de suposiciones. Por supuesto, si la relación entre\(X\) y no\(Y\) fuera lineal, una función de forma diferente podría ajustarse mejor a los datos. Las estadísticas inferenciales en regresión se basan en varios supuestos, y estos supuestos se presentan en una sección posterior de este capítulo.