
10.5: Muestras emparejadas o emparejadas
- Page ID
- 153311

Al utilizar una prueba de hipótesis para muestras emparejadas o pareadas, deben estar presentes las siguientes características:
- Se utiliza muestreo aleatorio simple.
- Los tamaños de las muestras suelen ser pequeños.
- Se extraen dos medidas (muestras) del mismo par de individuos u objetos.
- Las diferencias se calculan a partir de las muestras emparejadas o pareadas.
- Las diferencias forman la muestra que se utiliza para la prueba de hipótesis.
- O bien los pares emparejados tienen diferencias que provienen de una población que es normal o el número de diferencias es suficientemente grande para que la distribución de la media muestral de diferencias sea aproximadamente normal.
En una prueba de hipótesis para muestras emparejadas o pareadas, los sujetos se emparejan en pares y se calculan las diferencias. Las diferencias son los datos. La media poblacional para las diferencias\(\mu_{d}\),, se prueba luego usando una\(t\) prueba de Student para una sola media poblacional con\(n - 1\) grados de libertad, donde\(n\) está el número de diferencias.
El estadístico de prueba (\(t\)-score) es:
\[t = \dfrac{\bar{x}_{d} - \mu_{d}}{\left(\dfrac{s_{d}}{\sqrt{n}}\right)}\]
Ejemplo\(\PageIndex{1}\)
Se realizó un estudio para investigar la efectividad del hipnotismo en la reducción del dolor. Los resultados para sujetos seleccionados al azar se muestran en la Tabla. Una puntuación más baja indica menos dolor. El valor “antes” se corresponde con un valor “después” y se calculan las diferencias. Las diferencias tienen una distribución normal. ¿Las mediciones sensoriales son, en promedio, menores después del hipnotismo? Prueba a un nivel de significancia del 5%.
| Sujeto: | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| Antes | 6.6 | 6.5 | 9.0 | 10.3 | 11.3 | 8.1 | 6.3 | 11.6 |
| Después | 6.8 | 2.4 | 7.4 | 8.5 | 8.1 | 6.1 | 3.4 | 2.0 |
Contestar
Los valores correspondientes “antes” y “después” forman pares coincidentes. (Calcular “después” — “antes”.)
| Después de los datos | Antes de los datos | Diferencia |
|---|---|---|
| 6.8 | 6.6 | 0.2 |
| 2.4 | 6.5 | -4.1 |
| 7.4 | 9 | -1.6 |
| 8.5 | 10.3 | -1.8 |
| 8.1 | 11.3 | -3.2 |
| 6.1 | 8.1 | -2 |
| 3.4 | 6.3 | -2.9 |
| 2 | 11.6 | -9.6 |
Los datos para la prueba son las diferencias:\(\{0.2, -4.1, -1.6, -1.8, -3.2, -2, -2.9, -9.6\}\)
La media muestral y la desviación estándar muestral de las diferencias son:\(\bar{x}_{d} = -3.13\) y\(s_{d} = 2.91\) Verificar estos valores.
\(\mu_{d}\)Sea la media poblacional para las diferencias. Usamos el subíndice dd para denotar “diferencias”.
Variable aleatoria:
\(\bar{X}_{d} =\)la diferencia media de las mediciones sensoriales
\[H_{0}: \mu_{d} \geq 0\]
La hipótesis nula es cero o positiva, es decir, que hay el mismo o más dolor que se siente después del hipnotismo. Eso significa que el sujeto no muestra mejoría. \(\mu_{d}\)es la media poblacional de las diferencias.
\[H_{a}: \mu_{d} < 0\]
La hipótesis alternativa es negativa, lo que significa que se siente menos dolor después del hipnotismo. Eso significa que el sujeto muestra mejoría. El puntaje debe ser menor después del hipnotismo, por lo que la diferencia debe ser negativa para indicar mejoría.
Distribución para la prueba:
La distribución es una t de Student con\(df = n - 1 = 8 - 1 = 7\). Uso\(t_{7}\). (Observe que la prueba es para una sola media poblacional.)
Calcular el valor p usando la distribución Student-T:
\[p\text{-value} = 0.0095\]
Gráfica:
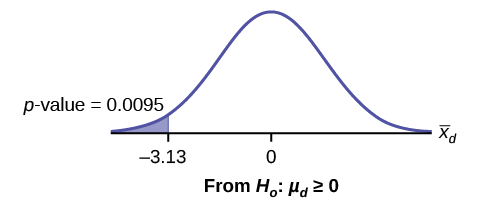
\(\bar{X}_{d}\)es la variable aleatoria para las diferencias.
La media muestral y la desviación estándar muestral de las diferencias son:
\(\bar{x}_{d} = -3.13\)
\(s_{d} = 2.91\)
Compare\(\alpha\) y el\(p\text{-value}\)
\(\alpha = 0.05\)y\(p\text{-value} = 0.0095\). \(\alpha > p\text{-value}\)
Tomar una decisión
Ya que\(\alpha > p\text{-value}\), rechazar\(H_{0}\). Esto significa que\(\mu_{d} < 0\) y hay mejoría.
Conclusión
A un nivel de significancia del 5%, a partir de los datos de la muestra, hay evidencia suficiente para concluir que las mediciones sensoriales, en promedio, son menores después del hipnotismo. El hipnotismo parece ser efectivo para reducir el dolor.
Para las calculadoras TI-83+ y TI-84, puede calcular las diferencias antes de tiempo (después - antes) y poner las diferencias en una lista o puede poner los datos posteriores en una primera lista y los datos antes en una segunda lista. Después ve a una tercera lista y flecha hacia arriba al nombre. Ingrese el primer nombre de la lista - el segundo nombre de la lista. La calculadora hará la resta, y tendrás las diferencias en la tercera lista.
Usa tu lista de diferencias como datos. Presiona STAT y flecha hacia PRUEBAS. Presione 2:T-Test. Flecha la flecha hacia Datos y presiona ENTRAR. Flecha hacia abajo e ingresa 0 para\(\mu_{0}\), el nombre de la lista donde pones los datos, y 1 para Freq:. Flecha hacia abajo a \(\mu\): y flecha sobre <\(\mu_{0}\). Presione ENTER. Flecha hacia abajo para Calcular y presiona ENTRAR. El\(p\text{-value}\) es 0.0094, y el estadístico de prueba es -3.04. Vuelva a hacer estas instrucciones excepto, flecha para Dibujar (en lugar de Calcular). Presione ENTER.
Ejercicio\(\PageIndex{1}\)
Se realizó un estudio para investigar qué tan efectiva fue una nueva dieta para disminuir el colesterol. Los resultados para los sujetos seleccionados al azar se muestran en la tabla. Las diferencias tienen una distribución normal. ¿Los niveles de colesterol de los sujetos son más bajos en promedio después de la dieta? Prueba al nivel del 5%.
| Sujeto | A | B | C | D | E | F | G | H | I |
|---|---|---|---|---|---|---|---|---|---|
| Antes | 209 | 210 | 205 | 198 | 216 | 217 | 238 | 240 | 222 |
| Después | 199 | 207 | 189 | 209 | 217 | 202 | 211 | 223 | 201 |
Contestar
El\(p\text{-value}\) es 0.0130, por lo que podemos rechazar la hipótesis nula. Hay evidencia suficiente para sugerir que la dieta disminuye el colesterol.
Ejemplo\(\PageIndex{2}\)
Un entrenador de fútbol universitario estaba interesado en saber si la clase de desarrollo de fuerza de la universidad aumentaba la elevación máxima de sus jugadores (en libras) en el ejercicio de press de banca. Pidió a cuatro de sus jugadores participar en un estudio. La cantidad de peso que podían cada levantamiento se registró antes de tomar la clase de desarrollo de fuerza. Después de completar la clase, se volvió a medir la cantidad de peso que podían cada levantamiento. Los datos son los siguientes:
| Peso (en libras) | Jugador 1 | Jugador 2 | Jugador 3 | Jugador 4 |
|---|---|---|---|---|
| Cantidad de peso levantada antes de la clase | 205 | 241 | 338 | 368 |
| Cantidad de peso levantada después de la clase | 295 | 252 | 330 | 360 |
El entrenador quiere saber si la clase de desarrollo de fuerza fortalece a sus jugadores, en promedio.
Registrar los datos de diferencias. Calcular las diferencias restando la cantidad de peso levantado antes de la clase del peso levantado después de completar la clase. Los datos para las diferencias son:\(\{90, 11, -8, -8\}\). Supongamos que las diferencias tienen una distribución normal.Utilizando los datos de diferencias, se calcula la media de la muestra y la desviación estándar de la muestra.
\[\bar{x}_{d} = 21.3\]
y
\[s_{d} = 46.7\]
Los datos que se dan aquí indicarían que la distribución en realidad está sesgada a la derecha. ¿La diferencia 90 puede ser un valor atípico extremo? Se está tirando de la media de la muestra para que sea 21.3 (positivo). Las medias de los otros tres valores de datos son en realidad negativas.
Usando los datos de diferencia, esto se convierte en una prueba de un solo __________ (rellena el espacio en blanco).
Definir la variable aleatoria: diferencia\(\bar{X}\) media en la elevación máxima por jugador.
La distribución para la prueba de hipótesis es\(t_{3}\).
- \(H_{0}: \mu_{d} \leq 0\),
- \(H_{a}: \mu_{d} > 0\)
Gráfica:
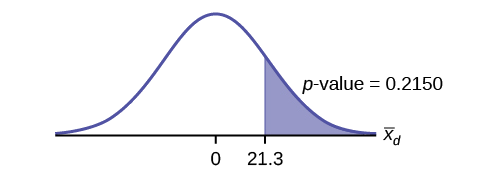
Calcular el\(p\text{-value}\): El\(p\text{-value}\) es 0.2150
Decisión: Si el nivel de significancia es del 5%, la decisión no es rechazar la hipótesis nula, porque\(\alpha < p\text{-value}\).
¿Cuál es la conclusión?
A un nivel de significancia del 5%, a partir de los datos de la muestra, no hay evidencia suficiente para concluir que la clase de desarrollo de la fuerza ayudó a hacer más fuertes a los jugadores, en promedio.
Ejercicio\(\PageIndex{2}\)
Se diseñó una nueva clase preparatoria para mejorar los puntajes de los exámenes SAT. Cinco estudiantes fueron seleccionados al azar. Se registraron sus puntajes en dos exámenes de práctica, uno antes de la clase y otro después. Los datos registrados en la Tabla. ¿Los puntajes, en promedio, son más altos después de la clase? Prueba a un nivel del 5%.
| Puntuaciones SAT | Alumno 1 | Alumno 2 | Alumno 3 | Alumno 4 |
|---|---|---|---|---|
| Puntuación antes de clase | 1840 | 1960 | 1920 | 2150 |
| Puntuación después de clase | 1920 | 2160 | 2200 | 2100 |
Contestar
El\(p\text{-value}\) es 0.0874, por lo que declinamos rechazar la hipótesis nula. Los datos no respaldan que la clase mejore significativamente los puntajes del SAT.
Ejemplo\(\PageIndex{3}\)
Siete alumnos de octavo grado en Kennedy Middle School midieron hasta dónde podían empujar el shot-put con su mano dominante (escritura) y su mano más débil (que no escribía). Pensaron que podían empujar distancias iguales con cualquiera de las dos manos. Los datos fueron colectados y registrados en la Tabla.
| Distancia (en pies) usando | Alumno 1 | Alumno 2 | Alumno 3 | Alumno 4 | Alumno 5 | Alumno 6 | Alumno 7 |
|---|---|---|---|---|---|---|---|
| Mano Dominante | 30 | 26 | 34 | 17 | 19 | 26 | 20 |
| Mano más débil | 28 | 14 | 27 | 18 | 17 | 26 | 16 |
Realizar una prueba de hipótesis para determinar si la diferencia media en las distancias entre las manos dominantes y débiles de los niños es significativa.
Registrar los datos de diferencias. Calcula las diferencias restando las distancias con la mano más débil de las distancias con la mano dominante. Los datos para las diferencias son:\(\{2, 12, 7, –1, 2, 0, 4\}\). Las diferencias tienen una distribución normal.
Utilizando los datos de diferencias, se calcula la media de la muestra y la desviación estándar de la muestra. \(\bar{x} = 3.71\),\(s_{d} = 4.5\).
Variable aleatoria: diferencia\(\bar{X} =\) media en las distancias entre las manos.
Distribución para la prueba de hipótesis:\(t_{6}\)
\(H_{0}: \mu_{d} = 0 H_{a}: \mu_{d} \neq 0\)
Gráfica:
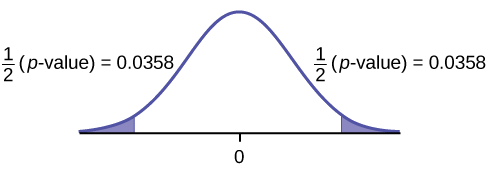
Calcular el valor p: El\(p\text{-value}\) es 0.0716 (usando los datos directamente).
(estadística de prueba = 2.18. \(p\text{-value} = 0.0719\)usando\((\bar{x}_{d} = 3.71, s_{d} = 4.5\).
Decisión: Asumir\(\alpha = 0.05\). Ya que\(\alpha < p\text{-value}\), no rechace\(H_{0}\).
Conclusión: En el nivel de significancia del 5%, a partir de los datos de la muestra, no hay evidencia suficiente para concluir que existe una diferencia en las manos más débiles y dominantes de los niños para empujar el shot-put.
Ejercicio\(\PageIndex{3}\)
Cinco jugadores de pelota piensan que pueden lanzar la misma distancia con su mano dominante (lanzamiento) y fuera de la mano (mano de captura). Los datos fueron colectados y registrados en la Tabla. Realizar una prueba de hipótesis para determinar si la diferencia media en las distancias entre el dominante y el off-hand es significativa. Prueba al nivel del 5%.
| Jugador 1 | Jugador 2 | Jugador 3 | Jugador 4 | Jugador 5 | |
|---|---|---|---|---|---|
| Mano Dominante | 120 | 111 | 135 | 140 | 125 |
| Fuera de la mano | 105 | 109 | 98 | 111 | 99 |
Contestar
El\(p\text{-level}\) es 0.0230, por lo que podemos rechazar la hipótesis nula. Los datos muestran que los jugadores no lanzan la misma distancia con sus off-hands como lo hacen con sus manos dominantes.
Revisar
Una prueba de hipótesis para muestras emparejadas o pareadas (prueba t) tiene estas características:
- Probar las diferencias restando una medición de la otra
- Variable aleatoria:\(x_{d} =\) media de las diferencias
- Distribución: Distribución t estudiantil con\(n - 1\) grados de libertad
- Si el número de diferencias es pequeño (menor a 30), las diferencias deben seguir una distribución normal.
- Se extraen dos muestras del mismo conjunto de objetos.
- Las muestras son dependientes.
Revisión de Fórmula
Estadística de prueba (t -score):\[t = \dfrac{\bar{x}_{d}}{\left(\dfrac{s_{d}}{\sqrt{n}}\right)}\]
donde:
\(x_{d}\)es la media de las diferencias muestrales. \(\mu_{d}\)es la media de las diferencias poblacionales. \(s_{d}\)es la desviación estándar muestral de las diferencias. \(n\)es el tamaño de la muestra.