
2.2: Medidas de Ubicación Central - Tres Tipos de Promedios
- Page ID
- 151122
Objetivos de aprendizaje
- Aprender el concepto de “centro” de un conjunto de datos.
- Aprender el significado de cada una de las tres medidas del centro de un conjunto de datos (la media, la mediana y el modo) y cómo calcular cada una.
Esta sección se titula “tres tipos de promedios” porque cualquier tipo de promedio podría utilizarse para responder a la pregunta “¿dónde está el centro de los datos?”. Veremos que la naturaleza del conjunto de datos, como lo indica un histograma de frecuencia relativa, determinará qué constituye una buena respuesta. Diferentes formas del histograma requieren diferentes medidas de ubicación central.
La Media
La primera medida de ubicación central es el “promedio” habitual que es familiar para todos: sumar todos los valores, luego dividir por el número de valores. Antes de escribir una fórmula para la media, introduzcamos alguna notación matemática práctica.
anotaciones:\(\sum \) "sum" and \(n\) "sample size"
La letra griega\(\sum \), pronunciada “sigma”, es una práctica taquigrafía matemática que significa “sumar todos los valores” o “suma”. Por ejemplo\(\sum x\) significa “sumar todos los valores de\(x\) “, y\(\sum x^2\) significa “sumar todos los valores de\(x^2\)”. En estas expresiones\(x\) suele representar un valor de los datos, por lo que\(\sum x\) significa “la suma de todos los valores de datos” y\(\sum x^2\) significa “la suma de los cuadrados de todos los valores de datos”.
\(\mathbf{n}\)representa el tamaño de la muestra, el número de valores de datos. Un ejemplo ayudará a dejar esto claro.
Ejemplo\(\PageIndex{1}\)
Buscar\(n\),\(\sum x\),\(\sum x^2\) y\(\sum (x - 1)^2\) para los datos:
\[1,\, 3,\, 4 \nonumber\]
Solución:
\[\begin{array}{rcl} n & = & 3 \quad \mbox{ because there are three data values} \\ \sum x & = & 1 + 3 + 4 = 8 \\ \sum x^2 & = & 1^2 + 3^2 + 4^2 = 1 + 9 + 16 = 26 \\ \sum {(x - 1)}^2 & = & {(1 - 1)}^2 + {(3 - 1)}^2 + {(4 - 1)}^2 = 0^2 + 2^2 + 3^2 = 13\end{array} \nonumber\]
Usando estas anotaciones prácticas es fácil escribir una fórmula que defina la media\(\bar{x}\) of a sample.
Definición: Media de la Muestra
La media muestral de un conjunto de valores de datos de\(n\) muestra es el número\(\bar x\) definido por la fórmula
\[\bar x = \dfrac{\sum x}{n} \label{samplemean}\]
Ejemplo\(\PageIndex{2}\)
Encuentre la media de los siguientes datos de muestra:\(2\)\(-1\),\(0\),\(2\)
Solución
Esta es una aplicación de la ecuación\ ref {samplemean}:
\[\bar x = \dfrac{\sum x}{n} = \dfrac{2 + (-1) + 0 + 2}{4} = \dfrac{3}{4} = 0.75 \nonumber\]
Ejemplo\(\PageIndex{3}\)
Se toma una muestra aleatoria de diez alumnos del cuerpo estudiantil de una universidad y sus GPA se registran de la siguiente manera:
\[1.90, 3.00, 2.53, 3.71, 2.12, 1.76, 2.71, 1.39, 4.00, 3.33\nonumber \]
Encuentra la media.
Solución
Esta es una aplicación de la ecuación\ ref {samplemean}:
\[\begin{array}{rcl}\bar x = \dfrac{\sum x}{n} = \dfrac{1.90 + 3.00 + 2.53 + 3.71 + 2.12 + 1.76 + 2.71 + 1.39 + 4.00 + 3.33}{10} = \dfrac{26.45}{10} = 2.645\end{array} \nonumber\]
Ejemplo\(\PageIndex{4}\)
Una muestra aleatoria de\(19\) mujeres más allá de la edad fértil dio los siguientes datos, donde\(x\) está el número de hijos y\(f\) es la frecuencia, o el número de veces que ocurrió en el conjunto de datos.
\[\begin{array}{c|cccc}x & 0 & 1 & 2 & 3 & 4 \\ \hline f & 3 & 6 & 6 & 3 & 1\end{array} \nonumber\]
Encuentra la media de la muestra.
Solución
En este ejemplo los datos se presentan mediante una tabla de frecuencias de datos, introducida en el Capítulo 1. Cada número en la primera línea de la tabla es un número que aparece en el conjunto de datos; el número debajo de él es cuántas veces ocurre. Así el valor\(0\) se observa tres veces, es decir, tres de las mediciones en el conjunto de datos son\(0\), el valor\(1\) se observa seis veces, y así sucesivamente. En el contexto del problema esto significa que tres mujeres de la muestra no han tenido hijos, seis han tenido exactamente un hijo, y así sucesivamente. La lista explícita de todas las observaciones en este conjunto de datos es, por lo tanto:
\[0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 4 \nonumber \]
El tamaño de la muestra se puede leer directamente de la tabla, sin antes enumerar todo el conjunto de datos, como la suma de las frecuencias:\(n = 3 + 6 + 6 + 3 + 1 = 19\). La media de la muestra también se puede calcular directamente a partir de la tabla:
\[\bar x = \dfrac{\sum x}{n} = \dfrac{0 \times 3 + 1 \times 6 + 2 \times 6 + 3 \times 3 + 4 \times 1}{19} = \dfrac{31}{19} = 1.6316 \nonumber\]
En los ejemplos anteriores los conjuntos de datos se describieron como muestras. Por lo tanto, las medias fueron medias muestrales\(\bar x\). Si los datos provienen de un censo, de manera que hay una medición para cada elemento de la población, entonces la media se calcula exactamente por el mismo proceso de sumar todas las mediciones y dividirlas por cuántas de ellas hay, pero ahora es la media poblacional y se denota por \(\mu\), la letra griega minúscula mu.
Definición: Media poblacional
La media poblacional de un conjunto de datos\(N\) poblacionales es el número\(\mu\) definido por la fórmula:
\[\displaystyle \mu=\frac{\sum x}{N}.\]
La media de dos números es el número que se encuentra a medio camino entre ellos. Por ejemplo, el promedio de los números\(5\) y\(17\) es\((5 + 17) ∕ 2 = 11\), que es\(6\) unidades arriba\(5\) y\(6\) unidades por debajo\(17\). En este sentido el promedio\(11\) es el “centro” del conjunto de datos\(\{5,17\}\). Para conjuntos de datos más grandes, la media puede considerarse de manera similar como el “centro” de los datos.
La mediana
Para ver por qué se necesita otro concepto de promedio, considere la siguiente situación. Supongamos que estamos interesados en el ingreso promedio anual de los empleados de una gran corporación. Tomamos una muestra aleatoria de siete empleados, obteniendo los datos de la muestra (redondeados a los cien dólares más cercanos, y expresados en miles de dólares).
\[24.8, 22.8, 24.6, 192.5, 25.2, 18.5, 23.7\]
La media (redondeada a un decimal) es\(\bar x = 47.4\), pero la declaración “el ingreso promedio de los empleados en esta corporación es\($47,400\)” seguramente es engañosa. Es aproximadamente el doble de lo que hacen seis de los siete empleados de la muestra y no está ni cerca de lo que hace ninguno de ellos. Es fácil ver qué salió mal: la presencia del único ejecutivo en la muestra, cuyo salario es tan grande comparado con el de todos los demás, provocó que el numerador en la fórmula para la media de la muestra fuera demasiado grande, tirando la media lejos a la derecha de donde pensamos que el promedio “debería” estar, es decir, alrededor \($24,000\)o\($25,000\). El número\(192.5\) en nuestro conjunto de datos se llama un valor atípico, un número que está muy alejado de la mayoría o de todas las mediciones restantes. Muchas veces un valor atípico es el resultado de algún tipo de error, pero no siempre, como es el caso aquí. Obtendríamos una mejor medida del “centro” de los datos si tuviéramos que organizar los datos en orden numérico:
\[18.5, 22.8, 23.7, 24.6, 24.8, 25.2, 192.5\]
después seleccione el número medio en la lista, en este caso\(24.6\). El resultado se llama la mediana del conjunto de datos, y tiene la propiedad de que aproximadamente la mitad de las mediciones son más grandes de lo que es, y aproximadamente la mitad son más pequeñas. En este sentido localiza el centro de los datos. Si hay un número par de mediciones en el conjunto de datos, entonces habrá dos elementos medios cuando todos estén alineados en orden, así que tomamos la media de los dos medios como la mediana. Así tenemos la siguiente definición.
Definición: Mediana de la muestra
La mediana \(\tilde{x}\)de la muestra de un conjunto de datos de muestra para los que hay un número impar de mediciones es la medida media cuando los datos están dispuestos en orden numérico.
La mediana muestral de un conjunto de datos de muestra para los que hay un número par de mediciones, es la media de las dos mediciones medias cuando los datos están dispuestos en orden numérico.
Definición: Mediana de la población
La mediana poblacional se define de la misma manera que la mediana muestral excepto para toda la población.
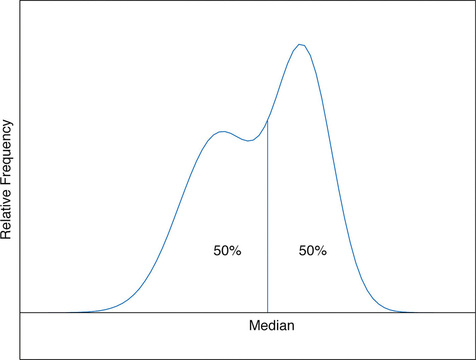
La mediana es un valor que divide las observaciones en un conjunto de datos de manera que el\(50\%\) de los datos se encuentra a su izquierda y\(50\%\) el otro a su derecha. De acuerdo con la Figura\(\PageIndex{7}\), por lo tanto, en la curva que representa la distribución de los datos, una línea vertical dibujada en la mediana divide el área en dos, área\(0.5\) (\(50\%\)del área total\(1\)) a la izquierda y área\(0.5\) (\(50\%\)del área total\(1\)) a la derecha, como se muestra en la Figura\(\PageIndex{1}\). En nuestro ejemplo de ingresos la mediana\($24,600\),, claramente dio una medida mucho mejor de la mitad del conjunto de datos que la media\($47,400\). Esto es típico para situaciones en las que la distribución está sesgada. (La asimetría y la simetría de las distribuciones se discuten al final de esta subsección.)
Ejemplo\(\PageIndex{5}\)
Calcular la mediana de la muestra para los datos de Ejemplo\(\PageIndex{2}\)
Solución:
Los datos en orden numérico son\(−1, 0, 2, 2\). Las dos medidas medias son\(0\) y\(2\), entonces\(\tilde{x}= (0+2)/2 = 1\).
Ejemplo\(\PageIndex{6}\)
Calcular la mediana de la muestra para los datos de Ejemplo\(\PageIndex{3}\)
Solución
Los datos en orden numérico son
El número de observaciones es de diez, lo que es par, por lo que hay dos medidas medias, la quinta y la sexta, que son\(2.53\) y\(2.71\). Por lo tanto, la mediana de estos datos es\(\tilde{x} = (2.53+2.71)/2 = 2.62\).
Ejemplo\(\PageIndex{7}\)
Calcular la mediana de la muestra para los datos de Ejemplo\(\PageIndex{4}\)
Solución
Los datos en orden numérico son:
El número de observaciones es\(19\), lo cual es impar, por lo que hay una medida media, la décima. Dado que la décima medida es\(2\), la mediana es\(\tilde{x} = 2\).
En el último ejemplo es importante señalar que podríamos haber calculado la mediana directamente a partir de la tabla de frecuencias, sin antes enumerar explícitamente todas las observaciones en el conjunto de datos. Ya vimos en Ejemplo\(\PageIndex{4}\) cómo encontrar el número de observaciones directamente a partir de las frecuencias listadas en la tabla\(n = 3+6+6+3+1 = 19\). Así, la mediana es la décima observación. La segunda línea de la tabla en Ejemplo\(\PageIndex{4}\) muestra que cuando los datos se listan en orden habrá tres\(0s\) seguidos de seis\(1s\), por lo que la décima observación, la mediana, es\(2\).
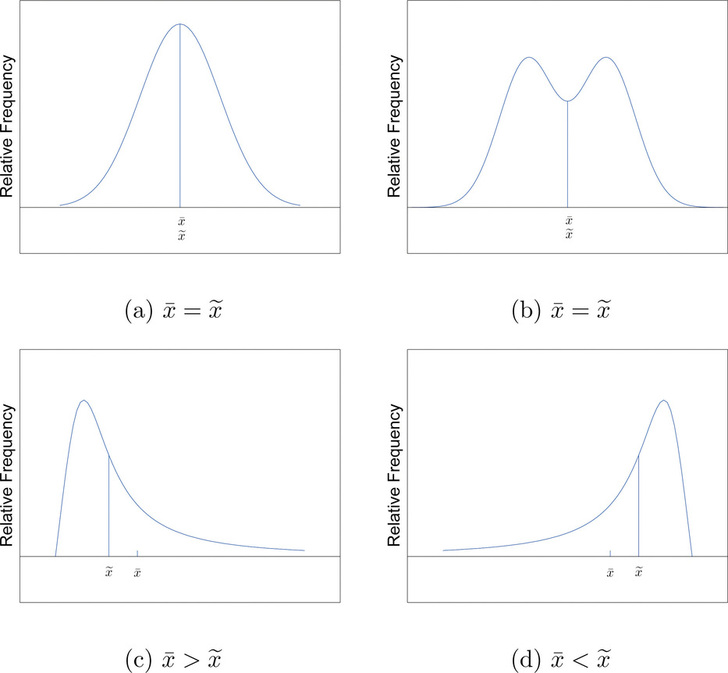
La relación entre la media y la mediana para varias formas comunes de distribuciones se muestra en la Figura\(\PageIndex{2}\). Se dice que las distribuciones en los paneles (a) y (b) son simétricas debido a la simetría que exhiben. Se dice que las distribuciones en los dos paneles restantes están sesgadas. En cada distribución hemos dibujado una línea vertical que divide el área bajo la curva por la mitad, que de acuerdo con la Figura\(\PageIndex{1}\) se ubica en la mediana. Los siguientes hechos son ciertos en general:
- Cuando la distribución es simétrica, como en los paneles (a) y (b) de la Figura\(\PageIndex{2}\), la media y la mediana son iguales.
- Cuando la distribución es como se muestra en el panel (c), se dice que está sesgada a la derecha. La media ha sido tirada a la derecha de la mediana por la larga “cola derecha” de la distribución, los pocos valores de datos relativamente grandes.
- Cuando la distribución es como se muestra en el panel (d), se dice que está sesgada a la izquierda. La media ha sido tirada a la izquierda de la mediana por la larga “cola izquierda” de la distribución, los pocos valores de datos relativamente pequeños.
El Modo
Quizás haya escuchado una declaración como “El número promedio de automóviles propiedad de hogares en Estados Unidos es”\(1.37\), y se han divertido al pensar en una fracción de un automóvil sentado en un camino de entrada. En tal contexto, la siguiente medida para la ubicación central podría tener más sentido.
Definición: Modo de muestra
El modo de muestreo de un conjunto de datos de muestra es el valor que ocurre con mayor frecuencia.
En un histograma de frecuencia relativa, el punto más alto del histograma corresponde al modo del conjunto de datos. La figura\(\PageIndex{3}\) ilustra el modo.
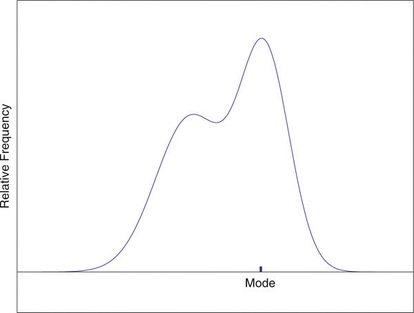
Figura\(\PageIndex{3}\): Modo
Para cualquier conjunto de datos siempre hay exactamente una media y exactamente una mediana. Esto no necesita ser cierto para el modo; varios valores diferentes podrían ocurrir con la frecuencia más alta, como veremos. Incluso podría suceder que cada valor ocurra con la misma frecuencia, en cuyo caso el concepto del modo no tiene mucho sentido.
Ejemplo\(\PageIndex{8}\)
Encuentra el modo del siguiente conjunto de datos:\(-1,\; 0,\; 2,\; 0\).
Solución
El valor\(0\) se observa con mayor frecuencia en el conjunto de datos, por lo que el modo es\(0\).
Ejemplo\(\PageIndex{9}\)
Calcular el modo de muestra para los datos de Ejemplo\(\PageIndex{4}\)
Solución
Los dos valores más frecuentemente observados en el conjunto de datos son\(1\) y\(2\). Por lo tanto, el modo es un conjunto de dos valores:\(\{1,2\}\).
El modo es una medida de la ubicación central ya que la mayoría de los conjuntos de datos de la vida real tienen más observaciones cerca del centro del rango de datos y menos observaciones en los extremos inferior y superior. El valor con la frecuencia más alta suele estar en el medio del rango de datos.
Llave para llevar
- La media, la mediana y el modo responden cada uno a la pregunta “¿Dónde está el centro del conjunto de datos?” La naturaleza del conjunto de datos, como lo indica un histograma de frecuencia relativa, determina cuál da la mejor respuesta.