
7.1: Estimación de muestra grande de una media poblacional
- Page ID
- 151193
Objetivos de aprendizaje
- Familiarizarse con el concepto de estimación de intervalo de la media poblacional.
- Comprender cómo aplicar fórmulas para un intervalo de confianza para una media poblacional.
El Teorema del Límite Central dice que, para muestras grandes (muestras de tamaño\(n \ge 30\)), cuando se ve como una variable aleatoria la media de la muestra\(\overline{X}\) se distribuye normalmente con media\(\mu_{ \overline{X}}=\mu\) y desviación estándar\(\sigma_{\overline{X}}=\frac{\sigma}{\sqrt{n}}\). La Regla Empírica dice que debemos ir alrededor de dos desviaciones estándar de la media para capturar\(95\%\) los valores de\(\overline{X}\) generados por muestra tras muestra. Una distancia más precisa basada en la normalidad de\(\overline{X}\) es desviaciones\(1.960\) estándar, que es\( E=\frac{1.960 \sigma}{\sqrt{n}}\).
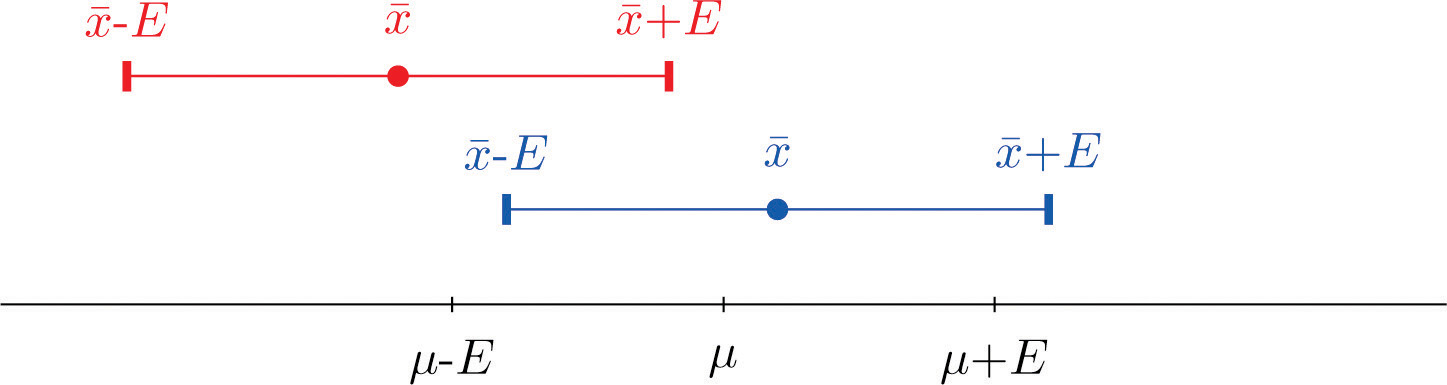
La idea clave en la construcción del intervalo de\(95\%\) confianza es esta, como se ilustra en la Figura\(\PageIndex{1}\), porque en muestra tras muestra\(95\%\) de los valores de\(\overline{X}\) mentira en el intervalo\([\mu -E,\mu +E]\), si colindamos a cada lado del punto estimar\( x-a\) “ala” de longitud\(E\), \(95\%\)de los intervalos formados por los puntos alados contienen\(\mu\). El intervalo de\(95\%\) confianza es así\(\bar{x}\pm 1.960\frac{\sigma }{\sqrt{n}}\). Para un nivel diferente de confianza, digamos\(90\%\) o\(99\%\), el número\(1.960\) va a cambiar, pero la idea es la misma.
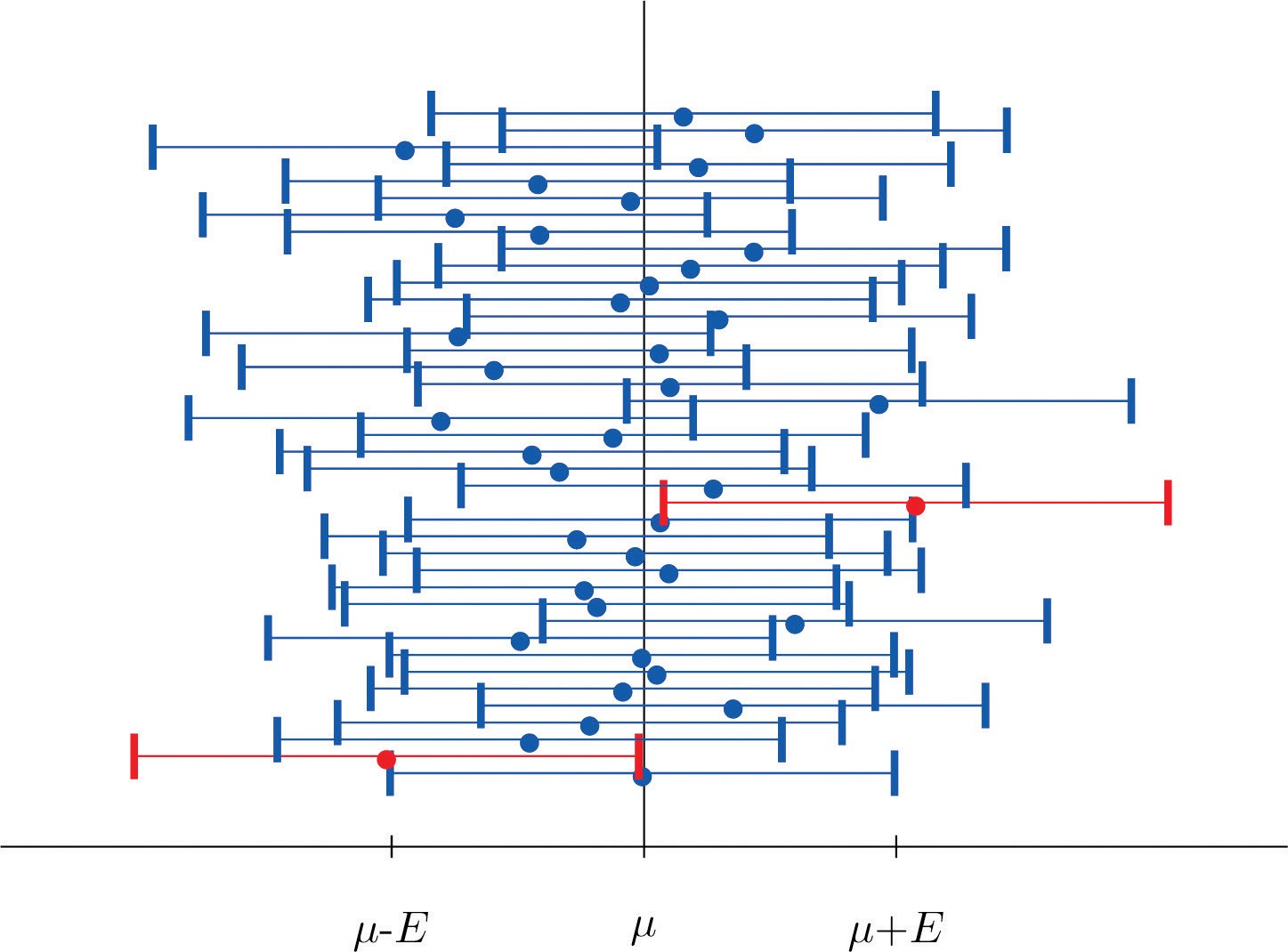
La figura\(\PageIndex{2}\) muestra los intervalos generados por una simulación por computadora de extraer\(40\) muestras de una población normalmente distribuida y construir el intervalo de\(95\%\) confianza para cada una. Esperamos que aproximadamente\( (0.05)(40)=2\) de los intervalos así construidos no contuvieran la media poblacional\(\mu \), y en esta simulación dos de los intervalos, mostrados en rojo, sí.
Es una práctica estándar identificar el nivel de confianza en términos del área\(α\) en las dos colas de la distribución de\(\overline{X}\) cuando se saca la parte media especificada por el nivel de confianza. Esto se muestra en la Figura\(\PageIndex{3}\), dibujada para la situación general, y en la Figura\(\PageIndex{4}\), dibujada para\(95\%\) la confianza.
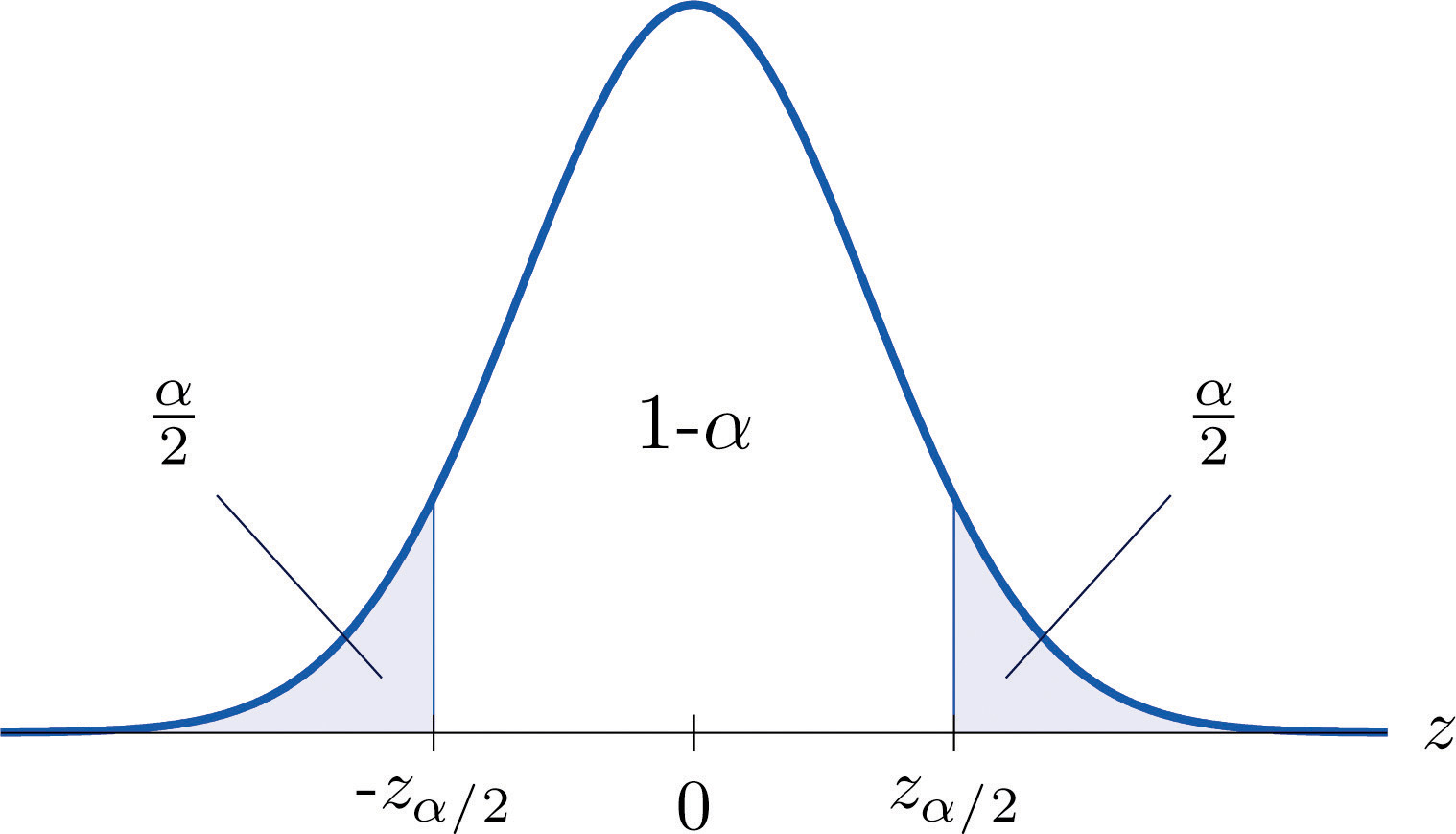
Recuerde de la Sección 5.4 que se denota el\(z\) -valor que corta una cola derecha del área\(c\)\(z_c\). Así el número\(1.960\) en el ejemplo es\( z_{.025}\), que es\(z_{\frac{\alpha }{2}}\) para\(\alpha =1-0.95=0.05\).
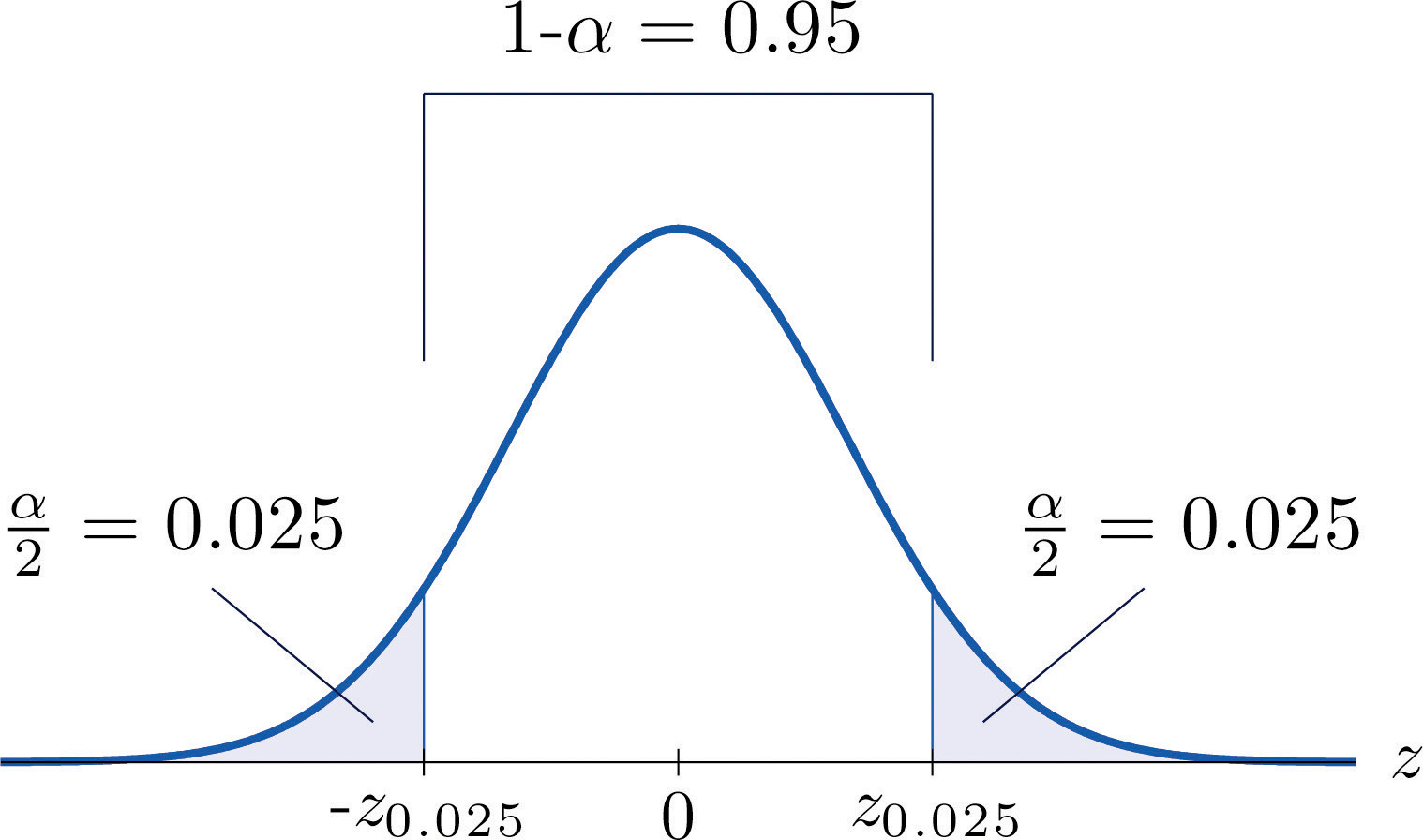
Para la\(95\%\) confianza el área en cada cola es\(\alpha /2=0.025\).
El nivel de confianza puede ser cualquier número entre\(0\) y\(100\%\), pero los valores más comunes son probablemente\(90\%\)\((\alpha =0.10)\),\(95\%\)\((\alpha =0.05)\), y\(99\%\)\((\alpha =0.01)\).
Así en general para un intervalo de\(100(1-\alpha )\%\) confianza,\(E=z_{\alpha /2}(\sigma /\sqrt{n})\), por lo que la fórmula para el intervalo de confianza es\(\bar{x}\pm z_{\alpha /2}(\sigma /\sqrt{n})\). Si bien en ocasiones\(\sigma\) se conoce la desviación estándar de la población, normalmente no lo es. De no ser así, por\(n\geq 30\) lo general es seguro aproximarse\(\sigma\) por la desviación estándar de la muestra\(s\).
Muestra grande\(100(1-\alpha )\%\) Confidence Interval for a Population Mean
- Si\(\sigma\) se conoce:\[\bar{x}\pm z_{\alpha /2}\left ( \dfrac{\sigma }{\sqrt{n}} \right )\]
- Si\(\sigma\) se desconoce:\[\bar{x}\pm z_{\alpha /2}\left ( \dfrac{s}{\sqrt{n}} \right )\]
Una muestra se considera grande cuando\(n\geq 30\).
Como se mencionó anteriormente, el número
\[E=z_{\alpha /2}\left ( \frac{\sigma }{\sqrt{n}} \right )\]
o
\[E=z_{\alpha /2}\left ( \frac{s}{\sqrt{n}} \right )\]
se llama el margen de error de la estimación.
Ejemplo\(\PageIndex{1}\)
Encuentra el número\(z_{\alpha /2}\) necesario en la construcción de un intervalo de confianza:
- cuando el nivel de confianza es\(90\%\);
- cuando el nivel de confianza es\(99\%\).
usando las tablas de la Figura\(\PageIndex{5}\) a continuación.


Solución:
- Por nivel de confianza\(90\%\),\(\alpha =1-0.90=0.10\), entonces\(z_{\alpha /2}=z_{0.05}\). Dado que el área bajo la curva normal estándar a la derecha de\(z_{0.05}\) es\(0.05\), el área a la izquierda de\(z_{0.05}\) es\(0.95\). Buscamos el área\(0.9500\) en Figura\(\PageIndex{5}\). Las entradas más cercanas en la tabla son\(0.9495\) y\(0.9505\), correspondientes a\(z\) -valores\(1.64\) y\(1.65\). Ya que\(0.95\) está a medio camino entre\(0.9495\) y\(0.9505\) usamos el promedio\(1.645\) de los\(z\) -valores para\(z_{0.05}\).
- Por nivel de confianza\(99\%\),\(\alpha =1-0.99=0.01\), entonces\(z_{\alpha /2}=z_{0.005}\). Dado que el área bajo la curva normal estándar a la derecha de\(z_{0.005}\) es\(0.005\), el área a la izquierda de\(z_{0.005}\) es\(0.9950\). Buscamos el área\(0.9950\) en Figura\(\PageIndex{5}\). Las entradas más cercanas en la tabla son\(0.9949\) y\(0.9951\), correspondientes a\(z\) -valores\(2.57\) y\(2.58\). Ya que\(0.995\) está a medio camino entre\(0.9949\) y\(0.9951\) usamos el promedio\(2.575\) de los\(z\) -valores para\(z_{0.005}\).
Ejemplo\(\PageIndex{2}\)
Utilice la Figura a\(\PageIndex{6}\) continuación para encontrar el número\(z_{\alpha /2}\) necesario en la construcción de un intervalo de confianza:
- cuando el nivel de confianza es\(90\%\);
- cuando el nivel de confianza es\(99\%\).
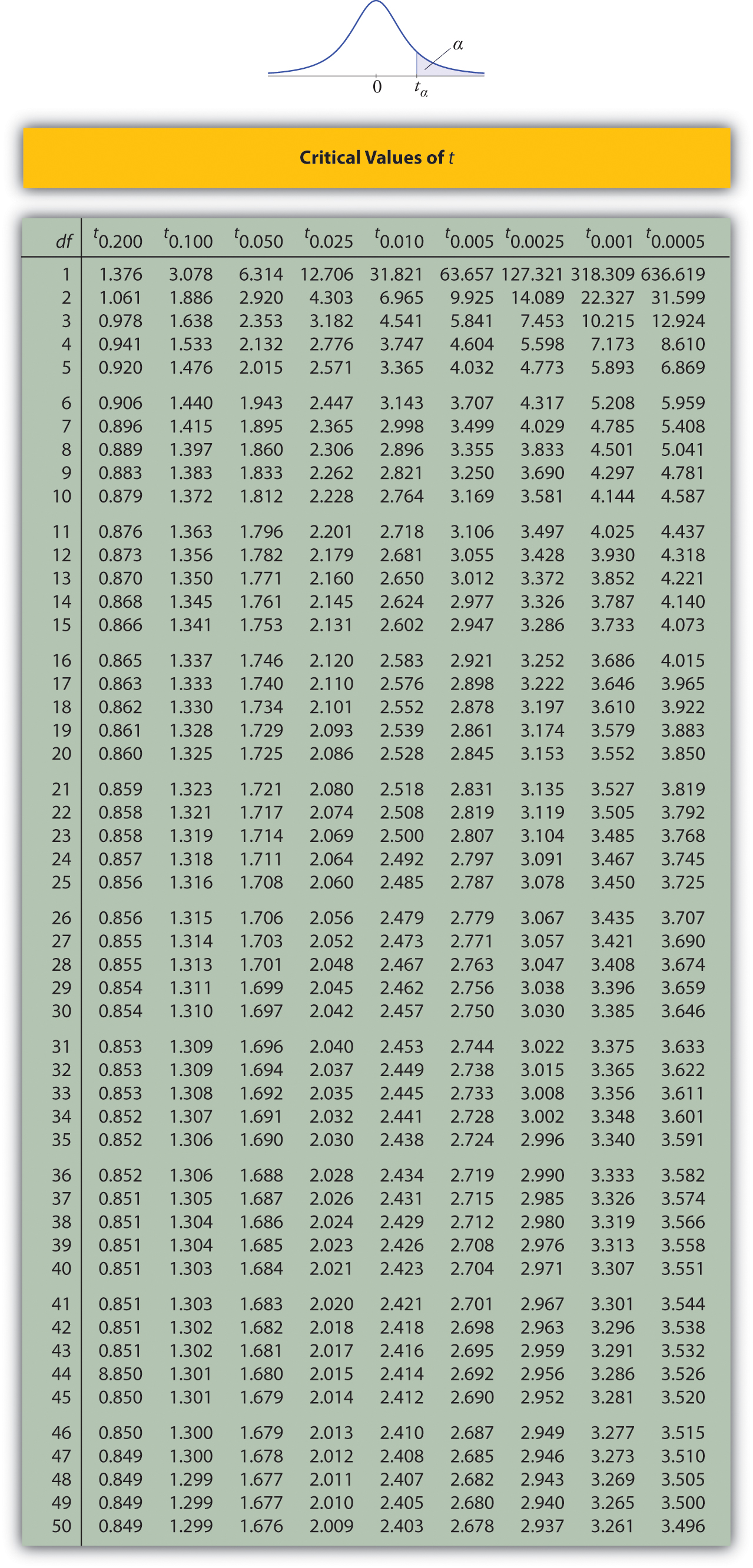
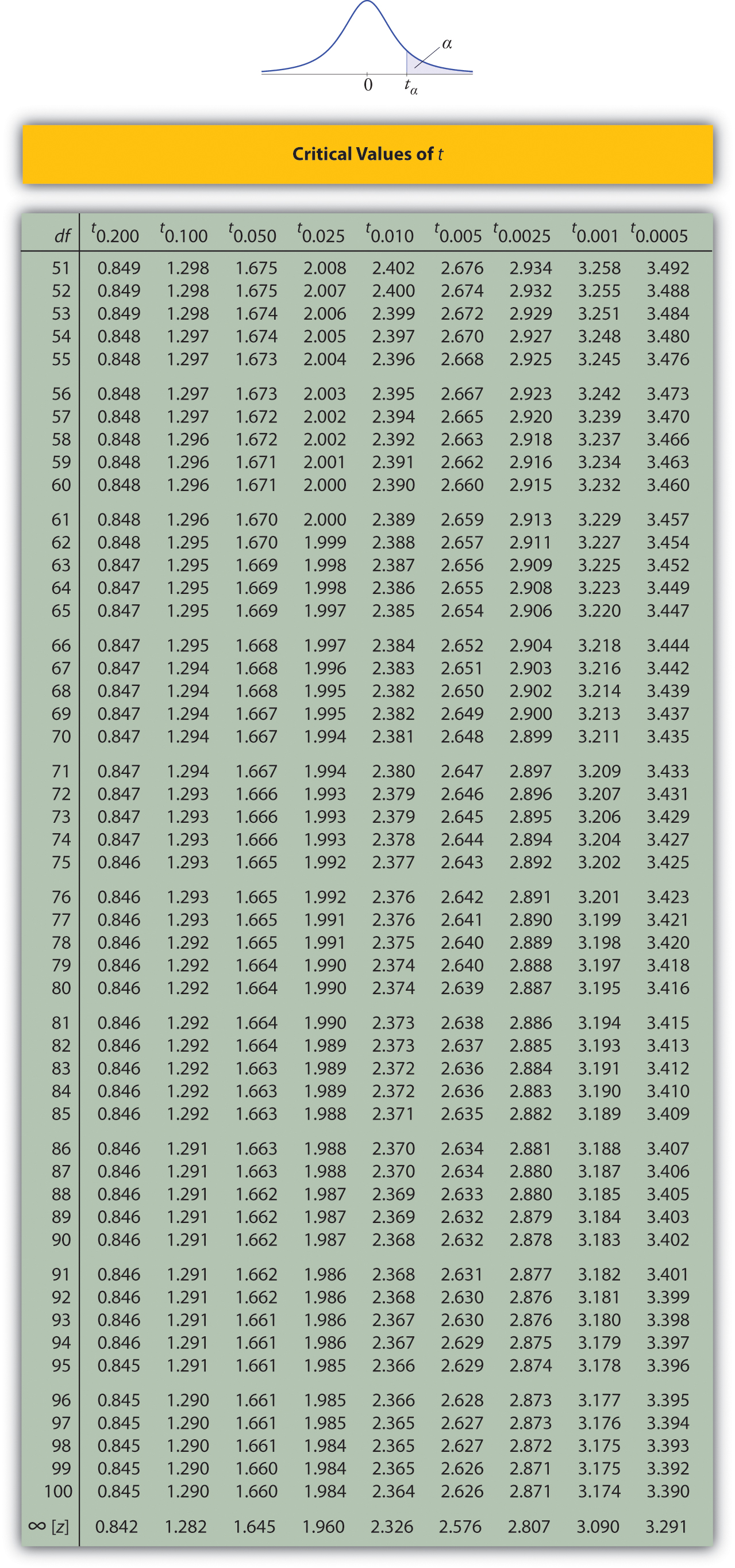
Solución:
- En la siguiente sección aprenderemos sobre una variable aleatoria continua que tiene una distribución de probabilidad llamada\(t\) distribución Student. La figura\(\PageIndex{6}\) da el valor\(t_c\) que corta una cola derecha de área\(c\) para diferentes valores de\(c\). La última línea de esa tabla, aquella cuyo encabezado es el símbolo\(\infty\) del infinito y\([z]\), da el\(z\) -valor correspondiente\(z_c\) que corta una cola derecha de la misma área\(c\). En particular,\(z_{0.05}\) es el número en esa fila y en la columna con el encabezamiento\(t_{0.05}\). Leemos eso directamente\(z_{0.05}=1.645\).
- En Figura\(\PageIndex{6}\)\(z_{0.005}\) se encuentra el número en la última fila y en la columna encabezada\(t_{0.005}\), es decir\(2.576\).
Figura se\(\PageIndex{6}\) puede utilizar para encontrar\(z_c\) sólo para aquellos valores de\(c\) para los cuales hay una columna con el encabezado que\(t_c\) aparece en la tabla; de lo contrario debemos usar Figura\(\PageIndex{5}\) a la inversa. Pero cuando se puede hacer es a la vez más rápido y más preciso usar la última línea de Figura\(\PageIndex{6}\) para encontrar\(z_c\) que hacerlo usando Figura a\(\PageIndex{5}\) la inversa.
Ejemplo\(\PageIndex{3}\)
Una muestra de tamaño\(49\) tiene media muestral\(35\) y desviación estándar de la muestra\(14\). Construir un intervalo de\(98\%\) confianza para la media poblacional utilizando esta información. Interpretar su significado.
Solución:
Por nivel de confianza\(98\%\),\(\alpha =1-0.98=0.02\), entonces\(z_{\alpha /2}=z_{0.01}\). De la Figura\(\PageIndex{6}\) leemos directamente\(z_{0.01}=2.326\) eso.Así
\[\bar{x}\pm z_{\alpha /2}\frac{s}{\sqrt{n}}=35\pm 2.326\left ( \frac{14}{\sqrt{49}} \right )=35\pm 4.652\approx 35\pm 4.7\]
Estamos\(98\%\) seguros de que la media poblacional\(\mu\) se encuentra en el intervalo\([30.3,39.7]\), en el sentido de que en el muestreo repetido\(98\%\) de todos los intervalos construidos a partir de la muestra los datos de esta manera contendrán\(\mu\).
Ejemplo\(\PageIndex{4}\)
Una muestra aleatoria de\(120\) estudiantes de una universidad grande produce promedio de GPA\(2.71\) con desviación estándar de la muestra\(0.51\). Construir un intervalo de\(90\%\) confianza para el promedio promedio de todos los estudiantes de la universidad.
Solución:
Por nivel de confianza\(90\%\),\(\alpha =1-0.90=0.10\), entonces\(z_{\alpha /2}=z_{0.05}\). De Figura\(\PageIndex{6}\) leemos directamente eso\(z_{0.05}=1.645\). Desde\(n=120\),\(\bar{x}=2.71\), y\(s=0.51\),
\[\bar{x}\pm z_{\alpha /2}\frac{s}{\sqrt{n}}=2.71\pm 1.645\left ( \frac{0.51}{\sqrt{120}} \right )=2.71\pm 0.0766\]
Uno puede estar\(90\%\) seguro de que el verdadero promedio promedio de todos los estudiantes de la universidad está contenido en el intervalo\((2.71-0.08,2.71+0.08)=(2.63,2.79)\).
Llave para llevar
- Un intervalo de confianza para una media poblacional es una estimación de la media poblacional junto con una indicación de confiabilidad.
- Existen diferentes fórmulas para un intervalo de confianza en función del tamaño de la muestra y si se conoce o no la desviación estándar de la población.
- Los intervalos de confianza se construyen en su totalidad a partir de los datos de la muestra (o datos de la muestra y la desviación estándar de la población, cuando se conoce).