
2.5: Independencia
- Page ID
- 152200

En esta sección, discutiremos la independencia, uno de los conceptos fundamentales en la teoría de la probabilidad. La independencia es frecuentemente invocada como una suposición modelada, y además, la probabilidad (clásica) misma se basa en la idea de replicaciones independientes del experimento. Como de costumbre, si eres un nuevo estudiante de probabilidad, es posible que quieras saltarte los detalles técnicos.
Teoría Básica
Como es habitual, nuestro punto de partida es un experimento aleatorio modelado por un espacio de probabilidad de\( (S, \mathscr S, \P) \) manera que\( S \) sea el conjunto de resultados,\( \mathscr S \) la colección de eventos y\( \P \) la medida de probabilidad en el espacio muestral\((S, \mathscr S)\). Definiremos la independencia para dos eventos, luego para colecciones de eventos, y luego para colecciones de variables aleatorias. En cada caso, la idea básica es la misma.
Independencia de dos acontecimientos
Dos eventos\(A\) y\(B\) son independientes si\[\P(A \cap B) = \P(A) \P(B)\]
Si ambos eventos tienen probabilidad positiva, entonces la independencia es equivalente a la afirmación de que la probabilidad condicional de un evento dado el otro es la misma que la probabilidad incondicional del evento:\[\P(A \mid B) = \P(A) \iff \P(B \mid A) = \P(B) \iff \P(A \cap B) = \P(A) \P(B)\] Así es como debes pensar en la independencia: saber que un evento ha ocurrido no cambia la probabilidad asignada al otro evento. La independencia de dos eventos se discutió en la última sección en el contexto de correlación. En particular, para dos eventos, independiente y no correlacionado significan lo mismo.
Los términos independientes y disjuntos suenan vagamente similares pero en realidad son muy diferentes. Primero, tenga en cuenta que la desarticulación es puramente un concepto de teoría de conjuntos, mientras que la independencia es un concepto de probabilidad (teórica de medidas). De hecho, dos eventos pueden ser independientes en relación con una medida de probabilidad y dependientes relativos a otra. Pero lo más importante, dos eventos disjuntos nunca pueden ser independientes, salvo en el caso trivial de que uno de los eventos es nulo.
Supongamos que\(A\) y\(B\) son eventos disjuntos, cada uno con probabilidad positiva. Entonces\(A\) y\(B\) son dependientes, y de hecho se correlacionan negativamente.
Prueba
Tenga en cuenta que\(\P(A \cap B) = \P(\emptyset) = 0\) pero\(\P(A) \P(B) \gt 0\).
Si\(A\) y\(B\) son eventos independientes entonces intuitivamente parece claro que cualquier evento a partir del cual se pueda construir\(A\) debe ser independiente de cualquier evento a partir del cual se pueda construir\(B\). Este es el caso, como muestra el siguiente resultado. Además, esta idea básica es esencial para la generalización de la independencia que consideraremos en breve.
Si\(A\) y\(B\) son eventos independientes, entonces cada uno de los siguientes pares de eventos es independiente:
- \(A^c\),\(B\)
- \(B\),\(A^c\)
- \(A^c\),\(B^c\)
Prueba
Supongamos que\( A \) y\( B \) son independientes. Entonces por la regla de diferencia y la regla del complemento,\[ \P(A^c \cap B) = \P(B) - \P(A \cap B) = \P(B) - \P(A) \, \P(B) = \P(B)\left[1 - \P(A)\right] = \P(B) \P(A^c) \] De ahí\( A^c \) y\( B \) son equivalentes. Las partes (b) y (c) siguen de (a).
Un evento que es esencialmente determinista
, es decir, tiene probabilidad 0 o 1, es independiente de cualquier otro evento, incluso de sí mismo.
Supongamos que\(A\) y\(B\) son eventos.
- Si\(\P(A) = 0\) o\(\P(A) = 1\), entonces\(A\) y\(B\) son independientes.
- \(A\)es independiente de sí mismo si y sólo si\(\P(A) = 0\) o\(\P(A) = 1\).
Prueba
- Recordemos que si\( \P(A) = 0 \) entonces\( \P(A \cap B) = 0 \), y si\( \P(A) = 1 \) entonces\( \P(A \cap B) = \P(B) \). En cualquier caso tenemos\( \P(A \cap B) = \P(A) \P(B) \).
- La independencia de\( A \) consigo misma da\( \P(A) = [\P(A)]^2 \) y de ahí\( \P(A) = 0 \) o bien\( \P(A) = 1 \).
Independencia General de los Eventos
Para extender la definición de independencia a más de dos eventos, podríamos pensar que solo podríamos requerir la independencia por parejas, la independencia de cada par de eventos. No obstante, esto no es suficiente para el fuerte tipo de independencia que tenemos en mente. Por ejemplo, supongamos que tenemos tres eventos\(A\),\(B\), y\(C\). La independencia mutua de estos eventos no sólo debe significar que cada pareja es independiente, sino también que un evento que se pueda construir a partir de\(A\) y\(B\) (por ejemplo\(A \cup B^c\)) debe ser independiente de\(C\). La independencia por parejas no logra esto; un ejercicio a continuación da tres eventos que son independientes por parejas, pero la intersección de dos de los eventos está relacionada con el tercer evento en el sentido más fuerte posible.
Otra posible generalización sería simplemente exigir que la probabilidad de la intersección de los eventos sea producto de las probabilidades de los eventos. Sin embargo, esta condición ni siquiera garantiza la independencia por parejas. Un ejercicio a continuación da un ejemplo. Sin embargo, la definición de independencia para dos eventos sí generaliza de manera natural a una colección arbitraria de eventos.
Supongamos que\( A_i \) es un evento para cada uno\( i \) en un conjunto de índices\( I \). Entonces la colección\( \mathscr{A} = \{A_i: i \in I\} \) es independiente si por cada finito\( J \subseteq I \),\[\P\left(\bigcap_{j \in J} A_j \right) = \prod_{j \in J} \P(A_j)\]
La independencia de una colección de eventos es mucho más fuerte que la mera independencia por parejas de los eventos de la colección. El bien básico de herencia en el siguiente resultado se desprende inmediatamente de la definición.
Supongamos que\(\mathscr{A}\) es una colección de eventos.
- Si\(\mathscr{A}\) es independiente, entonces\(\mathscr{B}\) es independiente para cada\(\mathscr{B} \subseteq \mathscr{A}\).
- Si\(\mathscr{B}\) es independiente para cada finito\(\mathscr{B} \subseteq \mathscr{A}\) entonces\(\mathscr{A}\) es independiente.
Para una colección finita de eventos, el número de condiciones requeridas para la independencia mutua crece exponencialmente con el número de eventos.
Existen condiciones\(2^n - n - 1\) no triviales en la definición de la independencia de los\(n\) acontecimientos.
- Dar explícitamente las 4 condiciones que deben cumplirse para los eventos\(A\),\(B\), y\(C\) para ser independientes.
- Dar explícitamente las 11 condiciones que deben cumplirse para los eventos\(A\),\(B\),\(C\), y\(D\) para ser independientes.
Responder
Hay\( 2^n \) subcolecciones de los\( n \) eventos. Uno está vacío e\( n \) involucra un solo evento. Las\( 2^n - n - 1 \) subcolecciones restantes involucran dos o más eventos y corresponden a condiciones no triviales.
- \(A\),\(B\),\(C\) son independientes si y solo si\ comienzan {alinear*} &\ P (A\ cap B) =\ P (A)\ P (B)\\ &\ P (A\ cap C) =\ P (A)\ P (C)\\ &\ P (B\ cap C) =\ P (B)\ P (C)\\ &\ P (A\ cap B\ cap C) =\ P (A)\ P (B)\ P (C)\ final {alinear*}
- \(A\),\(B\),\(C\),\(D\) son independientes si y solo si\ comienzan {alinear*} &\ P (A\ cap B) =\ P (A)\ P (B)\\ &\ P (A\ cap C) =\ P (A)\ P (C)\\ &\ P (A\ cap D) =\ P (A)\ P (D)\\ &\ P (B\ cap C) =\ P (B)\ P (C)\\ &\ P (B\ cap D) =\ P (B)\ P (D)\\ &\ P (C\ cap D) =\ P (C)\ P (D)\\ &\ P (A\ cap B\ cap C) =\ P (A)\ P (B)\ P (C)\\ &\ P (A\ cap B\ cap D) =\ P (A)\ P (B)\ P (D)\\ &\ P (A\ cap C\ cap D) =\ P (A)\ P (C)\ P (D)\\ &\ P (B\ cap C\ cap D) =\ P (B)\ P (C)\ P (D)\\\ &\ P (A\ cap B\ cap C\ cap D) =\ P (A)\ P (B)\ P (C)\ P (D)\ final {align*}
Si los eventos\( A_1, A_2, \ldots, A_n \) son independientes, entonces se deduce inmediatamente de la definición que\[\P\left(\bigcap_{i=1}^n A_i\right) = \prod_{i=1}^n \P(A_i)\] Esto se conoce como la regla de multiplicación para eventos independientes. Compare esto con la regla general de multiplicación para la probabilidad condicional.
La colección de eventos esencialmente deterministas\(\mathscr{D} = \{A \in \mathscr{S}: \P(A) = 0 \text{ or } \P(A) = 1\}\) es independiente.
Prueba
Supongamos que\( \{A_1, A_2, \ldots, A_n\} \subseteq \mathscr{D} \). Si\( \P(A_i) = 0 \) para algunos\( i \in \{1, 2, \ldots, n\} \) entonces\( \P(A_1 \cap A_2 \cap \cdots \cap A_n) = 0 \). Si\( \P(A_i) = 1 \) por cada\( i \in \{1, 2, \ldots, n\} \) entonces\( \P(A_1 \cap A_2 \cap \cdots \cap A_n) = 1 \). En cualquier caso,\( \P(A_1 \cap A_2 \cdots \cap A_n) = \P(A_1) \P(A_2) \cdots \P(A_n) \).
El siguiente resultado generaliza el teorema anterior sobre los complementos de dos eventos independientes.
Supongamos que\( \mathscr A = \{A_i: i \in I\} \) y\( \mathscr B = \{B_i: i \in I\} \) son dos colecciones de eventos con la propiedad que para cada uno\( i \in I \), ya sea\( B_i = A_i \) o\( B_i = A_i^c \). Entonces\( \mathscr A \) es independiente si y sólo si\( \mathscr B \) es un independiente.
Prueba
La prueba es en realidad muy similar a la prueba de dos eventos, a excepción de la notación más complicada. Primero, por la simetría de la relación entre\( \mathscr A \) y\( \mathscr B \), basta con mostrar\( \mathscr A \) indpendent implica\( \mathscr B \) independiente. A continuación, por la propiedad de herencia, basta con considerar el caso donde el conjunto de índices\( I \) es finito.
- Fijar\( k \in I \) y definir\( B_k = A_k^c \) y\( B_i = A_i \) para\( i \in I \setminus \{k\} \). Supongamos ahora eso\( J \subseteq I \). Si\( k \notin J \) entonces trivialmente,\( \P\left(\bigcap_{j \in J} B_j\right) = \prod_{j \in J} \P(B_j) \). Si\( k \in J \), entonces usando la regla de diferencia,\ begin {align*}\ P\ left (\ bigcap_ {j\ in J} B_j\ right) &=\ P\ left (\ bigcap_ {j\ in J\ setless\ {k\}} a_J\ right) -\ P\ left (\ bigcap_ {j\ in J} a_J\ right)\\ & =\ prod_ {j\ en J\ setmenos\ {k\}}\ P (a_J) -\ prod_ {j\ en J}\ P (a_J) =\ left [\ prod_ {j\ in J\ setless\ {k\}} \ P (a_J)\ derecha] [1 -\ P (a_K)] =\ prod_ {j\ in J}\ P (B_j)\ end {align*} De ahí\( \{B_i: i \in I\} \) es una colección de eventos independientes.
- Supongamos ahora que\( \mathscr B = \{B_i: i \in I\} \) es una colección general de eventos donde\( B_i = A_i \) o\( B_i = A_i^c \) para cada uno\( i \in I \). Entonces se\( \mathscr B \) puede obtener a partir\( \mathscr A \) de una secuencia finita de cambios de complemento del tipo en (a), cada uno de los cuales conserva la independencia.
El último teorema a su vez conduce al tipo de independencia fuerte que queremos. En el siguiente ejercicio se dan ejemplos.
Si\(A\),\(B\),\(C\), y\(D\) son eventos independientes, entonces
- \(A \cup B\),\(C^c\),\(D\) son independientes.
- \(A \cup B^c\),\(C^c \cup D^c\) son independientes.
Prueba
Daremos pruebas que utilicen el teorema del complemento, pero para ello, alguna notación adicional es útil. Si\( E \) es un evento, vamos\( E^1 = E \) y\( E^0 = E^c\).
- Obsérvese que\( A \cup B = \bigcup_{(i, j) \in I} A^i \cap B^j \) donde\( I = \{(1, 0), (0, 1), (1, 1)\} \) y señalar que los hechos en el sindicato son disjuntos. Por la propiedad distributiva,\( (A \cup B) \cap C^c = \bigcup_{(i, j) \in I} A^i \cap B^j \cap C^0 \) y nuevamente los acontecimientos en la unión son disjuntos. Por aditividad y complemento teorema,\[ \P[(A \cup B) \cap C^c] = \sum_{(i, j) \in I} \P(A^i) \P(B^j) \P(C^0) = \left(\sum_{(i,j) \in I} \P(A^i) \P(B^j)\right) \P(C^0) = \P(A \cup B) \P(C^c) \] Por exactamente el mismo tipo de argumento,\( \P[(A \cup B) \cap D] = \P(A \cup B) \P(D) \) y\(\P[(A \cup B) \cap C^c \cap D] = \P(A \cup B) \P(C^c) \P(D) \). Directamente del resultado anterior sobre complementos,\( \P(C^c \cap D) = \P(C^c) \P(D) \).
- Obsérvese que\( A \cup B^c = \bigcup_{(i, j) \in I} A^i \cap B^j \) donde\( I = \{(0, 0), (1, 0), (1, 1)\} \) y señalar que los hechos en el sindicato son disjuntos. De igual manera\( C^c \cup D^c = \bigcup_{(k, l) \in J} C^i \cap D^j\) donde\( J = \{(0, 0), (1, 0), (0, 1)\} \), y nuevamente los acontecimientos en el sindicato son disjuntos. Por la regla distributiva para las operaciones establecidas,\[ (A \cup B^c) \cap (C^c \cup D^c) = \bigcup_{(i, j, k ,l) \in I \times J} A^i \cap B^j \cap C^k \cap D^l \] y una vez más, los acontecimientos en el sindicato son disjuntos. Por aditividad y el teorema del complemento,\[ \P[(A \cup B^c) \cap (C^c \cup D^c)] = \sum_{(i, j, k ,l) \in I \times J} \P(A^i ) \P(B^j) \P(C^k) \P(D^l) \] Pero también por la aditividad, el teorema del complemento, y la propiedad distributiva de la aritmética,\[ \P(A \cup B^c) \P(C^c \cup D^c) = \left(\sum_{(i,j) \in I} \P(A^i) \P(B^j)\right) \left(\sum_{(k,l) \in J} \P(C^k) \P(D^l)\right) = \sum_{(i, j, k ,l) \in I \times J} \P(A^i ) \P(B^j) \P(C^k) \P(D^l) \]
La generalización completa de estos resultados es un poco complicada, pero aproximadamente significa que si comenzamos con una colección de eventos indpendent, y formamos nuevos eventos a partir de subcolecciones disjuntas (usando las operaciones establecidas de unión, intersección y complment), entonces los nuevos eventos son independientes. Para una declaración precisa, consulte la sección sobre espacios de medida. La importancia del teorema del complemento radica en el hecho de que cualquier evento que pueda definirse en términos de una colección finita de eventos\( \{A_i: i \in I\} \) puede escribirse como una unión disjunta de eventos de la forma\( \bigcap_{i \in I} B_i \) donde\( B_i = A_i \) o\( B_i = A_i^c\) para cada uno\( i \in I \).
Otra consecuencia del teorema general del complemento es una fórmula para la probabilidad de la unión de una colección de eventos independientes que es mucho más agradable que la fórmula de inclusión-exclusión.
Si\( A_1, A_2, \ldots, A_n \) son eventos independientes, entonces\[\P\left(\bigcup_{i=1}^n A_i\right) = 1 - \prod_{i=1}^n \left[1 - \P(A_i)\right]\]
Prueba
De la ley de DeMorgan y la independencia de\( A_1^c, A_2^c, \ldots, A_n^c \) nosotros tenemos\[ \P\left(\bigcup_{i=1}^n A_i \right) = 1 - \P\left( \bigcap_{i=1}^n A_i^c \right) = 1 - \prod_{i=1}^n \P(A_i^c) = 1 - \prod_{i=1}^n \left[1 - \P(A_i)\right] \]
Independencia de variables aleatorias
Supongamos ahora que\(X_i\) es una variable aleatoria para el experimento con valores en un conjunto\(T_i\) para cada uno\(i\) en un conjunto de índices no vacíos\(I\). Matemáticamente,\( X_i \) es una función desde\( S \) dentro\( T_i \), y recordar que\( \{X_i \in B\} \) denota el evento\( \{s \in S: X_i(s) \in B\} \) para\( B \subseteq T_i \). Intuitivamente,\( X_i \) es una variable de interés en el experimento, y cada declaración significativa sobre\( X_i \) define un evento. Intuitivamente, las variables aleatorias son independientes si la información sobre algunas de las variables no nos dice nada sobre las otras variables. Matemáticamente, la independencia de una colección de variables aleatorias puede reducirse a la independencia de colecciones de eventos.
La colección de variables aleatorias\( \mathscr{X} = \{X_i: i \in I\} \) es independiente si la colección de eventos\( \left\{\{X_i \in B_i\}: i \in I\right\} \) es independiente para cada elección de\( B_i \subseteq T_i \) for\( i \in I \). Equivalentemente entonces,\( \mathscr{X} \) es independiente si por cada finito\(J \subseteq I\), y para cada elección de\(B_j \subseteq T_j\) para\(j \in J\) tenemos\[\P\left(\bigcap_{j \in J} \{X_j \in B_j\} \right) = \prod_{j \in J} \P(X_j \in B_j)\]
Detalles
Recordemos que\( T_i \) tendrá un\( \sigma \) -álgebra\( \mathscr T_i \) de subconjuntos admisibles por lo que\( (T_i, \mathscr T_i) \) es un espacio medible al igual que el espacio muestral\( (S, \mathscr S) \) para cada uno\( i \in I \). También\( X_i \) es medible como una función desde\( S \) dentro\( T_i \) para cada uno\( i \in I \). Estos supuestos técnicos aseguran que la definición tenga sentido.
Supongamos que\(\mathscr{X}\) es una colección de variables aleatorias.
- Si\(\mathscr{X}\) es independiente, entonces\(\mathscr{Y}\) es independiente para cada\(\mathscr{Y} \subseteq \mathscr{X}\)
- Si\(\mathscr{Y}\) es independiente para cada finito\(\mathscr{Y} \subseteq \mathscr{X}\) entonces\(\mathscr{X}\) es independiente.
Parecería casi obvio que si una colección de variables aleatorias es independiente, y transformamos cada variable de manera determinista, entonces la nueva colección de variables aleatorias debería seguir siendo independiente.
Supongamos ahora que\( g_i \) es una función desde\( T_i \) dentro de un conjunto\( U_i \) para cada uno\( i \in I \). Si\( \{X_i: i \in I\} \) es independiente, entonces también\( \{g_i(X_i): i \in I\} \) es independiente.
Prueba
Excepto por el escenario abstracto, la prueba de independencia es fácil. Supongamos que\( C_i \subseteq U_i\) para cada uno\( i \in I \). Entonces\( \left\{g_i(X_i) \in C_i\right\} = \left\{X_i \in g_i^{-1}(C_i)\right\} \) para\( i \in I \). Por la independencia de\(\{X_i: i \in I\}\), la colección de eventos\( \left\{\left\{X_i \in g_i^{-1}(C_i)\right\}: i \in I\right\}\) es independiente.
Técnicamente, el conjunto\( U_i \) tendrá un\( \sigma \) -álgebra\( \mathscr U_i \) de subconjuntos admisibles por lo que\( (U_i, \mathscr U_i) \) es un espacio medible al igual que\( (T_i, \mathscr T_i) \) y al igual que el espacio de muestra\( (S, \mathscr S) \). Se requiere que la función\( g_i \) sea mensurable como una función de\( T_i \) dentro\( U_i \) tal como\( X_i \) es medible como una forma de función\( S \) en\( T_i \). En la prueba anterior,\( C_i \in \mathscr U_i \) así que eso\( g^{-1}(C_i) \in \mathscr T_i \) y por lo tanto\( \{X_i \in g^{-1}(C_i)\} \in \mathscr S \).
Al igual que con los eventos, la independencia (mutua) de las variables aleatorias es una propiedad muy fuerte. Si una colección de variables aleatorias es independiente, entonces cualquier subcolección también es independiente. Las nuevas variables aleatorias formadas a partir de subcolecciones disjuntas son independientes. Para un ejemplo sencillo, supongamos que\(X\),\(Y\), y\(Z\) son variables aleatorias independientes de valor real. Entonces
- \(\sin(X)\),\(\cos(Y)\), y\(e^Z\) son independientes.
- \((X, Y)\)y\(Z\) son independientes.
- \(X^2 + Y^2\)y\(\arctan(Z)\) son independientes.
- \(X\)y\(Z\) son independientes.
- \(Y\)y\(Z\) son independientes.
En particular, señalar que el enunciado 2 de la lista anterior es mucho más fuerte que la conjunción de los enunciados 4 y 5. Contrapositivamente, si\(X\) y\(Z\) son dependientes, entonces\((X, Y)\) y también\(Z\) son dependientes. Independencia de variables aleatorias subsume independencia de eventos.
Una colección de eventos\(\mathscr{A}\) es independiente si y solo si la colección correspondiente de variables indicadoras\(\left\{\bs{1}_A: A \in \mathscr{A}\right\}\) es independiente.
Prueba
Let\( \mathscr A = \{A_i: i \in I\} \) donde\( I \) es un conjunto de índices no vacíos. Para\( i \in I \), los únicos eventos no triviales que se pueden definir en términos de\( \bs 1_{A_i} \) son\( \left\{\bs 1_{A_i} = 1\right\} = A_i \) y\( \left\{\bs 1_{A_i} = 0\right\} = A_i^c \). Entonces\( \left\{\bs 1_{A_i}: i \in I\right\} \) es independiente si y sólo si cada colección del formulario\( \{B_i: i \in I\} \) es independiente, donde para cada uno\( i \in I \), ya sea\( B_i = A_i \) o\( B_i = A_i^c \). Pero por el teorema del complemento, esto equivale a la independencia de\( \{A_i: i \in I\} \).
Muchos de los conceptos que hemos estado usando de manera informal ahora se pueden precisar. Un experimento compuesto que consiste en etapas independientes
es esencialmente solo un experimento cuyo resultado es una secuencia de variables aleatorias independientes\(\bs{X} = (X_1, X_2, \ldots)\) donde\(X_i\) es el resultado de la etapa\(i\) th.
En particular, supongamos que tenemos un experimento básico con variable de resultado\(X\). Por definición, el resultado del experimento que consiste en replicaciones independientes
del experimento básico es una secuencia de variables aleatorias independientes\(\bs{X} = (X_1, X_2, \ldots)\) cada una con la misma distribución de probabilidad que\(X\). Esto es fundamental para el concepto mismo de probabilidad, tal como se expresa en la ley de los grandes números. Desde un punto de vista estadístico, supongamos que tenemos una población de objetos y un vector de medidas\(X\) de interés para los objetos de la muestra. La secuencia\(\bs{X}\) anterior corresponde al muestreo de la distribución de\(X\); es decir,\(X_i\) es el vector de mediciones para el objeto\(i\) th extraído de la muestra. Cuando se toma una muestra de una población finita, el muestreo con reemplazo genera variables aleatorias independientes mientras que el muestreo sin reemplazo genera variables aleatorias dependientes.
Independencia condicional y probabilidad condicional
Como se señaló al inicio de nuestra discusión, la independencia de eventos o variables aleatorias depende de la medida de probabilidad subyacente. Así, supongamos que\(B\) es un evento con probabilidad positiva. Una colección de eventos o una colección de variables aleatorias es condicionalmente independiente dado\(B\) si la colección es independiente en relación con la medida de probabilidad condicional\(A \mapsto \P(A \mid B)\). Por ejemplo, una colección de eventos\( \{A_i: i \in I\} \) es condicionalmente independiente dado\( B \) si por cada finito\( J \subseteq I \),\[\P\left(\bigcap_{j \in J} A_j \biggm| B \right) = \prod_{j \in J} \P(A_j \mid B)\] Tenga en cuenta que las definiciones y teoremas de esta sección seguirían siendo ciertos, pero con todas las probabilidades condicionadas\(B\).
Por el contrario, la probabilidad condicional tiene una interpretación agradable en términos de repeticiones independientes del experimento. Así, supongamos que comenzamos con un experimento básico con\(S\) como conjunto de resultados. Dejamos\(X\) denotar la variable aleatoria de resultado, de modo que matemáticamente\(X\) es simplemente la función de identidad en\(S\). En particular, si\(A\) es un evento entonces trivialmente,\(\P(X \in A) = \P(A)\). Supongamos ahora que replicamos el experimento de forma independiente. Esto da como resultado un nuevo experimento compuesto con una secuencia de variables aleatorias independientes\((X_1, X_2, \ldots)\), cada una con la misma distribución que\(X\). Es decir,\( X_i \) es el resultado de la repetición\( i \) th del experimento.
Supongamos ahora que\(A\) y\(B\) son eventos en el experimento básico con\(\P(B) \gt 0\). En el experimento compuesto, el evento que cuando\(B\) ocurre por primera vez,\(A\) también ocurre
tiene probabilidad\[\frac{\P(A \cap B)}{\P(B)} = \P(A \mid B)\]
Prueba
En el experimento compuesto, si registramos\( (X_1, X_2, \ldots) \) entonces el nuevo conjunto de resultados es\( S^\infty = S \times S \times \cdots \). El suceso que cuando\(B\) ocurre por primera vez,\(A\) también ocurre
es\[\bigcup_{n=1}^\infty \left\{X_1 \notin B, X_2 \notin B, \ldots, X_{n-1} \notin B, X_n \in A \cap B\right\}\] Los eventos en la unión son disjuntos. También, dado que\( (X_1, X_2, \ldots) \) es una secuencia de variables independientes, cada una con la distribución de\( X \) tenemos\[ \P\left(X_1 \notin B, X_2 \notin B, \ldots, X_{n-1} \notin B, X_n \in A \cap B\right) = \left[\P\left(B^c\right)\right]^{n-1} \P(A \cap B) = \left[1 - \P(B)\right]^{n-1} \P(A \cap B) \] Por lo tanto, utilizando series geométricas, la probabilidad de la unión es\[ \sum_{n=1}^\infty \left[1 - \P(B)\right]^{n-1} \P(A \cap B) = \frac{\P(A \cap B)}{1 - \left[1 - \P(B)\right]} = \frac{\P(A \cap B)}{\P(B)} \]
Argumento heurístico
Supongamos que creamos un nuevo experimento repitiendo el experimento básico hasta que\(B\) ocurra por primera vez, para luego registrar el resultado de solo la última repetición del experimento básico. Ahora el conjunto de resultados es simple\( B \) y la medida de probabilidad apropiada en el nuevo experimento es\(A \mapsto \P(A \mid B)\).
Supongamos que\(A\) y\(B\) son eventos disjuntos en un experimento básico con\(\P(A) \gt 0\) y\(\P(B) \gt 0\). En el experimento compuesto obtenido replicando el experimento básico, el evento que \(A\)ocurre antes\(B\)
tiene probabilidad\[\frac{\P(A)}{\P(A) + \P(B)}\]
Prueba
Tenga en cuenta que el evento \( A \)ocurre antes\( B \)
es el mismo que el evento cuando\( A \cup B \) ocurre por primera vez,\( A \) ocurre
.
Ejemplos y Aplicaciones
Reglas Básicas
Supongamos que\(A\)\(B\),, y\(C\) son eventos independientes en un experimento con\(\P(A) = 0.3\),\(\P(B) = 0.4\), y\(\P(C) = 0.8\). Exprese cada uno de los siguientes eventos en notación de conjuntos y encuentre su probabilidad:
- Los tres eventos ocurren.
- Ninguno de los tres eventos ocurre.
- Al menos uno de los tres eventos ocurre.
- Al menos uno de los tres eventos no ocurre.
- Exactamente uno de los tres eventos ocurre.
- Exactamente dos de los tres eventos ocurren.
Responder
- \(\P(A \cap B \cap C) = 0.096\)
- \(\P(A^c \cap B^c \cap C^c) = 0.084\)
- \(\P(A \cup B \cup C) = 0.916\)
- \( \P(A^c \cup B^c \cup C^c) = 0.904 \)
- \(\P[(A \cap B^c \cap C^c) \cup (A^c \cap B \cap C^c) \cup (A^c \cap B^c \cap C)] = 0.428\)
- \(\P[(A \cap B \cap C^c) \cup (A \cap B^c \cap C) \cup (A^c \cap B \cap C)] = 0.392\)
Supongamos que\(A\)\(B\),, y\(C\) son eventos independientes para un experimento con\(\P(A) = \frac{1}{3}\),\(\P(B) = \frac{1}{4}\), y\(\P(C) = \frac{1}{5}\). Encuentra la probabilidad de cada uno de los siguientes eventos:
- \((A \cap B) \cup C\)
- \(A \cup B^c \cup C\)
- \((A^c \cap B^c) \cup C^c\)
Responder
- \(\frac{4}{15}\)
- \(\frac{13}{15}\)
- \(\frac{9}{10}\)
Poblaciones simples
Una pequeña empresa tiene 100 empleados; 40 son hombres y 60 son mujeres. Hay 6 ejecutivos masculinos. ¿Cuántas mujeres ejecutivas debería haber si el género y el rango son independientes? El experimento subyacente es elegir un empleado al azar.
Responder
9
Supongamos que una granja tiene cuatro huertos que producen melocotones, y que los melocotones se clasifican por tamaño como pequeños, medianos y grandes. La siguiente tabla da el número total de melocotones en una cosecha reciente por huerto y por tamaño. Rellenar el cuerpo de la tabla con recuentos para las diversas intersecciones, de manera que el huerto y el tamaño sean variables independientes. El experimento subyacente es seleccionar un durazno al azar de la granja.
| Frecuencia | Tamaño Pequeño | Mediano | Grande | Total |
|---|---|---|---|---|
| Huerto 1 | 400 | |||
| 2 | 600 | |||
| 3 | 300 | |||
| 4 | 700 | |||
| Total | 400 | 1000 | 600 | 2000 |
Responder
| Frecuencia | Tamaño Pequeño | Mediano | Grande | Total |
|---|---|---|---|---|
| Huerto 1 | 80 | 200 | 120 | 400 |
| 2 | 120 | 300 | 180 | 600 |
| 3 | 60 | 150 | 90 | 300 |
| 4 | 140 | 350 | 210 | 700 |
| total | 400 | 1000 | 600 | 2000 |
Nota de los dos últimos ejercicios que no se puede ver
la independencia en un diagrama de Venn. Nuevamente, la independencia es un concepto teórico de medidas, no un concepto teórico de conjunto.
Juicios de Bernoulli
Una secuencia de ensayos de Bernoulli es una secuencia\(\bs{X} = (X_1, X_2, \ldots)\) de variables indicadoras independientes, distribuidas idénticamente. La variable aleatoria\(X_i\) es el resultado del ensayo\(i\), donde en la terminología habitual de la teoría de la confiabilidad, 1 denota éxito y 0 denota fracaso. El ejemplo canónico es la secuencia de puntuaciones cuando una moneda (no necesariamente justa) es arrojada repetidamente. Otro ejemplo básico surge cada vez que comenzamos con un experimento básico y un evento\(A\) de interés, para luego repetir el experimento. En esta configuración,\(X_i\) se encuentra la variable indicadora para evento\(A\) en el\(i\) th run del experimento. El proceso de ensayos de Bernoulli lleva el nombre de Jacob Bernoulli, y tiene un único parámetro básico\(p = \P(X_i = 1)\). Este proceso aleatorio se estudia en detalle en el capítulo sobre los ensayos de Bernoulli.
Para\((x_1, x_2, \ldots, x_n) \in \{0, 1\}^n\),\[\P(X_1 = x_1, X_2 = x_2, \ldots, X_n = x_n) = p^{x_1 + x_2 + \cdots + x_n} (1 - p)^{n - (x_1 + x_2 + \cdots + x_n)} \]
Prueba
Si\( X \) es un ensayo genérico de Bernoulli, entonces por definición,\( \P(X = 1) = p \) y\( \P(X = 0) = 1 - p \). Equivalentemente,\( \P(X = x) = p^x (1 - p)^{1 - x} \) para\( x \in \{0, 1\} \). De esta manera, el resultado sigue por la independencia.
Tenga en cuenta que la secuencia de variables aleatorias indicadoras\(\bs{X}\) es intercambiable. Es decir, si la secuencia\((x_1, x_2, \ldots, x_n)\) en el resultado anterior se permuta, la probabilidad no cambia. Por otro lado, existen secuencias intercambiables de variables aleatorias indicadoras que son dependientes, como lo ilustra tan dramáticamente el modelo de urna de Pólya.
Vamos a\(Y\) denotar el número de éxitos en los primeros\(n\) ensayos. Entonces\[\P(Y = y) = \binom{n}{y} p^y (1 - p)^{n-y}, \quad y \in \{0, 1, \ldots, n\}\]
Prueba
Obsérvese que\( Y = \sum_{i=1}^n X_i \), donde\( X_i \) está el resultado del juicio\( i \), como en el resultado anterior. Para\( y \in \{0, 1, \ldots, n\} \), el evento\( \{Y = y\} \) ocurre si y sólo si exactamente\( y \) de los\( n \) ensayos resultan en éxito (1). El número de formas de elegir los\( y \) ensayos que dan como resultado éxito es\( \binom{n}{y} \), y por el resultado anterior, la probabilidad de cualquier secuencia particular de\( y \) éxitos y\( n - y \) fracasos es\( p^y (1 - p)^{n-y} \). Así el resultado sigue por la aditividad de la probabilidad.
La distribución de\(Y\) se denomina distribución binomial con parámetros\(n\) y\(p\). La distribución binomial se estudia con más detalle en el capítulo de Ensayos de Bernoulli.
De manera más general, una secuencia de ensayos multinomiales es una secuencia\(\bs{X} = (X_1, X_2, \ldots)\) de variables aleatorias independientes, distribuidas idénticamente, cada una tomando valores en un conjunto finito\(S\). El ejemplo canónico es la secuencia de partituras cuando se lanza repetidamente un dado\(k\) -sided (no necesariamente justo). Los ensayos multinomiales también se estudian en detalle en el capítulo sobre los ensayos de Bernoulli.
Tarjetas
Considera el experimento que consiste en repartir 2 cartas al azar de una baraja estándar y registrar la secuencia de cartas repartidas. Para\(i \in \{1, 2\}\), deja\(Q_i\) ser el evento que la tarjeta\(i\) es una reina y\(H_i\) el evento que la tarjeta\(i\) es un corazón. Calcular las probabilidades apropiadas para verificar los siguientes resultados. Reflexionar sobre estos resultados.
- \(Q_1\)y\(H_1\) son independientes.
- \(Q_2\)y\(H_2\) son independientes.
- \(Q_1\)y\(Q_2\) están correlacionados negativamente.
- \(H_1\)y\(H_2\) están correlacionados negativamente.
- \(Q_1\)y\(H_2\) son independientes.
- \(H_1\)y\(Q_2\) son independientes.
Responder
- \(\P(Q_1) = \P(Q_1 \mid H_1) = \frac{1}{13}\)
- \(\P(Q_2) = \P(Q_2 \mid H_2) = \frac{1}{13}\)
- \(\P(Q_1) = \frac{1}{13}\),\(\P(Q_1 \mid Q_2) = \frac{1}{17}\)
- \(\P(H_1) = \frac{1}{4}\),\(\P(H_1 \mid H_2) = \frac{4}{17}\)
- \(\P(Q_1) = \P(Q_1 \mid H_2) = \frac{1}{13}\)
- \(\P(Q_2) = \P(Q_2 \mid H_1) = \frac{1}{13}\)
En el experimento de cartas, set\(n = 2\). Ejecute la simulación 500 veces. Para cada par de eventos del ejercicio anterior, computar el producto de las probabilidades empíricas y la probabilidad empírica de la intersección. Compara los resultados.
Dados
El siguiente ejercicio da tres eventos que son independientes por pares, pero no (mutuamente) independientes.
Considera el experimento de dados que consiste en rodar 2 dados estándar, justos y registrar la secuencia de partituras. Dejar\(A\) denotar el evento de que el primer puntaje es 3,\(B\) el evento de que el segundo puntaje es 4, y\(C\) el evento de que la suma de los puntajes es 7. Entonces
- \(A\),\(B\),\(C\) son independientes por pares.
- \(A \cap B\)implica (es un subconjunto de)\(C\) y por lo tanto estos eventos son dependientes en el sentido más fuerte posible.
Responder
Tenga en cuenta que\( A \cap B = A \cap C = B \cap C = \{(3, 4)\} \), y la probabilidad de la intersección común es\( \frac{1}{36} \). Por otro lado,\( \P(A) = \P(B) = \P(C) = \frac{6}{36} = \frac{1}{6} \).
En el experimento de dados, set\(n = 2\). Ejecuta el experimento 500 veces. Para cada par de eventos del ejercicio anterior, computar el producto de las probabilidades empíricas y la probabilidad empírica de la intersección. Compara los resultados.
El siguiente ejercicio da un ejemplo de tres eventos con la propiedad de que la probabilidad de la intersección es producto de las probabilidades, pero los eventos no son independientes por pares.
Supongamos que lanzamos un estándar, justo morir una vez. Vamos\(A = \{1, 2, 3, 4\}\),\(B = C = \{4, 5, 6\}\). Entonces
- \(\P(A \cap B \cap C) = \P(A) \P(B) \P(C)\).
- \(B\)y\(C\) son el mismo acontecimiento, y por lo tanto son dependientes en el sentido más fuerte posible.
Responder
Tenga en cuenta que\( A \cap B \cap C = \{4\} \), entonces\( \P(A \cap B \cap C) = \frac{1}{6} \). Por otro lado,\( \P(A) = \frac{4}{6} \) y\( \P(B) = \P(C) = \frac{3}{6} \).
Supongamos que un dado estándar, justo es arrojado 4 veces. Encuentra la probabilidad de los siguientes eventos.
- Seis no ocurre.
- Seis ocurre al menos una vez.
- La suma de los dos primeros puntajes es 5 y la suma de los dos últimos puntajes es 7.
Responder
- \(\left(\frac{5}{6}\right)^4 \approx 0.4823\)
- \(1 - \left(\frac{5}{6}\right)^4 \approx 0.5177\)
- \(\frac{1}{54}\)
Supongamos que se lanzan 8 veces un par de dados estándar y justos. Encuentra la probabilidad de cada uno de los siguientes eventos.
- El doble seis no ocurre.
- El doble seis ocurre al menos una vez.
- El doble seis no ocurre en los primeros 4 lanzamientos sino que ocurre al menos una vez en los últimos 4 lanzamientos.
Responder
- \(\left(\frac{35}{36}\right)^8 \approx 0.7982\)
- \(1 - \left(\frac{35}{36}\right)^8 \approx 0.2018\)
- \(\left(\frac{35}{36}\right)^4 \left[1 - \left(\frac{35}{36}\right)^4\right] \approx 0.0952\)
Considere el experimento de dados que consiste en rodar\(n\), dar\(k\) lados a dados y registrar la secuencia de partituras.\(\bs{X} = (X_1, X_2, \ldots, X_n)\) Las siguientes condiciones son equivalentes (y corresponden a la suposición de que los dados son justos):
- \(\bs{X}\)se distribuye uniformemente en\(\{1, 2, \ldots, k\}^n\).
- \(\bs{X}\)es una secuencia de variables independientes, y\(X_i\) se distribuye uniformemente\(\{1, 2, \ldots, k\}\) para cada una\(i\).
Prueba
Vamos\( S = \{1, 2, \ldots, k\} \) a anotar que\( S^n \) tiene\( k^n \) puntos. Supongamos que\( \bs{X} \) se distribuye uniformemente en\( S^n \). Entonces\( \P(\bs{X} = \bs{x}) = 1 / k^n \) para cada uno\( \bs{x} \in S^n \) así\( \P(X_i = x) = k^{n-1}/k^n = 1 / k \) para cada uno\( x \in S \). De ahí\( X_i \) que se distribuya uniformemente en\( S \). Además,\[ \P(\bs{X} = \bs{x}) = \P(X_1 = x_1) \P(X_2 = x_2) \cdots \P(X_n = x_n), \quad \bs{x} = (x_1, x_2, \ldots, x_n) \in S^n \] también lo\( \bs{X} \) es una secuencia independiente. Por el contrario, si\( \bs{X} \) es una secuencia independiente y\( X_i \) se distribuye uniformemente\( S \) para cada uno\( i \) entonces\( \P(X_i = x) = 1/k \) para cada uno\( x \in S \) y por lo tanto\( \P(\bs{X} = \bs{x}) = 1/k^n \) para cada uno\( \bs{x} \in S^n \). Así\( \bs{X} \) se distribuye uniformemente en\( S^n \).
Un par de dados estándar y justos se lanzan repetidamente. Encuentra la probabilidad de cada uno de los siguientes eventos.
- Una suma de 4 ocurre antes de una suma de 7.
- Una suma de 5 ocurre antes de una suma de 7.
- Una suma de 6 ocurre antes de una suma de 7.
- Cuando ocurre una suma de 8 la primera vez, ocurre de
la manera difícil
como\((4, 4)\).
Responder
- \(\frac{3}{9}\)
- \(\frac{4}{10}\)
- \(\frac{5}{11}\)
- \(\frac{1}{5}\)
Problemas del tipo en el último ejercicio son importantes en el juego de dados. Craps se estudia con más detalle en el capítulo de Juegos de azar.
Monedas
Una moneda sesgada con probabilidad de cabezas\(\frac{1}{3}\) es arrojada 5 veces. Vamos\(\bs{X}\) denotar el resultado de los lanzados (codificados como una cadena de bits) y dejar\(Y\) denotar el número de cabezas. Encuentra cada uno de los siguientes:
- \(\P(\bs{X} = \bs{x})\)para cada uno\(\bs{x} \in \{0, 1\}^5\).
- \(\P(Y = y)\)para cada uno\(y \in \{0, 1, 2, 3, 4, 5\}\).
- \(\P(1 \le Y \le 3)\)
Responder
- \(\frac{32}{243}\)si\(\bs{x} = 00000\),\(\frac{16}{243}\) si\(\bs{x}\) tiene exactamente un 1 (hay 5 de estos),\(\frac{8}{243}\) si\(\bs{x}\) tiene exactamente dos 1s (hay 10 de estos),\(\frac{4}{243}\) si\(\bs{x}\) tiene exactamente tres 1s (hay 10 de estos),\(\frac{2}{243}\) si\(\bs{x}\) tiene exactamente cuatro 1s (hay 5 de estos), \(\frac{1}{243}\)si\(\bs{x} = 11111\)
- \(\frac{32}{243}\)si\(y = 0\),\(\frac{80}{243}\) si\(y = 1\)\(y = 2\),\(\frac{80}{243}\)\(\frac{40}{243}\) si\(y = 3\),\(\frac{10}{243}\) si\(y = 4\),\(\frac{1}{243}\) si\(y = 5\)
- \(\frac{200}{243}\)
Una caja contiene una moneda justa y una moneda de dos cabezas. Una moneda se elige al azar de la caja y se lanza repetidamente. Vamos a\(F\) denotar el evento en el que se elige la moneda justa, y vamos a\(H_i\) denotar el evento que el\(i\) th tirar resulta en cabezas. Entonces
- \((H_1, H_2, \ldots)\)son condicionalmente independientes dados\(F\), con\(\P(H_i \mid F) = \frac{1}{2}\) para cada uno\(i\).
- \((H_1, H_2, \ldots)\)son condicionalmente independientes dados\(F^c\), con\(\P(H_i \mid F^c) = 1\) para cada uno\(i\).
- \(\P(H_i) = \frac{3}{4}\)para cada uno\(i\).
- \(\P(H_1 \cap H_2 \cap \cdots \cap H_n) = \frac{1}{2^{n+1}} + \frac{1}{2}\).
- \((H_1, H_2, \ldots)\)son dependientes.
- \(\P(F \mid H_1 \cap H_2 \cap \cdots \cap H_n) = \frac{1}{2^n + 1}\).
- \(\P(F \mid H_1 \cap H_2 \cap \cdots \cap H_n) \to 0\)como\(n \to \infty\).
Prueba
Las partes (a) y (b) son esencialmente supuestos de modelado, basados en el diseño del experimento. Si sabemos qué tipo de moneda tenemos, entonces los lanzamientos son independientes. Las partes (c) y (d) siguen condicionando el tipo de moneda y utilizando las partes (a) y (b). La parte e) se desprende de las incisiones c) y d). Obsérvese que la expresión en (d) no lo es\((3/4)^n\). La parte (f) se desprende de la parte (d) y del teorema de Bayes. Por último, la parte g) se desprende de la parte f).
Consideremos nuevamente la caja en el ejercicio anterior, pero cambiamos el experimento de la siguiente manera: se elige una moneda al azar de la caja y se lanza y se registra el resultado. La moneda se devuelve a la caja y se repite el proceso. Como antes, vamos a\(H_i\) denotar el suceso que\(i\) arroja resultados en cabezas. Entonces
- \((H_1, H_2, \ldots)\)son independientes.
- \(\P(H_i) = \frac{3}{4}\)para cada uno\(i\).
- \(\P(H_1 \cap H_2 \cap \cdots H_n) = \left(\frac{3}{4}\right)^n\).
Prueba
Nuevamente, la parte (a) es esencialmente una suposición de modelado. Dado que devolvemos la moneda y dibujamos una nueva moneda al azar cada vez, los resultados de los tirados deben ser independientes. La parte (b) sigue condicionando el tipo de la moneda\(i\) th. La parte c) se desprende de las partes a) y b).
Piense detenidamente en los resultados de los dos ejercicios anteriores, y las diferencias entre los dos modelos. Lanzar una moneda produce variables aleatorias independientes si la probabilidad de cabezas es fija (es decir, no aleatoria incluso si se desconoce). El lanzamiento de una moneda con una probabilidad aleatoria de cabezas generalmente no produce variables aleatorias independientes; el resultado de un lanzamiento da información sobre la probabilidad de cabezas que a su vez da información sobre tiradas posteriores.
Distribuciones Uniformes
Recordemos que el experimento de monedas de Buffon consiste en lanzar una moneda con radio\(r \le \frac{1}{2}\) al azar sobre un piso cubierto con azulejos cuadrados de longitud lateral 1. Las coordenadas\((X, Y)\) del centro de la moneda se registran con relación a los ejes a través del centro del cuadrado en el que aterriza la moneda. Las siguientes condiciones son equivalentes:
- \((X, Y)\)se distribuye uniformemente en\(\left[-\frac{1}{2}, \frac{1}{2}\right]^2\).
- \(X\)y\(Y\) son independientes y cada uno se distribuye uniformemente en\(\left[-\frac{1}{2}, \frac{1}{2}\right]\).
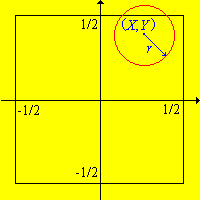.png)
Figura\(\PageIndex{1}\): Experimento de monedas de Buffon
Prueba
Deje\( S = \left[-\frac{1}{2}, \frac{1}{2}\right] \), y deje\( \lambda_1 \) denotar la medida de longitud\( S \) y la medida del\( \lambda_2 \) área en\( S^2 \). Tenga en cuenta que\(\lambda_1(S) = \lambda_2(S^2) = 1\). Supongamos que\( (X, Y) \) se distribuye uniformemente en\( S^2 \), de modo que\( \P\left[(X, Y) \in C\right] = \lambda_2(C) \) para\( C \subseteq S^2 \). Para\( A \subseteq S \),\[\P(X \in A) = \P\left[(X, Y) \in A \times S\right] = \lambda_2(A \times S) = \lambda_1(A)\] Por lo tanto\( X \) se distribuye uniformemente en\( S \). Por un argumento similar, también\( Y \) se distribuye uniformemente en\( S \). Además, para\( A \subseteq S \) y\( B \subseteq S \),\[ \P(X \in A, Y \in B) = \P[(X, Y) \in A \times B] = \lambda_2(A \times B) = \lambda_1(A) \lambda_1(B) = \P(X \in A) \P(Y \in B) \] así\( X \) y\( Y \) son independientes. Por el contrario, si\( X \) y\( Y \) son independientes y cada uno se distribuye uniformemente sobre\( S \), entonces para\( A \subseteq S \) y\( B \subseteq S \), Entonces\[ \P\left[(X, Y) \in A \times B\right] = \P(X \in A) \P(Y \in B) = \lambda_1(A) \lambda_1(B) = \lambda_2(A \times B) \] se deduce que\( \P\left[(X, Y) \in C\right] = \lambda_2(C) \) para cada\( C \subseteq S^2 \). Para más detalles sobre este último paso, consulte la sección avanzada sobre existencia y singularidad de las medidas.
Compara este resultado con el resultado anterior para dados justos.
En el experimento de monedas de Buffon, set\(r = 0.3\). Ejecute la simulación 500 veces. Para los eventos\(\{X \gt 0\}\) y\(\{Y \lt 0\}\), computar el producto de las probabilidades empíricas y la probabilidad empírica de la intersección. Compara los resultados.
La hora\(X\) de llegada del\(A\) tren se distribuye uniformemente en el intervalo\((0, 30)\), mientras que la hora\(Y\) de llegada del\(B\) tren se distribuye uniformemente en el intervalo\((15, 30)\). (Los horarios de llegada son en minutos, después de las 8:00 AM). Además, los horarios de llegada son independientes. Encuentra la probabilidad de cada uno de los siguientes eventos:
- El\(A\) tren llega primero.
- Ambos trenes llegan en algún momento después de 20 minutos.
Responder
- \(\frac{3}{4}\)
- \(\frac{2}{9}\)
Confiabilidad
Recordemos el modelo simple de confiabilidad estructural en el que un sistema está compuesto por\(n\) componentes. Supongamos además que los componentes operan independientemente unos de otros. Como antes, vamos a\(X_i\) denotar el estado del componente\(i\), donde 1 significa trabajar y 0 significa falla. Por lo tanto, nuestra suposición básica es que el vector de estado\(\bs{X} = (X_1, X_2, \ldots, X_n)\) es una secuencia de variables aleatorias indicadoras independientes. Suponemos que el estado del sistema (ya sea funcionando o fallido) depende únicamente de los estados de los componentes. Así, el estado del sistema es una variable aleatoria indicadora\[Y = y(X_1, X_2, \ldots, X_n)\] donde\( y: \{0, 1\}^n \to \{0, 1\} \) está la función de estructura. Generalmente, la probabilidad de que un dispositivo esté funcionando es la confiabilidad del dispositivo. Así, vamos a denotar la fiabilidad del componente\(i\) por\(p_i = \P(X_i = 1)\) lo que el vector de fiabilidades de los componentes es\(\bs{p} = (p_1, p_2, \ldots, p_n)\). Por independencia, la confiabilidad del sistema\(r\) es una función de las fiabilidades de los componentes:\[r(p_1, p_2, \ldots, p_n) = \P(Y = 1)\] Apropiadamente, esta función se conoce como la función de confiabilidad. Nuestro reto suele ser encontrar la función de confiabilidad, dada la función de estructura. Cuando todos los componentes tienen la misma probabilidad\(p\) entonces, por supuesto, la confiabilidad del sistema\(r\) es solo una función de\(p\). En este caso, el vector estatal\(\bs{X} = (X_1, X_2, \ldots, X_n)\) forma una secuencia de ensayos de Bernoulli.
Comenta sobre el supuesto de independencia para sistemas reales, como tu auto o tu computadora.
Recordemos que un sistema en serie está funcionando si y sólo si cada componente está funcionando.
- El estado del sistema es\(U = X_1 X_2 \cdots X_n = \min\{X_1, X_2, \ldots, X_n\}\).
- La fiabilidad es\(\P(U = 1) = p_1 p_2 \cdots p_n\).
Recordemos que un sistema paralelo está funcionando si y sólo si al menos un componente está funcionando.
- El estado del sistema es\(V = 1 - (1 - X_1)(1 - X_2) \cdots (1 - X_n) = \max\{X_1, X_2, \ldots, X_n\}\).
- La fiabilidad es\(\P(V = 1) = 1 - (1 - p_1) (1 - p_2) \cdots (1 - p_n)\).
Recordemos que un sistema \(k\)fuera de\(n\) sistema está funcionando si y sólo si al menos\(k\) de los\(n\) componentes están funcionando. Por lo tanto, un sistema paralelo es un 1 fuera del\(n\) sistema y un sistema en serie es un sistema\(n\) fuera de\(n\) sistema. Un sistema\(k\) fuera de\(2 k - 1\) sistema es un sistema de reglas mayoritarias. La función de confiabilidad de un general\(k\) fuera del\(n\) sistema es un desastre. Sin embargo, si las fiabilidades de los componentes son las mismas, la función tiene una forma razonablemente simple.
Para un sistema\(k\) fuera del\(n\) sistema con confiabilidad común de los componentes\(p\), la confiabilidad del sistema es\[r(p) = \sum_{i = k}^n \binom{n}{i} p^i (1 - p)^{n - i}\]
Considera un sistema de 3 componentes independientes con confiabilidad común\(p = 0.8\). Encuentre la confiabilidad de cada uno de los siguientes:
- El sistema paralelo.
- El sistema 2 de 3.
- El sistema en serie.
Responder
- 0.992
- 0.896
- 0.512
Considerar un sistema de 3 componentes independientes con fiabilidades\(p_1 = 0.8\),\(p_2 = 0.8\),\(p_3 = 0.7\). Encuentre la confiabilidad de cada uno de los siguientes:
- El sistema paralelo.
- El sistema 2 de 3.
- El sistema en serie.
Responder
- 0.994
- 0.902
- 0.504
Considera un avión con un número impar de motores, cada uno con confiabilidad\(p\). Supongamos que el avión es un sistema de reglas mayoritarias, por lo que el avión necesita una mayoría de motores que funcionen para poder volar.
- Encuentre la confiabilidad de un avión de 3 motores en función de\(p\).
- Encuentre la confiabilidad de un avión de 5 motores en función de\(p\).
- ¿Para qué valores de un avión de 5 motores\(p\) es preferible a un avión de 3 motores?
Responder
- \(r_3(p) = 3 \, p^2 - 2 \, p^3\)
- \(r_5(p) = 6 \, p^5 - 15 \, p^4 + 10 p^3\)
- El avión de 5 motores sería preferible si\(p \gt \frac{1}{2}\) (cuál esperaría sería el caso). El avión de 3 motores sería preferible si\(p \lt \frac{1}{2}\). Si\(p = \frac{1}{2}\), los planos de 3 motores y 5 motores son igualmente confiables.
El gráfico a continuación se conoce como la red de puentes de Wheatstone y lleva el nombre de Charles Wheatstone. Los bordes representan componentes, y el sistema funciona si y solo si hay una ruta de trabajo de vértice\(a\) a vértice\(b\).
- Encuentra la función de estructura.
- Encuentre la función de confiabilidad.
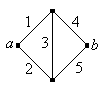.png)
Figura\(\PageIndex{2}\): El netwok del puente Wheatstone
Responder
- \(Y = X_3 (X_1 + X_2 - X_1 X_2)(X_4 + X_5 - X_4, X_5) + (1 - X_3)(X_1 X_4 + X_2 X_5 - X_1 X_2 X_4 X_5)\)
- \(r(p_1, p_2, p_3, p_4, p_5) = p_3 (p_1 + p_2 - p_1 p_2)(p_4 + p_5 - p_4, p_5) + (1 - p_3)(p_1 p_4 + p_2 p_5 - p_1 p_2 p_4 p_5)\)
Un sistema consta de 3 componentes, conectados en paralelo. Debido a factores ambientales, los componentes no operan de manera independiente, por lo que nuestra suposición habitual no se sostiene. Sin embargo, asumiremos que bajo condiciones de baja tensión, los componentes son independientes, cada uno con confiabilidad 0.9; bajo condiciones de tensión media, los componentes son independientes con confiabilidad 0.8; y bajo condiciones de alto esfuerzo, los componentes son independientes, cada uno con confiabilidad 0.7. La probabilidad de estrés bajo es 0.5, de estrés medio es 0.3 y de estrés alto es 0.2.
- Encuentra la confiabilidad del sistema.
- Dado que el sistema funciona, encuentra la probabilidad condicional de cada nivel de estrés.
Responder
- 0.9917. Condición en el nivel de estrés.
- 0.5037 para bajo, 0.3001 para medio, 0.1962 para alto. Usa el teorema de Bayes y la parte (a).
Suponga que los bits se transmiten a través de un canal de comunicaciones ruidoso. Cada bit que se envía, independientemente de los demás, se recibe correctamente con probabilidad 0.9 y se cambia al bit complementario con probabilidad 0.1. Usando redundancia para mejorar la confiabilidad, supongamos que un bit dado será enviado 3 veces. Naturalmente, queremos calcular la probabilidad de que identifiquemos correctamente el bit que se envió. Supongamos que no tenemos conocimiento previo del bit, por lo que asignamos probabilidad\(\frac{1}{2}\) cada uno al evento de que se envió 000 y al evento que se envió 111. Ahora encuentra la probabilidad condicional de que 111 fue enviado dada cada una de las 8 posibles cadenas de bits recibidas.
Responder
Dejar\(\bs{X}\) denotar la cadena enviada y\(\bs{Y}\) la cadena recibida.
| \(\bs{y}\) | \(\P(\bs{X} = 111 \mid \bs{Y} = \bs{y})\) |
|---|---|
| 111 | \(729/730\) |
| 110 | \(9/10\) |
| 101 | \(9/10\) |
| 011 | \(9/10\) |
| 100 | \(1/10\) |
| 010 | \(1/10\) |
| 001 | \(1/10\) |
| 000 | \(1/730\) |
Pruebas de diagnóstico
Recordemos la discusión de las pruebas diagnósticas en el apartado Probabilidad Condicional. Así, tenemos un evento\(A\) para un experimento aleatorio cuya ocurrencia o no ocurrencia no podemos observar directamente. Supongamos ahora que tenemos\(n\) pruebas para la ocurrencia de\(A\), etiquetada de 1 a\(n\). Vamos a dejar\(T_i\) denotar el evento para el que la prueba\(i\) es positiva\(A\). Las pruebas son independientes en el siguiente sentido:
- Si\(A\) ocurre, entonces\((T_1, T_2, \ldots, T_n)\) son (condicionalmente) independientes y la prueba\(i\) tiene sensibilidad\(a_i = \P(T_i \mid A)\).
- Si\(A\) no ocurre, entonces\((T_1, T_2, \ldots, T_n)\) son (condicionalmente) independientes y la prueba\(i\) tiene especificidad\(b_i = \P(T_i^c \mid A^c)\).
Tenga en cuenta que incondicionalmente, no es razonable suponer que las pruebas son independientes. Por ejemplo, un resultado positivo para una prueba dada presumiblemente es evidencia de que el padecimiento\(A\) ha ocurrido, lo que a su vez es evidencia de que una prueba posterior será positiva. En definitiva, eso esperamos\(T_i\) y\(T_j\) debe estar correlacionado positivamente.
Podemos formar una nueva prueba compuesta dando una regla de decisión en términos de los resultados de las pruebas individuales. En otras palabras, el evento para el\(T\) que la prueba compuesta es positiva\(A\) es una función de\((T_1, T_2, \ldots, T_n)\). Las reglas típicas de decisión son muy similares a las estructuras de confiabilidad discutidas anteriormente. Un caso especial de interés es cuando las\(n\) pruebas son aplicaciones independientes de una prueba básica dada. En este caso,\(a_i = a\) y\(b_i = b\) para cada uno\(i\).
Considera la prueba compuesta que es positiva para\(A\) si y solo si cada una de las\(n\) pruebas es positiva para\(A\).
- \(T = T_1 \cap T_2 \cap \cdots \cap T_n\)
- La sensibilidad es\(\P(T \mid A) = a_1 a_2 \cdots a_n\).
- La especificidad es\(\P(T^c \mid A^c) = 1 - (1 - b_1) (1 - b_2) \cdots (1 - b_n)\)
Considera la prueba compuesta que es positiva para\(A\) si y solo si cada al menos una de las\(n\) pruebas es positiva para\(A\).
- \(T = T_1 \cup T_2 \cup \cdots \cup T_n\)
- La sensibilidad es\(\P(T \mid A) = 1 - (1 - a_1) (1 - a_2) \cdots (1 - a_n)\).
- La especificidad es\(\P(T^c \mid A^c) = b_1 b_2 \cdots b_n\).
De manera más general, podríamos definir el compuesto \(k\)fuera de\(n\) prueba que es positivo para\(A\) si y solo si al menos\(k\) de las pruebas individuales son positivas para\(A\). La prueba en serie es la prueba\(n\) fuera de\(n\) prueba, mientras que la prueba paralela es la prueba 1 fuera de\(n\) prueba. El\(k\) fuera de\(2 k - 1\) prueba es la prueba de reglas mayoritarias.
Supongamos que una mujer inicialmente cree que existe una posibilidad par de que esté o no embarazada. Compra tres pruebas de embarazo idénticas con sensibilidad 0.95 y especificidad 0.90. Las pruebas 1 y 3 son positivas y la prueba 2 es negativa.
- Encuentra la probabilidad actualizada de que la mujer esté embarazada.
- ¿Podemos decir que las pruebas 2 y 3 se cancelan entre sí? Encuentra la probabilidad de que la mujer esté embarazada con solo una prueba positiva, y compara la respuesta con la respuesta a la parte (a).
Responder
- 0.834
- No: 0.905.
Supongamos que se aplican 3 pruebas independientes e idénticas para un evento\(A\), cada una con sensibilidad\(a\) y especificidad\(b\). Encuentra la sensibilidad y especificidad de las siguientes pruebas:
- 1 de 3 pruebas
- Prueba 2 de 3
- 3 de 3 pruebas
Responder
- sensibilidad\(1 - (1 - a)^3\), especificidad\(b^3\)
- sensibilidad\(3 \, a^2\), especificidad\(b^3 + 3 \, b^2 (1 - b)\)
- sensibilidad\(a^3\), especificidad\(1 - (1 - b)^3\)
En un juicio penal, el acusado es condenado si y sólo si los 6 jurados votan culpables. Supongamos que si el acusado es realmente culpable, los jurados votan culpables, independientemente, con probabilidad 0.95, mientras que si el demandado es realmente inocente, los jurados votan inocentes, independientemente con probabilidad 0.8. Supongamos que 70% de los acusados llevados a juicio son culpables.
- Encontrar la probabilidad de que el demandado sea condenado.
- Dado que el imputado es condenado, encontrar la probabilidad de que el acusado sea culpable.
- Comentar el supuesto de que los jurados actúan de manera independiente.
Responder
- 0.5148
- 0.99996
- El supuesto de independencia no es razonable ya que colaboran los jurados.
Genética
Por favor refiérase a la discusión de genética en la sección de experimentos aleatorios si necesita revisar algunas de las definiciones de esta sección.
Recordemos primero que el tipo de sangre ABO en humanos está determinado por tres alelos:\(a\),\(b\), y\(o\). Además,\(a\)\(b\) son codominantes y\(o\) recesivos. Supongamos que en cierta población, la proporción de\(a\),\(b\), y los\(o\) alelos son\(p\)\(q\), y\(r\) respectivamente. Por supuesto que debemos tener\(p \gt 0\),\(q \gt 0\),\(r \gt 0\) y\(p + q + r = 1\).
Supongamos que el genotipo sanguíneo en una persona es el resultado de alelos independientes, elegidos con probabilidades\(p\),\(q\), y\(r\) como arriba.
- La distribución de probabilidad de los geneotipos se da en la siguiente tabla:
Genotipo \(aa\) \(ab\) \(ao\) \(bb\) \(bo\) oo Probabilidad \(p^2\) \(2 p q\) \(2 p r\) \(q^2\) \(2 q r\) \(r^2\) - La distribución de probabilidad de los tipos de sangre se da en la siguiente tabla:
Tipo de sangre \(A\) \(B\) \(AB\) \(O\) Probabilidad \(p^2 + 2 p r\) \(q^2 + 2 q r\) \(2 p q\) \(r^2\)
Prueba
La parte a) se desprende del supuesto de independencia y de las reglas básicas de probabilidad. A pesar de que los genotipos se enumeran como pares desordenados, tenga en cuenta que hay dos formas en que puede ocurrir un genotipo heterocigótico, ya que cualquiera de los progenitores podría contribuir con cualquiera de los dos alelos distintos. La parte b) se desprende de la parte (a) y reglas básicas de probabilidad.
La discusión anterior se relaciona con el modelo de genética Hardy-Weinberg. El modelo lleva el nombre del matemático inglés Godfrey Hardy y el médico alemán Wilhelm Weiberg
Supongamos que la distribución de probabilidad para el conjunto de tipos sanguíneos en una determinada población se da en la siguiente tabla:
| Tipo de sangre | \(A\) | \(B\) | \(AB\) | \(O\) |
|---|---|---|---|---|
| Probabilidad | 0.360 | 0.123 | 0.038 | 0.479 |
Encontrar\(p\),\(q\), y\(r\).
Responder
\(p = 0.224\),\(q = 0.084\),\(r = 0.692\)
Supongamos a continuación que el color de la vaina en cierto tipo de planta de guisante está determinado por un gen con dos alelos:\(g\) para el verde y\(y\) para el amarillo, y que\(g\) es dominante y\(o\) recesivo.
Supongamos que 2 plantas de vainas verdes se crían juntas. Supongamos además que cada planta, independientemente, tiene el alelo recesivo de vaina amarilla con probabilidad\(\frac{1}{4}\).
- Encuentra la probabilidad de que 3 plantas descendientes tengan vainas verdes.
- Dado que las 3 plantas crías tienen vainas verdes, encuentra la probabilidad actualizada de que ambos progenitores tengan el alelo recesivo.
Responder
- \(\frac{987}{1024}\)
- \(\frac{27}{987}\)
A continuación, considere un trastorno hereditario vinculado al sexo en humanos (como el daltonismo o la hemofilia). Dejar\(h\) denotar el alelo sano y\(d\) el alelo defectuoso para el gen vinculado al trastorno. Recordemos que\(h\) es dominante y\(d\) recesivo para las mujeres.
Supongamos que una mujer sana inicialmente tiene\(\frac{1}{2}\) posibilidades de ser portadora. (Este sería el caso, por ejemplo, si su madre y su padre están sanos pero tiene un hermano con el trastorno, por lo que su madre debe ser portadora).
- Encuentra la probabilidad de que los dos primeros hijos de las mujeres estén sanos.
- Dado que los dos primeros hijos están sanos, computa la probabilidad actualizada de que sea portadora.
- Dado que los dos primeros hijos están sanos, computar la probabilidad condicional de que el tercer hijo esté sano.
Responder
- \(\frac{5}{8}\)
- \(\frac{1}{5}\)
- \(\frac{9}{10}\)
Regla Sucesión de Laplace
Supongamos que tenemos\(m + 1\) monedas, etiquetadas\(0, 1, \ldots, m\). La moneda\(i\) aterriza cabezas con probabilidad\(\frac{i}{m}\) para cada una\(i\). El experimento consiste en elegir una moneda al azar (para que cada moneda sea igualmente probable que sea elegida) y luego tirar la moneda elegida repetidamente.
- La probabilidad de que los primeros\(n\) tirados sean todos cabezas es\(p_{m,n} = \frac{1}{m+1} \sum_{i=0}^m \left(\frac{i}{m}\right)^n\)
- \(p_{m,n} \to \frac{1}{n+1} \)como\(m \to \infty\)
- La probabilidad condicional de que tirar\(n + 1\) es cabezas dado que los\(n\) lanzados anteriores fueron todos cabezas es\(\frac{p_{m,n+1}}{p_{m,n}}\)
- \(\frac{p_{m,n+1}}{p_{m,n}} \to \frac{n+1}{n+2}\)como\(m \to \infty\)
Prueba
La parte (a) sigue condicionando la moneda elegida. Para la parte (b), tenga en cuenta que\( p_{m,n} \) es una suma aproximada para\( \int_0^1 x^n \, dx = \frac{1}{n + 1} \). La parte (c) se desprende de la definición de probabilidad condicional, y la parte (d) es una consecuencia trivial de (b), (c).
Tenga en cuenta que la moneda 0 es de dos colas, la probabilidad de cabezas aumenta con\( i \), y la moneda\(m\) es de dos cabezas. La probabilidad condicional limitante en la parte (d) se llama Regla de Sucesión de Laplace, que lleva el nombre de Simon Laplace. Esta regla fue utilizada por Laplace y otros como principio general para estimar la probabilidad condicional de que un evento ocurra a tiempo\(n + 1\), dado que el evento ha ocurrido\(n\) tiempos sucesivos.
Supongamos que un misil ha tenido 10 pruebas exitosas seguidas. Calcular la estimación de Laplace de que la undécima prueba será exitosa. ¿Tiene sentido esto?
Contestar
\(\frac{11}{12}\). No, en realidad no.