
8.1: Introducción a la estimación de conjuntos
- Page ID
- 151950

Teoría Básica
El modelo estadístico básico
Como es habitual, nuestro punto de partida es un experimento aleatorio con un espacio muestral subyacente y una medida de probabilidad\(\P\). En el modelo estadístico básico, tenemos una variable aleatoria observable\(\bs{X}\) tomando valores en un conjunto\(S\). En general,\(\bs{X}\) puede tener una estructura bastante complicada. Por ejemplo, si el experimento consiste en muestrear\(n\) objetos de una población y registrar diversas mediciones de interés, entonces\[ \bs{X} = (X_1, X_2, \ldots, X_n) \] dónde\(X_i\) está el vector de mediciones para el objeto\(i\) th. El caso especial más importante ocurre cuando\((X_1, X_2, \ldots, X_n)\) son independientes e idénticamente distribuidos. En este caso, tenemos una muestra aleatoria de tamaño\(n\) de la distribución común.
Supongamos también que la distribución de\(\bs{X}\) depende de que un parámetro\(\theta\) tome valores en un espacio de parámetros\(\Theta\). El parámetro también puede ser vectorizado, en cuyo caso\(\Theta \subseteq \R^k\) para algunos\(k \in \N_+\) y el parámetro vector tiene la forma\(\bs{\theta} = (\theta_1, \theta_2, \ldots, \theta_k)\).
Conjuntos de confianza
Un conjunto de confianza es un subconjunto\(C(\bs{X})\) del espacio de parámetros\(\Theta\) que depende solo de la variable de datos\(\bs{X}\), y no hay parámetros desconocidos. el nivel de confianza es la probabilidad más pequeña de que\(\theta \in C(\bs{X})\):\[ \min\left\{\P[\theta \in C(\bs{X})]: \theta \in \Theta\right\} \]
Así, en cierto sentido, un conjunto de confianza es una estadística de valor conjunto. Un conjunto de confianza es un estimador de\(\theta\) en el sentido que esperamos que\(\theta \in C(\bs{X})\) con alta probabilidad, para que el nivel de confianza sea alto. Obsérvese que dado que la distribución de\( \bs{X} \) depende de\( \theta \), existe una dependencia de\( \theta \) en la medida de probabilidad\( \P \) en la definición de nivel de confianza. Sin embargo, solemos suprimir esto, solo para mantener la notación simple. Por lo general, tratamos de construir un conjunto de confianza para\(\theta\) con un nivel de confianza prescrito\(1 - \alpha\) donde\(0 \lt \alpha \lt 1\). Los niveles de confianza típicos son 0.9, 0.95 y 0.99. A veces lo mejor que podemos hacer es construir un conjunto de confianza cuyo nivel de confianza sea al menos\(1 - \alpha\); esto se llama un conjunto de\(1 - \alpha\) confianza conservadora para\(\theta\).
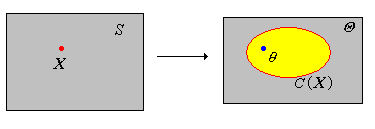
Supongamos que\(C(\bs{X})\) es\(1 - \alpha\) nivel de confianza establecido para un parámetro\(\theta\). Tenga en cuenta que cuando ejecutamos el experimento y observamos los datos\(\bs{x}\), el conjunto de confianza calculado es\(C(\bs{x})\). El verdadero valor de\(\theta\) está o bien en este conjunto, o no lo es, y por lo general nunca lo sabremos. No obstante, por la ley de los grandes números, si volviéramos a repetir el experimento de confianza una y otra vez,\(\theta\) convergería a la proporción de conjuntos que contienen\(\P[\theta \in C(\bs{X})] = 1 - \alpha\). Este es el significado preciso del término confianza. En la terminología habitual de la estadística, el conjunto aleatorio\(C(\bs{X})\) es el estimador; el conjunto determinista\(C(\bs{x})\) basado en un valor observado\(\bs{x}\) es la estimación.
A continuación, tenga en cuenta que la calidad de un conjunto de confianza, como estimador de\(\theta\), se basa en dos factores: el nivel de confianza y la precisión medida por el tamaño
del conjunto. Un buen estimador tiene un tamaño pequeño (y por lo tanto da una estimación precisa de\(\theta\)) y gran confianza. Sin embargo, para un dado\(\bs{X}\), generalmente hay una compensación entre el nivel de confianza y la precisión: aumentar el nivel de confianza viene solo a expensas de aumentar el tamaño del conjunto, y disminuir el tamaño del conjunto viene solo a expensas de disminuir el nivel de confianza. La forma en que medimos el tamaño
del conjunto de confianza depende de la dimensión del espacio de parámetros y de la naturaleza del conjunto de confianza. Además, el tamaño del conjunto suele ser aleatorio, aunque en algunos casos especiales puede ser determinista.
Considerar los casos extremos puede darnos alguna idea. Primero, supongamos que\(C(\bs{X}) = \Theta\). Este estimador conjunto tiene la máxima confianza 1, pero ninguna precisión y por lo tanto no tiene valor (ya lo sabíamos\(\theta \in \Theta\)). En el otro extremo, supongamos que\(C(\bs{X})\) es un conjunto singleton. Este estimador conjunto tiene la mejor precisión posible, pero normalmente para distribuciones continuas, tendría confianza 0. Entre estos extremos, ojalá, se establezcan estimadores que tengan alta confianza y alta precisión.
Supongamos que\(C_i(\bs{X})\) es un\(1 - \alpha_i\) nivel de confianza establecido\(\theta\) para\(i \in \{1, 2, \ldots, k\}\). Si\(\alpha = \alpha_1 + \alpha_2 + \cdots + \alpha_k \lt 1\) entonces\(C_1(\bs{X}) \cap C_2(\bs{X}) \cap \cdots \cap C_k(\bs{X})\) es un\(1 - \alpha \) nivel conservador de confianza establecido para\(\theta\).
Prueba
Esto se desprende de la desigualdad de Bonferroni.
Parámetros de valor real
En muchos casos, nos interesa estimar un parámetro de valor real\(\lambda = \lambda(\theta)\) tomando valores en un espacio de parámetros de intervalo\((a, b)\), donde\(a, \, b \in \R\) con\(a \lt b\). Por supuesto, es posible que\(a = -\infty\) o\(b = \infty\). En este contexto nuestro conjunto de confianza frecuentemente tiene la forma\[ C(\bs{X}) = \left\{\theta \in \Theta: L(\bs{X}) \lt \lambda(\theta) \lt U(\bs{X})\right\} \] donde\(L(\bs{X})\) y\(U(\bs{X})\) son estadísticas de valor real. En este caso\((L(\bs{X}), U(\bs{X}))\) se denomina intervalo de confianza para\(\lambda\). Si\(L(\bs{X})\) y ambos\(U(\bs{X})\) son aleatorios, entonces a menudo se dice que el intervalo de confianza es de dos lados. En el caso especial que\(U(\bs{X}) = b\),\(L(\bs{X})\) se llama un límite inferior de confianza para\(\lambda\). En el caso especial que\(L(\bs{X}) = a\),\(U(\bs{X})\) se denomina límite superior de confianza para\(\lambda\).
Supongamos que\(L(\bs{X})\) es un límite inferior de confianza de\(1 - \alpha\) nivel para\(\lambda\) y que\(U(\bs{X})\) es un límite superior de confianza de\(1 - \beta\) nivel para\(\lambda\). Si\(\alpha + \beta \lt 1\) entonces\((L(\bs{X}), U(\bs{X}))\) es un intervalo de confianza de\(1 - (\alpha + \beta)\) nivel conservador para\(\lambda\).
Prueba
Esto se deduce inmediatamente de (2).
Variables de pivote
Se podría pensar que debería ser muy difícil construir conjuntos de confianza para un parámetro\(\theta\). Sin embargo, en muchos casos especiales importantes, los conjuntos de confianza se pueden construir fácilmente a partir de ciertas variables aleatorias conocidas como variables pivotantes.
Supongamos que\(V\) es una función desde\(S \times \Theta\) dentro de un conjunto\(T\). La variable aleatoria\(V(\bs{X}, \theta)\) es una variable pivote para\(\theta\) si su distribución no depende de\(\theta\). Específicamente,\(\P[V(\bs{X}, \theta) \in B]\) es constante en\(\theta \in \Theta\) para cada uno\(B \subseteq T\).
La idea básica es que tratamos de combinar\(\bs{X}\) y\(\theta\) algebraicamente de tal manera que factorizamos la dependencia\(\theta\) en la distribución de la variable aleatoria resultante\(V(\bs{X}, \theta)\). Si conocemos la distribución de la variable pivote, entonces para un dado\(\alpha\), podemos tratar de encontrar\(B \subseteq T\) (que no depende de\(\theta\)) tal que\( \P_\theta\left[V(\bs{X}, \theta) \in B\right] = 1 - \alpha \). Se deduce entonces que un conjunto de\(1 - \alpha\) confianza para el parámetro viene dado por\( C(\bs{X}) = \{ \theta \in \Theta: V(\bs{X}, \theta) \in B \} \).
Supongamos ahora que nuestra variable pivote\(V(\bs{X}, \theta)\) es de valor real, que por simplicidad, asumiremos que tiene una distribución continua. Para\(p \in (0, 1)\), vamos a\(v(p)\) denotar el cuantil de orden\(p\) para la variable pivote\(V(\bs{X}, \theta)\). Por el mismo significado de variable pivote,\(v(p)\) no depende de\(\theta\).
Para cualquier\(p \in (0, 1)\), un\(1 - \alpha\) nivel de confianza establecido para\(\theta\) es\[ \left\{\theta \in \Theta: v(\alpha - p \alpha) \lt V(\bs{X}, \theta) \lt v(1 - p \alpha)\right\} \]
Prueba
Por definición, la probabilidad del evento es\((1 - p \alpha) - (\alpha - p \alpha) = 1 - \alpha\).
La confianza establecida arriba corresponde a\((1 - p) \alpha\) en la cola izquierda y\(p \alpha\) en la cola derecha, en términos de la distribución de la variable pivote\(V(\bs{X}, \lambda)\). El caso especial\(p = \frac{1}{2}\) es el caso de cola igual, el caso más común.
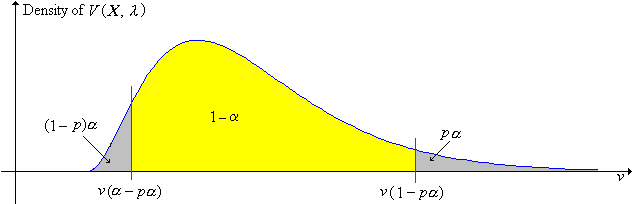
El conjunto de confianza (5) está disminuyendo\(\alpha\) y, por lo tanto, aumenta en\(1 - \alpha\) (en el sentido de la relación de subconjunto) para fijo\(p\).
Para el conjunto de confianza (5), naturalmente nos gustaría elegir\(p\) que minimice el tamaño del conjunto en algún sentido. Sin embargo, esto suele ser un problema difícil. El intervalo de cola igual, correspondiente a\(p = \frac{1}{2}\), es el caso más utilizado, y a veces (pero no siempre) es una opción óptima. Las variables de pivote están lejos de ser únicas; el desafío es encontrar una variable pivote cuya distribución sea conocida y que dé límites estrechos en el parámetro (alta precisión).
Supongamos que\(V(\bs{X}, \theta)\) es una variable pivote para\(\theta\). Si\(g\) es una función definida en el rango de\(V\) y no\(g\) implica parámetros desconocidos, entonces también\(U = g[V(\bs{X}, \theta)]\) es una variable pivote para\(\theta\).
Ejemplos y Casos Especiales
Familias a escala de ubicación
En el caso de familias de distribuciones a escala de ubicación, podemos encontrar fácilmente variables pivotes. Supongamos que\(Z\) es una variable aleatoria de valor real con una distribución continua que tiene función de densidad de probabilidad\(g\), y no hay parámetros desconocidos. Vamos\(X = \mu + \sigma Z\) donde\(\mu \in \R\) y\(\sigma \in (0, \infty)\) son parámetros. Recordemos que la función de densidad de probabilidad de\(X\) viene dada por\[ f_{\mu, \sigma}(x) = \frac{1}{\sigma} g\left( \frac{x - \mu}{\sigma} \right), \quad x \in \R\] y la familia de distribuciones correspondiente se denomina familia de escala de ubicación asociada a la distribución de\(Z\);\(\mu\) es el parámetro de ubicación y\(\sigma\) es el parámetro de escala. Generalmente, estamos asumiendo que estos parámetros son desconocidos.
Ahora supongamos que\(\bs{X} = (X_1, X_2, \ldots, X_n)\) es una muestra aleatoria de tamaño\(n\) a partir de la distribución de\(X\); este es nuestro vector de resultado observable. Para cada uno\(i\), vamos\[ Z_i = \frac{X_i - \mu}{\sigma} \]
El vector aleatorio\(\bs{Z} = (Z_1, Z_2, \ldots, Z_n)\) es una muestra aleatoria de tamaño\(n\) a partir de la distribución de\(Z\).
En particular, tenga en cuenta que\(\bs{Z}\) es una variable pivote para\((\mu, \sigma)\), ya que\(\bs{Z}\) es una función de\(\bs{X}\)\(\mu\)\(\sigma\), y, pero la distribución de\(\bs{Z}\) no depende de\(\mu\) o\(\sigma\). Por lo tanto, cualquier función de también\(\bs{Z}\) será una variable pivote para\((\mu, \sigma)\), (si la función no involucra los parámetros). Por supuesto, algunas de estas variables pivotes serán mucho más útiles que otras en la estimación\(\mu\) y\(\sigma\). En los siguientes ejercicios, exploraremos dos variables pivotes comunes e importantes.
Dejar\(M(\bs{X})\) y\(M(\bs{Z})\) denotar las medias de muestra de\(\bs{X}\) y\(\bs{Z}\), respectivamente. Entonces\(M(\bs{Z})\) es una variable de pivote para\((\mu, \sigma)\) desde\[ M(\bs{Z}) = \frac{M(\bs{X}) - \mu}{\sigma} \]
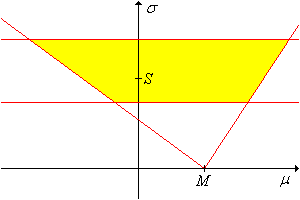
Dejar\(m\) denotar la función cuantil de la variable pivote\(M(\bs{Z})\). Para cualquiera\(p \in (0, 1)\), un conjunto de\(1 - \alpha\) confianza para\((\mu, \sigma)\)\[ Z_{\alpha, p}(\bs{X}) = \{(\mu, \sigma): M(\bs{X}) - m(1 - p \alpha) \sigma \lt \mu \lt M(\bs{X}) - m(\alpha - p \alpha) \sigma \} \]
El conjunto de confianza construido arriba es un cono
en el espacio de\((\mu, \sigma)\) parámetros, con vértice en\( (M(\bs{X}), 0) \) y líneas límite de pendientes\(-1 / m(1 - p \alpha)\) y\(-1 / m(\alpha - p \alpha)\), como se muestra en la gráfica de abajo. (Tenga en cuenta, sin embargo, que ambas pendientes pueden ser negativas o ambas positivas).
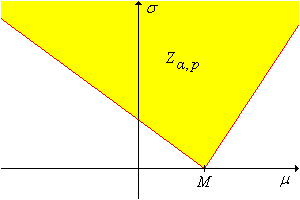
El hecho de que el conjunto de confianza sea ilimitado claramente no es bueno, pero quizás no sea sorprendente; estamos estimando dos parámetros reales con una sola variable pivote de valor real. Sin embargo, si\(\sigma\) se conoce, el conjunto de confianza define un intervalo de confianza para\(\mu\). Geométricamente, el intervalo de confianza simplemente corresponde a la sección transversal horizontal en\(\sigma\).
\(1 - \alpha\)conjuntos de confianza para\((\mu, \sigma)\) son
- \(Z_{\alpha, 1}(\bs{X}) = \{(\mu, \sigma): M(\bs{X}) - m(1 - \alpha) \sigma \lt \mu \lt \infty\}\)
- \(Z_{\alpha, 0}(\bs{X}) = \{(\mu, \sigma): - \infty \lt \mu \lt M(\bs{X}) - m(\alpha) \sigma\}\)
Prueba
En el conjunto de confianza construido arriba, let\(p \uparrow 1\) y\(p \downarrow 0\), respectivamente.
Si\(\sigma\) se conoce, entonces (a) da un límite inferior de\(1 - \alpha\) confianza para\(\mu\) y (b) da un límite superior de\(1 - \alpha\) confianza para\(\mu\).
Dejar\(S(\bs{X})\) y\(S(\bs{Z})\) denotar las desviaciones estándar de la muestra de\(\bs{X}\) y\(\bs{Z}\), respectivamente. Luego\(S(\bs{Z})\) es una variable de pivote para\((\mu, \sigma)\) y una variable de pivote para\(\sigma\) desde\[ S(\bs{Z}) = \frac{S(\bs{X})}{\sigma} \]
Dejar\(s\) denotar la función cuantil de\(S(\bs{Z})\). Para cualquier\(\alpha \in (0, 1)\) y\(p \in (0, 1)\), un conjunto de\(1 - \alpha\) confianza para\((\mu, \sigma)\) es\[ V_{\alpha, p}(\bs{X}) = \left\{(\mu, \sigma): \frac{S(\bs{X})}{s(1 - p \alpha)} \lt \sigma \lt \frac{S(\bs{X})}{s(\alpha - p \alpha)} \right\} \]
Tenga en cuenta que el conjunto de confianza no da información sobre\(\mu\) ya que la variable aleatoria anterior es una variable pivote por\(\sigma\) sí sola. El conjunto de confianza también se puede ver como un intervalo de confianza limitado para\(\sigma\).
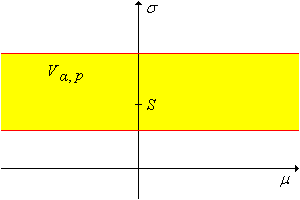
\(1 - \alpha\)conjuntos de confianza para\((\mu, \sigma)\) son
- \(V_{\alpha, 1}(\bs{X}) = \left \{ (\mu, \sigma): S(\bs{X}) / s(1 - \alpha) \lt \sigma \lt \infty \right \}\)
- \(V_{\alpha, 0}(\bs{X}) = \left \{ (\mu, \sigma): 0 \lt \sigma \lt S(\bs{X}) / s(\alpha) \right \}\)
Prueba
En el conjunto de confianza construido arriba, let\(p \uparrow 1\) y\(p \downarrow 0\), respectivamente.
El conjunto en la parte (a) da un límite inferior de\(1 - \alpha\) confianza para\(\sigma\) y el conjunto en la parte (b) da un límite superior de\(1 - \alpha\) confianza para\(\sigma\).
Podemos intersectar los conjuntos de confianza correspondientes a las dos variables pivotes para producir conjuntos de confianza conservativos y delimitados.
Si\(\alpha, \; \beta, \; p, \; q \in (0, 1)\) con\(\alpha + \beta \lt 1\) entonces\(Z_{\alpha, p} \cap V_{\beta, q}\) es una\(1 - (\alpha + \beta)\) confianza conservadora fijada para\((\mu, \sigma)\).
Prueba
La familia de escala de ubicación más importante es la familia de distribuciones normales. El problema de estimación en el modelo normal se considera en la siguiente sección. En el resto de esta sección, exploraremos otra familia de escala importante.
La distribución exponencial
Recordemos que la distribución exponencial con parámetro de escala\(\sigma \in (0, \infty)\) tiene función de densidad de probabilidad\(f(x) = \frac{1}{\sigma} e^{-x / \sigma}, \; x \in [0, \infty)\). Es la familia de escalas asociada a la distribución exponencial estándar, la cual tiene función de densidad de probabilidad\(g(x) = e^{-x}, \; x \in [0, \infty)\). La distribución exponencial es ampliamente utilizada para modelar tiempos aleatorios (como tiempos de vida y tiempos de llegada
), particularmente en el contexto del modelo de Poisson. Ahora supongamos que\(\bs{X} = (X_1, X_2, \ldots, X_n)\) es una muestra aleatoria de tamaño\(n\) a partir de la distribución exponencial con parámetro de escala desconocido\(\sigma\). Let\[ Y = \sum_{i=1}^n X_i \]
La variable aleatoria\(\frac{2}{\sigma} Y\) tiene la distribución chi-cuadrada con\(2 n\) grados de libertad, y por lo tanto es una variable de pivote para\(\sigma\).
Tenga en cuenta que esta variable de pivote es un múltiplo de la variable\( M \) construida anteriormente para familias generales de escala de ubicación (con\(\mu = 0\)). Para\(p \in (0, 1)\) y\(k \in (0, \infty)\), vamos a\(\chi_k^2(p)\) denotar el cuantil de orden\(p\) para la distribución chi-cuadrada con\(k\) grados de libertad. Para valores seleccionados de\(k\) y\(p\), se\(\chi_k^2(p)\) puede obtener de la calculadora de distribución especial o de la mayoría de los paquetes de software estadístico.
Recordemos que
- \(\chi_k^2(p) \to 0\)como\(p \downarrow 0\)
- \(\chi_k^2(p) \to \infty\)como\(p \uparrow 1\)
Para cualquiera\(\alpha \in (0, 1)\) y cada\(p \in (0, 1)\) uno, un intervalo de\(1 - \alpha\) confianza para\(\sigma\)\[ \left( \frac{2\,Y}{\chi_{2n}^2(1 - p \alpha)}, \frac{2\,Y}{\chi_{2n}^2(\alpha - p \alpha)} \right) \]
Tenga en cuenta que
- \(2 Y \big/ \chi_{2n}^2(1 - \alpha)\)es un límite inferior de\(1 - \alpha\) confianza para\(\sigma\).
- \(2 Y \big/ \chi_{2n}^2(\alpha)\)es un límite inferior de\(1 - \alpha\) confianza para\(\sigma\).
De los intervalos de confianza de dos lados construidos anteriormente, naturalmente preferiríamos el de menor longitud, ya que este intervalo da la mayor información sobre el parámetro\(\sigma\). Sin embargo, minimizar la longitud en función de\(p\) es computacionalmente difícil. El intervalo de confianza bilateral que se usa normalmente es el intervalo de cola igual que se obtiene al dejar\(p = \frac{1}{2}\):\[ \left( \frac{2\,Y}{\chi_{2n}^2(1 - \alpha/2)}, \frac{2\,Y}{\chi_{2n}^2(\alpha/2)} \right) \]
La vida útil de un determinado tipo de componente (en horas) tiene una distribución exponencial con parámetro de escala desconocido\(\sigma\). Diez dispositivos son operados hasta el fallo; los tiempos de vida son 592, 861, 1470, 2412, 335, 3485, 736, 758, 530, 1961.
- Construir el intervalo de confianza bidimensional del 95% para\(\sigma\).
- Construir el límite inferior de confianza del 95% para\(\sigma\).
- Construir el límite superior de confianza del 95% para\(\sigma\).
Responder
- \((769.1, 2740.1)\)
- 836.7
- 2421.9