
13.2: La prueba t de una muestra
- Page ID
- 151777

Después de pensarlo un poco, decidí que podría no ser seguro asumir que las calificaciones de los estudiantes de psicología necesariamente tienen la misma desviación estándar que los demás estudiantes en la clase del Dr. Zeppo. Después de todo, si estoy entreteniendo la hipótesis de que no tienen la misma media, entonces ¿por qué debería creer que absolutamente tienen la misma desviación estándar? Ante esto, realmente debería dejar de asumir que conozco el verdadero valor de σ. Esto viola los supuestos de mi prueba z, así que en un sentido vuelvo al punto de partida. Sin embargo, no es como si estuviera completamente desposeído de opciones. Después de todo, todavía tengo mis datos brutos, y esos datos brutos me dan una estimación de la desviación estándar de la población:
sd( grades )## [1] 9.520615Es decir, si bien no puedo decir que sé que σ=9.5, puedo decir que\(\hat{\sigma}\) =9.52.
Bien, genial. Lo obvio que se podría pensar es ejecutar una prueba z, pero usando la desviación estándar estimada de 9.52 en lugar de confiar en mi suposición de que la verdadera desviación estándar es 9.5. Entonces, podríamos simplemente escribir este nuevo número en R y salir saldría la respuesta. Y probablemente no te sorprendería escuchar que esto aún nos daría un resultado significativo. Este enfoque es cercano, pero no es del todo correcto. Debido a que ahora nos basamos en una estimación de la desviación estándar de la población, necesitamos hacer algún ajuste por el hecho de que tenemos cierta incertidumbre sobre cuál es realmente la verdadera desviación estándar de la población. A lo mejor nuestros datos son solo una casualidad... tal vez la verdadera desviación estándar poblacional sea 11, por ejemplo. Pero si eso fuera realmente cierto, y ejecutamos la prueba z asumiendo σ=11, entonces el resultado terminaría siendo no significativo. Eso es un problema, y es uno que vamos a tener que abordar.
Presentamos la prueba t
Esta ambigüedad es molesta, y fue resuelta en 1908 por un tipo llamado William Sealy Gosset (Estudiante 1908), quien trabajaba como químico para la cervecería Guinness en ese momento (ver Box 1987). Debido a que Guinness tomó una visión tenue de sus empleados publicando análisis estadísticos (al parecer sentían que era un secreto comercial), publicó la obra bajo el seudónimo de “A Student”, y hasta el día de hoy, el nombre completo de la prueba t es en realidad la prueba t de Student. Lo clave que Gosset descubrió es cómo debemos acomodar el hecho de que no estamos completamente seguros de cuál es la verdadera desviación estándar. 187 La respuesta es que cambia sutilmente la distribución muestral. En la prueba t, nuestro estadístico de prueba (ahora llamado estadístico t) se calcula exactamente de la misma manera que mencioné anteriormente. Si nuestra hipótesis nula es que la verdadera media es μ, pero nuestra muestra tiene la media ¯X y nuestra estimación de la desviación estándar de la población es\(\hat{\sigma}\), entonces nuestro estadístico t es:
\(\ t = {{\bar{X}-\mu} \over \hat{\sigma}/ \sqrt{N} }\)
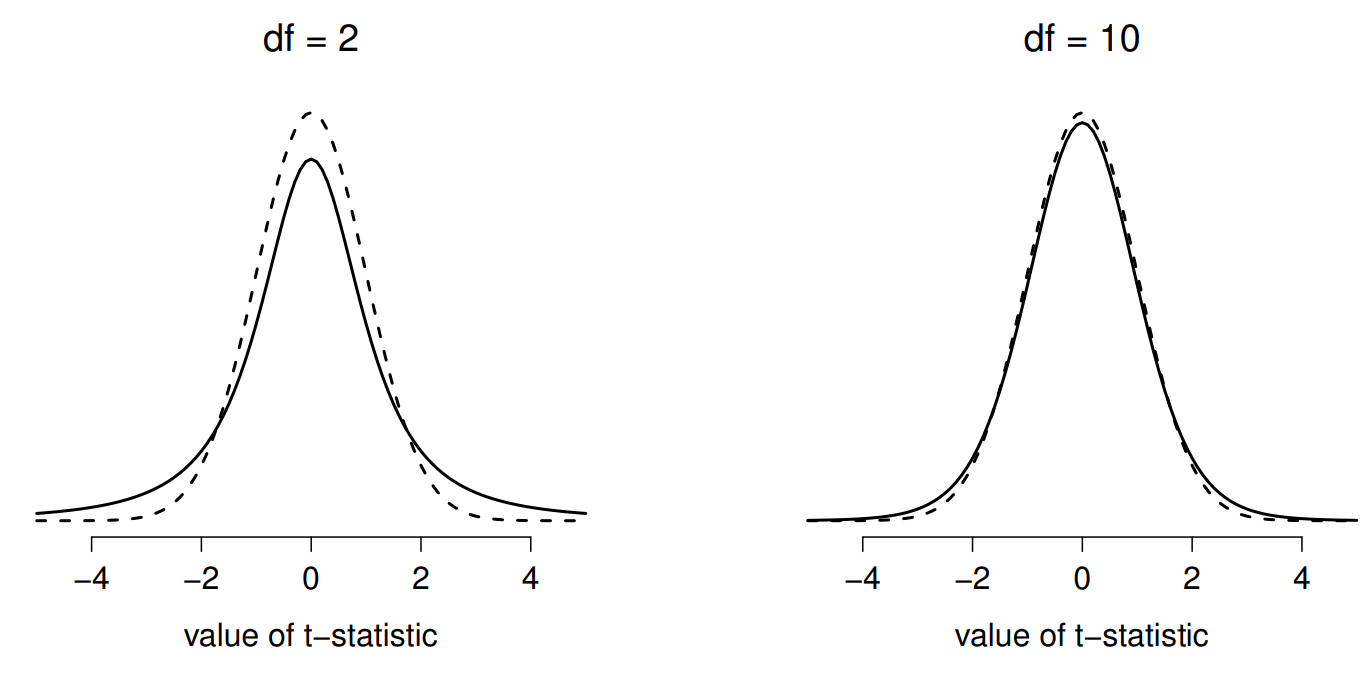
Lo único que ha cambiado en la ecuación es que en lugar de usar el valor verdadero conocido σ, usamos la estimación\(\hat{\sigma}\) Y si esta estimación se ha construido a partir de N observaciones, entonces la distribución de muestreo se convierte en una distribución t con N−1 grados de libertad (df). La distribución t es muy similar a la distribución normal, pero tiene colas “más pesadas”, como se discutió anteriormente en la Sección 9.6 y se ilustra en la Figura 13.5. Observe, sin embargo, que a medida que df se hace más grande, la distribución t comienza a verse idéntica a la distribución normal estándar. Esto es como debería ser: si tienes un tamaño de muestra de N=70,000,000 entonces tu “estimación” de la desviación estándar sería prácticamente perfecta, ¿verdad? Entonces, debes esperar que para N grande, la prueba t se comportaría exactamente de la misma manera que una prueba z. ¡Y eso es exactamente lo que pasa!
Haciendo la prueba en R
Como cabría esperar, la mecánica de la prueba t es casi idéntica a la mecánica de la prueba z. Entonces no tiene mucho sentido pasar por el tedioso ejercicio de mostrarte cómo hacer los cálculos usando comandos de bajo nivel: es prácticamente idéntico a los cálculos que hicimos antes, excepto que usamos la desviación estándar estimada (es decir, algo así como se.est <- sd (grades)), y luego probamos nuestra hipótesis usando la distribución t en lugar de la distribución normal (es decir, usamos pt () en lugar de pnorm (). Y así, en lugar de revisar los cálculos con tedioso detalle por segunda vez, saltaré directo a mostrarte cómo se hacen realmente las pruebas t en la práctica.
La situación con las pruebas t es muy similar a la que encontramos con las pruebas de chi-cuadrado en el Capítulo 12. R viene con una función llamada t.test () que es muy flexible (puede ejecutar muchos tipos diferentes de pruebas t) y es algo concisa (la salida está bastante comprimida). Más adelante en el capítulo te voy a mostrar cómo usar la función t.test () (Sección 13.7), pero para empezar voy a confiar en algunas funciones más simples en el paquete lsr. Al igual que la última vez, lo que he hecho es escribir algunas funciones más simples, cada una de las cuales solo hace una cosa. Entonces, si quieres ejecutar una prueba t de una muestra, ¡usa la función OneSampleTtest ()! Es bastante sencillo de usar: todo lo que necesitas hacer es especificar x, la variable que contiene los datos, y mu, la verdadera media de la población según la hipótesis nula. Todo lo que necesitas para escribir es esto:
library(lsr)
oneSampleTTest( x=grades, mu=67.5 )##
## One sample t-test
##
## Data variable: grades
##
## Descriptive statistics:
## grades
## mean 72.300
## std dev. 9.521
##
## Hypotheses:
## null: population mean equals 67.5
## alternative: population mean not equal to 67.5
##
## Test results:
## t-statistic: 2.255
## degrees of freedom: 19
## p-value: 0.036
##
## Other information:
## two-sided 95% confidence interval: [67.844, 76.756]
## estimated effect size (Cohen's d): 0.504Bastante fácil. Ahora vamos a pasar por la salida. Al igual que vimos en el último capítulo, he escrito las funciones para que la salida sea bastante detallada. Trata de describir con mucho detalle lo que realmente se ha hecho:
One sample t-test
Data variable: grades
Descriptive statistics:
grades
mean 72.300
std dev. 9.521
Hypotheses:
null: population mean equals 67.5
alternative: population mean not equal to 67.5
Test results:
t-statistic: 2.255
degrees of freedom: 19
p-value: 0.036
Other information:
two-sided 95% confidence interval: [67.844, 76.756]
estimated effect size (Cohen's d): 0.504 Al leer este resultado de arriba a abajo, puede ver que está tratando de guiarlo a través del proceso de análisis de datos. Las dos primeras líneas te indican qué tipo de prueba se realizó y qué datos se utilizaron. Luego te da alguna información básica sobre la muestra: específicamente, la media muestral y la desviación estándar de los datos. Luego se mueve hacia la parte estadística inferencial. Comienza diciéndote cuáles fueron las hipótesis nulas y alternativas, y luego reporta los resultados de la prueba: el estadístico t, los grados de libertad y el valor p. Por último, informa otras dos cosas que podrían interesarle: el intervalo de confianza para la media y una medida del tamaño del efecto (hablaremos más sobre los tamaños de los efectos más adelante).
Entonces eso parece bastante sencillo. Ahora, ¿qué hacemos con esta salida? Bueno, ya que estamos fingiendo que realmente nos importa mi ejemplo de juguete, estamos muy felices de descubrir que el resultado es estadísticamente significativo (es decir, valor de p por debajo de 0.05). Podríamos reportar el resultado diciendo algo como esto:
Con una nota media de 72.3, los estudiantes de psicología obtuvieron una puntuación ligeramente superior a la nota promedio de 67.5 (t (19) =2.25, p<.05); el intervalo de confianza del 95% es [67.8, 76.8].
donde t (19) es la notación abreviada para un estadístico t que tiene 19 grados de libertad. Dicho esto, a menudo ocurre que la gente no informa el intervalo de confianza, o lo hace usando una forma mucho más comprimida que la que he hecho aquí. Por ejemplo, no es raro ver el intervalo de confianza incluido como parte del bloque stat, así:
t (19) =2.25, p<.05, CI95= [67.8,76.8]
Con tanta jerga abarrotada en media línea, sabes que debe ser realmente inteligente. 188
Supuestos de la prueba t de una muestra
Bien, entonces, ¿qué suposiciones hace la prueba t de una muestra? Bueno, ya que la prueba t es básicamente una prueba z con la suposición de desviación estándar conocida eliminada, no debería sorprenderse al ver que hace las mismas suposiciones que la prueba z, menos la relativa a la desviación estándar conocida. Eso es
- Normalidad. Seguimos asumiendo que la distribución poblacional es normal^ [Un comentario técnico... de la misma manera que podemos debilitar los supuestos de la prueba z para que solo estemos hablando de la distribución muestral, podamos debilitar los supuestos de la prueba t para que no tengamos que asumir normalidad de la población. Sin embargo, para la prueba t, es más complicado hacer esto. Como antes, podemos sustituir el supuesto de normalidad poblacional por un supuesto de que la distribución muestral de ¯X es normal. Sin embargo, recuerde que también estamos confiando en una estimación muestral de la desviación estándar; por lo que también requerimos que la distribución muestral de ^σ sea chi-cuadrada. Eso hace que las cosas sean más feas, y esta versión rara vez se usa en la práctica: afortunadamente, si la población es normal, entonces se cumplen ambos supuestos., y como se señaló anteriormente, existen herramientas estándar que puedes usar para verificar si se cumple esta suposición (Sección 13.9), y otras pruebas que puedes hacer en ella' s lugar si se viola esta suposición (Sección 13.10).
- Independencia. Una vez más, tenemos que asumir que las observaciones en nuestra muestra se generan independientemente unas de otras. Consulte la discusión anterior sobre la prueba z para obtener detalles específicos (Sección 13.1.4).
En general, estos dos supuestos no son terriblemente irrazonables y, como consecuencia, la prueba t de una muestra es ampliamente utilizada en la práctica como una forma de comparar una media muestral con una media de población hipotética.