Comportamiento de la Media Muestra (barra x)
Objetivos de aprendizaje
LO 6.22: Aplicar la distribución muestral de la media muestral resumida por el Teorema del Límite Central (cuando corresponda). En particular, poder identificar muestras inusuales de una población determinada.
Hasta el momento, hemos discutido el comportamiento del estadístico p-hat, la proporción muestral, relativa al parámetro p, la proporción poblacional (cuando la variable de interés es categórica).
Ahora estamos avanzando para explorar el comportamiento del estadístico x-bar, la media muestral, relativa al parámetro μ (mu), la media poblacional (cuando la variable de interés es cuantitativa).
Empecemos con un ejemplo.
EJEMPLO 9: Comportamiento de las medias
Se registran los pesos al nacer para todos los bebés de un pueblo. El peso medio al nacer es de 3,500 gramos, µ = mu = 3,500 g. Si recolectamos muchas muestras aleatorias de 9 bebés a la vez, ¿cómo crees que se comportarán los medios de muestra?
Aquí nuevamente, estamos trabajando con una variable aleatoria, ya que las muestras aleatorias tendrán medias que varían de manera impredecible en el corto plazo pero que exhiben patrones a largo plazo.
Con base en nuestra intuición y en lo que hemos aprendido sobre el comportamiento de las proporciones muestrales, podríamos esperar lo siguiente sobre la distribución de las medias muestrales:
Centro: Algunos medios de muestra estarán en el lado bajo —digamos 3,000 gramos más o menos— mientras que otros estarán en el lado alto, digamos 4,000 gramos más o menos. En muestreos repetidos, podríamos esperar que las muestras aleatorias promedien a la media poblacional subyacente de 3,500 g, es decir, la media de las medias de la muestra será µ (mu), así como la media de proporciones muestrales fue p.
Difusión: Para muestras grandes, podríamos esperar que las medias de la muestra no se alejen demasiado de la media poblacional de 3,500. Las medias muestrales inferiores a 3,000 o superiores a 4,000 podrían ser sorprendentes. Para muestras más pequeñas, estaríamos menos sorprendidos por medios de muestra que variaban bastante de 3,500. En otras palabras, podríamos esperar una mayor variabilidad en las medias muestrales para muestras más pequeñas. Por lo que el tamaño de la muestra volverá a jugar un papel en la difusión de la distribución de las medidas muestrales, como observamos para las proporciones de la muestra.
Forma: Las medias de muestra más cercanas a 3,500 serán las más comunes, con medias de muestra lejos de 3,500 en cualquier dirección progresivamente menos probables. Es decir, la forma de la distribución de los medios de muestra debe abultarse en el medio y estrechar en los extremos con una forma que sea algo normal. Esto, de nuevo, es lo que vimos cuando miramos las proporciones de la muestra.
Comentario:
- La distribución de los valores de la media muestral (x-bar) en muestras repetidas se denomina distribución muestral de x-bar.
Veamos una simulación:
Los resultados que encontramos en nuestras simulaciones no son sorprendentes. La teoría avanzada de probabilidad confirma que al afirmar lo siguiente:
La distribución muestral de la media muestral
Si se toman muestras aleatorias repetidas de un tamaño dado n de una población de valores para una variable cuantitativa, donde la media poblacional es μ (mu) y la desviación estándar de la población es σ (sigma) entonces la media de todas las medias de la muestra (barras x) es la media poblacional μ (mu).
En cuanto a la difusión de todas las medias muestrales, la teoría dicta el comportamiento de manera mucho más precisa que decir que hay menos dispersión para muestras más grandes. De hecho, la desviación estándar de todas las medias muestrales está directamente relacionada con el tamaño de la muestra, n como se indica a continuación.
La desviación estándar de todas las medias de la muestra (\(\bar{x}\)) es exactamente\(\dfrac{\sigma}{\sqrt{n}}\)
Dado que la raíz cuadrada del tamaño de muestra n aparece en el denominador, la desviación estándar disminuye a medida que aumenta el tamaño de la muestra.
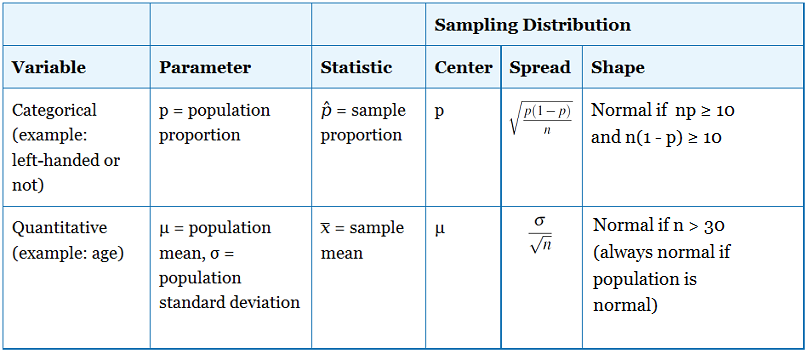
Comparemos y contrastemos lo que ahora sabemos sobre las distribuciones de muestreo para medias y proporciones muestrales.
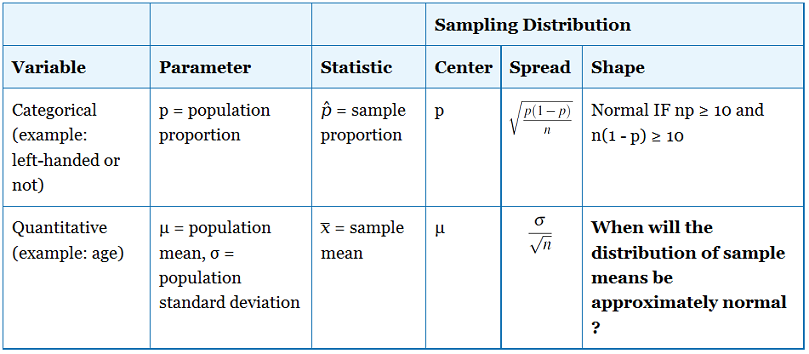
Ahora investigaremos la forma de la distribución muestral de las medias muestrales. Cuando discutimos la distribución muestral de las proporciones muestrales, dijimos que esta distribución es aproximadamente normal si np ≥ 10 y n (1 — p) ≥ 10. En otras palabras, teníamos una guía basada en el tamaño de la muestra para determinar las condiciones bajo las cuales podríamos usar cálculos de probabilidad normal para las proporciones de la muestra.
¿Cuándo será aproximadamente normal la distribución de las medias de la muestra? ¿Depende esto del tamaño de la muestra?
Parece razonable que una población con una distribución normal tenga medias muestrales que normalmente se distribuyen incluso para muestras muy pequeñas. Esto lo vimos ilustrado en la simulación anterior con muestras de tamaño 10.
¿Qué sucede si la distribución de la variable en la población está fuertemente sesgada? ¿Los medios de muestra también tienen una distribución sesgada? Si tomamos muestras realmente grandes, ¿los medios de la muestra se distribuirán más normalmente?
En la próxima simulación, investigaremos estas preguntas.
En resumen, la distribución de las medias de la muestra será aproximadamente normal siempre y cuando el tamaño de la muestra sea lo suficientemente grande. Este descubrimiento es probablemente el resultado más importante que se presenta en los cursos introductorios de estadística. Se afirma formalmente como el Teorema del Límite Central.
Dependeremos una y otra vez del Teorema del Límite Central para hacer cálculos de probabilidad normal cuando se utilicen medias de muestra para sacar conclusiones sobre una media poblacional. Ahora sabemos que podemos hacer esto aunque la distribución de la población no sea normal.
¿Qué tamaño de muestra necesitamos para asumir que normalmente se distribuirán los medios de muestra? Bueno, realmente depende de la distribución poblacional, como vimos en la simulación. La regla general es que las muestras de tamaño 30 o mayor tendrán una distribución bastante normal independientemente de la forma de la distribución de la variable en la población.
Comentario:
- Para las variables categóricas, nuestra afirmación de que las proporciones muestrales son aproximadamente normales para n suficientemente grandes es en realidad un caso especial del Teorema del Límite Central. En este caso, pensamos en los datos como 0 y 1 y el “promedio” de estos 0 y 1 es igual a la proporción que hemos discutido.
Antes de trabajar algunos ejemplos, comparemos y contrastemos lo que ahora sabemos sobre las distribuciones de muestreo para medias y proporciones muestrales.
EJEMPLO 10: Uso de la distribución de muestreo de barra x
El tamaño del hogar en Estados Unidos tiene una media de 2.6 personas y una desviación estándar de 1.4 personas. Debe quedar claro que esta distribución está bien sesgada ya que el valor más pequeño posible es un hogar de 1 persona pero los hogares más grandes pueden ser realmente muy grandes.
a) ¿Cuál es la probabilidad de que un hogar elegido al azar tenga más de 3 personas?
Aquí no se debería utilizar una aproximación normal, ya que la distribución de los tamaños de los hogares estaría considerablemente sesgada hacia la derecha. No tenemos suficiente información para resolver este problema.
b) ¿Cuál es la probabilidad de que el tamaño medio de una muestra aleatoria de 10 hogares sea superior a 3?
Según los estándares de cualquiera, 10 es un tamaño de muestra pequeño. El Teorema del Límite Central no garantiza que la media de la muestra proveniente de una población sesgada sea aproximadamente normal a menos que el tamaño de la muestra sea grande.
c) ¿Cuál es la probabilidad de que el tamaño medio de una muestra aleatoria de 100 hogares sea superior a 3?
Ahora podemos invocar el Teorema del Límite Central: a pesar de que la distribución del tamaño del hogar X es sesgada, la distribución del tamaño medio del hogar de la muestra (barra x) es aproximadamente normal para un tamaño de muestra grande como 100. Su media es la misma que la media poblacional, 2.6, y su desviación estándar es la desviación estándar poblacional dividida por la raíz cuadrada del tamaño muestral:
\(\dfrac{\sigma}{\sqrt{n}}=\dfrac{1.4}{\sqrt{100}}=0.14\)
Para encontrar
\(P(\bar{x}>3)\)
estandarizamos 3 a en una puntuación z restando la media y dividiendo el resultado por la desviación estándar (de la media de la muestra). Entonces podemos encontrar la probabilidad usando la calculadora normal estándar o tabla.
\(P(\bar{x}>3)=P\left(Z>\dfrac{3-2.6}{\dfrac{1.4}{\sqrt{100}}}\right)=P(Z>2.86)=0.0021\)
Los hogares de más de 3 personas son, por supuesto, bastante comunes, pero sería extremadamente inusual que el tamaño medio de una muestra de 100 hogares fuera más de 3.
El propósito de la siguiente actividad es dar una práctica guiada en la búsqueda de la distribución muestral de la media muestral (barra x), y utilizarla para conocer la probabilidad de obtener ciertos valores de la barra x.
