
11.3: Estadísticas de prueba y distribuciones de muestreo
- Page ID
- 151794

En este punto tenemos que empezar a hablar de detalles sobre cómo se construye una prueba de hipótesis. Para ello, volvamos al ejemplo del ESP. Ignoremos los datos reales que obtuvimos, por el momento, y pensemos en la estructura del experimento. Independientemente de cuáles sean los números reales, la forma de los datos es que X de N personas identificaron correctamente el color de la tarjeta oculta. Además, supongamos por el momento que la hipótesis nula es realmente cierta: ESP no existe, y la verdadera probabilidad de que alguien elija el color correcto es exactamente θ=0.5. ¿Cómo esperaríamos que fueran los datos? Bueno, obviamente, esperaríamos que la proporción de personas que hacen la respuesta correcta esté bastante cerca del 50%. O, para expresar esto en términos más matemáticos, diríamos que X/N es aproximadamente 0.5. Por supuesto, no esperaríamos que esta fracción fuera exactamente 0.5: si, por ejemplo, probáramos a N=100 personas, y X=53 de ellas consiguiera la pregunta correcta, probablemente nos veríamos obligados a admitir que los datos son bastante consistentes con la hipótesis nula. Por otro lado, si X=99 de nuestros participantes tiene la pregunta correcta, entonces nos sentiríamos bastante seguros de que la hipótesis nula es incorrecta. Del mismo modo, si solo X=3 personas consiguieran la respuesta correcta, estaríamos igualmente seguros de que el nulo estaba equivocado. Seamos un poco más técnicos al respecto: tenemos una cantidad X que podemos calcular mirando nuestros datos; después de mirar el valor de X, tomamos una decisión sobre si creer que la hipótesis nula es correcta, o rechazar la hipótesis nula a favor de la alternativa. El nombre de esta cosa que calculamos para guiar nuestras elecciones es una estadística de prueba.
Habiendo elegido un estadístico de prueba, el siguiente paso es establecer con precisión qué valores del estadístico de prueba causarían es rechazar la hipótesis nula, y qué valores harían que la mantuviéramos. Para ello, necesitamos determinar cuál sería la distribución muestral del estadístico de prueba si la hipótesis nula fuera realmente cierta (hablamos de distribuciones de muestreo anteriormente en la Sección 10.3.1). ¿Por qué necesitamos esto? Porque esta distribución nos dice exactamente qué valores de X nuestra hipótesis nula nos llevaría a esperar. Y por lo tanto, podemos utilizar esta distribución como herramienta para evaluar qué tan cerca concuerda la hipótesis nula con nuestros datos.
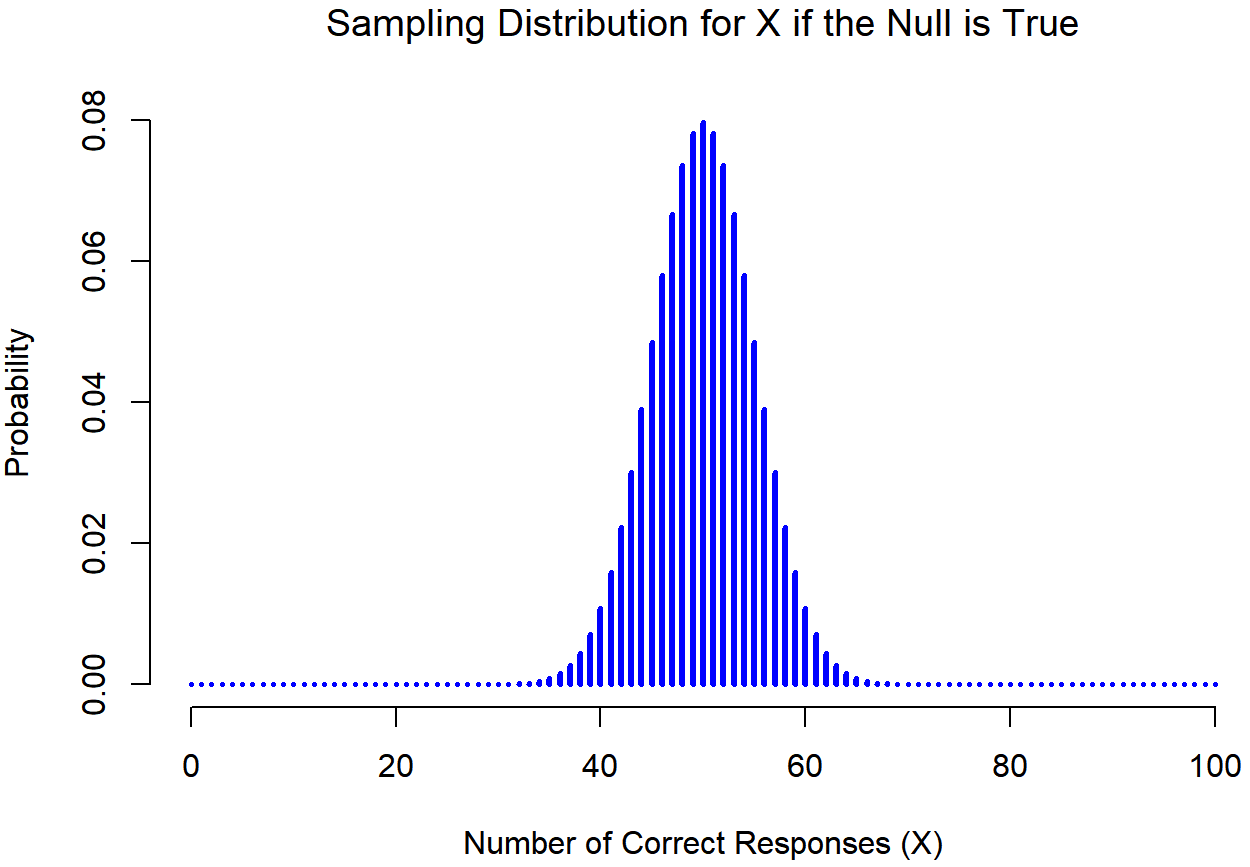
¿Cómo determinamos realmente la distribución muestral del estadístico de prueba? Para muchas pruebas de hipótesis este paso en realidad es bastante complicado, y más adelante en el libro me verás siendo un poco evasivo al respecto para algunas de las pruebas (algunas de ellas ni siquiera me entiendo). No obstante, a veces es muy fácil. Y, afortunadamente para nosotros, nuestro ejemplo ESP nos proporciona uno de los casos más fáciles. Nuestro parámetro poblacional θ es solo la probabilidad general de que las personas respondan correctamente cuando se les hace la pregunta, y nuestro estadístico de prueba X es el recuento del número de personas que lo hicieron, de un tamaño de muestra de N. Hemos visto una distribución como esta antes, en la Sección 9.4: eso es exactamente lo que describe la distribución binomial! Entonces, para usar la notación y terminología que introduje en esa sección, diríamos que la hipótesis nula predice que X se distribuye binomialmente, que se escribe
X∼Binomial (θ, N)
Dado que la hipótesis nula establece que θ=0.5 y nuestro experimento tiene N=100 personas, tenemos la distribución de muestreo que necesitamos. Esta distribución de muestreo se grafica en la Figura 11.1. Realmente no hay sorpresas: la hipótesis nula dice que X=50 es el resultado más probable, y dice que estamos casi seguros de ver en algún lugar entre 40 y 60 respuestas correctas.