
14.4: Error estándar de la estimación
- Page ID
- 152308

Objetivos de aprendizaje
- Hacer juicios sobre el tamaño del error estándar de la estimación a partir de una gráfica de dispersión
- Calcular el error estándar de la estimación basado en errores de predicción
- Calcular el error estándar usando la correlación de Pearson
- Estimar el error estándar de la estimación con base en una muestra
La figura\(\PageIndex{1}\) muestra dos ejemplos de regresión. Se puede ver que en\(\text{Graph A}\), los puntos están más cerca de la línea de lo que están en\(\text{Graph B}\). Por lo tanto, las predicciones en\(\text{Graph A}\) son más precisas que en\(\text{Graph B}\).
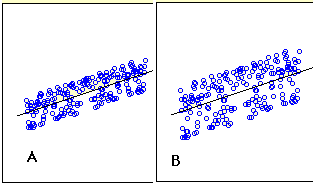
El error estándar de la estimación es una medida de la precisión de las predicciones. Recordemos que la línea de regresión es la línea que minimiza la suma de las desviaciones cuadradas de predicción (también llamada el error de suma de cuadrados). El error estándar de la estimación está estrechamente relacionado con esta cantidad y se define a continuación:
\[\sigma _{est}=\sqrt{\frac{\sum (Y-Y')^2}{N}}\]
donde\(\sigma _{est}\) está el error estándar de la estimación,\(Y\) es una puntuación real,\(Y'\) es una puntuación predicha, y\(N\) es el número de pares de puntuaciones. El numerador es la suma de las diferencias al cuadrado entre las puntuaciones reales y las puntuaciones predichas.
Observe la similitud de la fórmula para\(\sigma _{est}\) a la fórmula para σ. Resulta que σest es la desviación estándar de los errores de predicción (cada uno\(Y - Y'\) es un error de predicción).
Supongamos que los datos en la Tabla\(\PageIndex{1}\) son los datos de una población de cinco\(X\),\(Y\) pares.
| X | Y | Y' | Y-Y' | (Y-Y') 2 | |
|---|---|---|---|---|---|
| 1.00 | 1.00 | 1.210 | -0.210 | 0.044 | |
| 2.00 | 2.00 | 1.635 | 0.365 | 0.133 | |
| 3.00 | 1.30 | 2.060 | -0.760 | 0.578 | |
| 4.00 | 3.75 | 2.485 | 1.265 | 1.600 | |
| 5.00 | 2.25 | 2.910 | -0.660 | 0.436 | |
| Suma | 15.00 | 10.30 | 10.30 | 0.000 | 2.791 |
La última columna muestra que la suma de los errores cuadrados de predicción es\(2.791\). Por lo tanto, el error estándar de la estimación es
\[\sigma _{est}=\sqrt{\frac{2.791}{5}}=0.747\]
Existe una versión de la fórmula para el error estándar en términos de correlación de Pearson:
\[\sigma _{est}=\sqrt{\frac{(1-\rho )^2SSY}{N}}\]
donde\(ρ\) está el valor poblacional de la correlación de Pearson y\(SSY\) es
\[SSY=\sum (Y-\mu _Y)^2\]
Para los datos en la Tabla\(\PageIndex{1}\),\(μ_Y = 2.06\),\(SSY = 4.597\) y\(ρ= 0.6268\). Por lo tanto,
\[\sigma _{est}=\sqrt{\frac{(1-0.6268^2)(4.597)}{5}}=\sqrt{\frac{2.791}{5}}=0.747\]
que es el mismo valor calculado anteriormente.
Se utilizan fórmulas similares cuando el error estándar de la estimación se calcula a partir de una muestra en lugar de una población. La única diferencia es que el denominador es\(N-2\) más que\(N\). La razón\(N-2\) se utiliza más que\(N-1\) es que se estimaron dos parámetros (la pendiente y la intersección) para estimar la suma de cuadrados. A continuación se muestran las fórmulas para una muestra comparable a las de una población.
\[s _{est}=\sqrt{\frac{\sum (Y-Y')^2}{N-2}}\]
\[s _{est}=\sqrt{\frac{2.791}{3}}=0.964\]
\[s _{est}=\sqrt{\frac{(1-r)^2SSY}{N-2}}\]