
6.2: La media muestral
- Page ID
- 152201

Teoría Básica
Recordemos el modelo básico de estadística: tenemos una población de objetos de interés, y tenemos diversas medidas (variables) que hacemos sobre los objetos. Seleccionamos objetos de la población y registramos las variables para los objetos de la muestra; estas se convierten en nuestros datos. Nuestra primera discusión es desde un punto de vista puramente descriptivo. Es decir, no asumimos que los datos son generados por una distribución de probabilidad subyacente. Sin embargo, recordemos que los propios datos definen una distribución de probabilidad.
Definición y Propiedades Básicas
Supongamos que\(\bs{x} = (x_1, x_2, \ldots, x_n)\) es una muestra de tamaño\(n\) de una variable de valor real. La media muestral es simplemente la media aritmética de los valores de la muestra:\[ m = \frac{1}{n} \sum_{i=1}^n x_i \]
Si queremos enfatizar la dependencia de la media sobre los datos, escribimos\(m(\bs{x})\) en lugar de solo\(m\). Tenga en cuenta que\(m\) tiene las mismas unidades físicas que la variable subyacente. Por ejemplo, si tenemos una muestra de pesos de cigarras, en gramos, entonces\(m\) está en gramos también. La media muestral se utiliza frecuentemente como medida del centro de los datos. En efecto, si cada uno\(x_i\) es la ubicación de una masa puntual, entonces\(m\) es el centro de masa como se define en la física. De hecho, una simple visualización gráfica de los datos es la gráfica de puntos: en una recta numérica, se coloca un punto en\(x_i\) para cada uno\(i\). Si se repiten los valores, los puntos se apilan verticalmente. La media muestral\(m\) es el punto de equilibrio de la gráfica de puntos. La siguiente imagen muestra una gráfica de puntos con la media como punto de equilibrio.
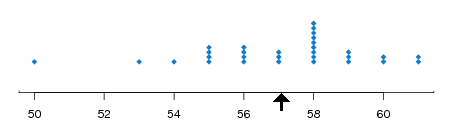
La notación estándar para la media muestral correspondiente a los datos\(\bs{x}\) es\(\bar{x}\). Rompemos con la tradición y no usamos la notación de barras en este texto, porque es torpe y porque es inconsistente con la notación para otras estadísticas como la varianza de la muestra, la desviación estándar de la muestra y la covarianza muestral. No obstante, debes estar al tanto de la notación estándar, ya que sin duda la verás en otras fuentes.
Los siguientes ejercicios establecen algunas propiedades simples de la media muestral. Supongamos que\(\bs{x} = (x_1, x_2, \ldots, x_n)\) y\(\bs{y} = (y_1, y_2, \ldots, y_n)\) son muestras de tamaño\(n\) a partir de variables poblacionales de valor real y que\(c\) es una constante. En notación vectorial, recuerda eso\(\bs{x} + \bs{y} = (x_1 + y_1, x_2 + y_2, \ldots, x_n + y_n)\) y\(c \bs{x} = (c x_1, c x_2, \ldots, c x_n)\).
El cálculo de la media de la muestra es una operación lineal.
- \(m(\bs{x} + \bs{y}) = m(\bs{x}) + m(\bs{y})\)
- \(m(c \, \bs{x}) = c \, m(\bs{x})\)
Prueba
- \[ m(\bs{x} + \bs{y}) = \frac{1}{n} \sum_{i=1}^n (x_i + y_i) = \frac{1}{n} \sum_{i=1}^n x_i + \frac{1}{n} \sum_{i=1}^n y_i = m(\bs{x}) + m(\bs{y}) \]
- \[ m(c \bs{x}) = \frac{1}{n} \sum_{i=1}^n c x_i = c \frac{1}{n} \sum_{i=1}^n x_i = c m(\bs{x}) \]
La media muestral conserva el orden.
- Si\(x_i \ge 0\) para cada\(i\) entonces\(m(\bs{x}) \ge 0\).
- Si\(x_i \ge 0\) para cada uno\(i\) y\(x_j \gt 0\) para algunos\(j\) ellos\(m(\bs{x}) \gt 0\)
- Si\(x_i \le y_i\) para cada uno\(i\) entonces\(m(\bs{x}) \le m(\bs{y})\)
- Si\(x_i \le y_i\) para cada uno\(i\) y\(x_j \lt y_j\) para algunos\(j\) entonces\(m(\bs{x}) \lt m(\bs{y})\)
Prueba
Las partes (a) y (b) son obvias a partir de la definición. La parte (c) se desprende de la parte (a) y la linealidad del valor esperado. Específicamente, si\(\bs{x} \le \bs{y}\) (en el pedido del producto), entonces\(\bs{y} - \bs{x} \ge 0\). De ahí por (a),\(m(\bs{y} - \bs{x}) \ge 0\). Pero\(m(\bs{y} - \bs{x}) = m(\bs{y}) - m(\bs{x})\). De ahí\(m(\bs{y}) \ge m(\bs{x})\). De igual manera, d) se desprende de (b) y la linealidad del valor esperado.
Trivialmente, la media de una muestra constante es simplemente la constante.
Si\(\bs{c} = (c, c, \ldots, c)\) es una muestra constante entonces\(m(\bs{c}) = c\).
Prueba
Tenga en cuenta que
\[m(\bs{c}) = \frac{1}{n} \sum_{i=1}^n c_i = \frac{n c}{n} = c\]Como caso especial de estos resultados, supongamos que\(\bs{x} = (x_1, x_2, \ldots, x_n)\) es una muestra de tamaño\(n\) correspondiente a una variable real\(x\), y que\(a\) y\(b\) son constantes. Entonces la muestra correspondiente a la variable\(y = a + b x\), en nuestra notación vectorial, es\(\bs{a} + b \bs{x}\). Las medias muestrales están relacionadas precisamente de la misma manera, es decir,\(m(\bs{a} + b \bs{x}) = a + b m(\bs{x})\). Transformaciones lineales de este tipo, cuando\(b \gt 0\), surgen frecuentemente cuando se cambian las unidades físicas. En este caso, la transformación a menudo se denomina transformación de escala de ubicación;\(a\) es el parámetro de ubicación y\(b\) es el parámetro de escala. Por ejemplo, si\(x\) es la longitud de un objeto en pulgadas, entonces\(y = 2.54 x\) es la longitud del objeto en centímetros. Si\(x\) es la temperatura de un objeto en grados Fahrenheit, entonces\(y = \frac{5}{9}(x - 32)\) es la temperatura del objeto en grados Celsius.
Las medias muestrales son ubicuas en la estadística. En los siguientes párrafos consideraremos una serie de estadísticas especiales que se basan en medias muestrales.
La distribución empírica
Supongamos ahora que\(\bs{x} = (x_1, x_2, \ldots, x_n)\) es una muestra\(n\) de tamaño de una variable general tomando valores en un conjunto\( S \). Para\(A \subseteq S\), la frecuencia de\(A\) correspondiente a\(\bs{x}\) es el número de valores de datos que se encuentran en\(A\):\[ n(A) = \#\{i \in \{1, 2, \ldots, n\}: x_i \in A\} = \sum_{i=1}^n \bs{1}(x_i \in A)\] La frecuencia relativa de\(A\) correspondiente a\(\bs{x}\) es la proporción de valores de datos que se encuentran en\(A\):\[ p(A) = \frac{n(A)}{n} = \frac{1}{n} \, \sum_{i=1}^n \bs{1}(x_i \in A)\] Tenga en cuenta que para fijo\(A\),\(p(A)\) es en sí mismo una media muestral, correspondiente a los datos\(\{\bs{1}(x_i \in A): i \in \{1, 2, \ldots, n\}\}\). Este hecho vale la pena repetirse: cada proporción muestral es una media muestral, correspondiente a una variable indicadora. En la imagen de abajo, los puntos rojos representan los datos, entonces\(p(A) = 4/15\).
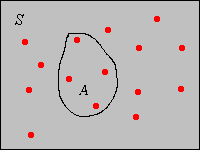
\(p\)es una medida de probabilidad en\(S\).
- \(p(A) \ge 0\)para cada\(A \subseteq S\)
- \(p(S) = 1\)
- Si\(\{A_j: j \in J\}\) es una colección contable de subconjuntos disjont por pares de\(S\) entonces\(p\left(\bigcup_{j \in J} A_j\right) = \sum_{j \in J} p(A_j)\)
Prueba
Las partes (a) y (b) son obvias. Para la parte (c) tenga en cuenta que como los conjuntos son disjuntos,\ begin {align} p\ left (\ bigcup_ {i\ in I} a_i\ right) & =\ frac {1} {n}\ sum_ {i=1} ^n\ bs {1}\ left (x_i\ in\ bigcup_ {j\ in J} a_J\ right) =\ frac {1} n}\ suma_ {i=1} ^n\ suma_ {j\ en J}\ bs {1} (x_i\ en a_J)\\ & =\ suma_ {j\ en J}\ frac {1} {n}\ suma_ {i=1} ^n\ bs {1} (x_i\ en A_ j) =\ suma_ {j\ en J} p (a_J)\ end {align}
Esta medida de probabilidad se conoce como la distribución empírica de probabilidad asociada al conjunto de datos\(\bs{x}\). Se trata de una distribución discreta que coloca la probabilidad\(\frac{1}{n}\) en cada punto\(x_i\). De hecho, esta observación aporta una prueba más sencilla del teorema anterior. Así, si los valores de los datos son distintos, la distribución empírica es la distribución uniforme discreta en\(\{x_1, x_2, \ldots, x_n\}\). De manera más general, si\(x \in S\) ocurre\(k\) tiempos en los datos entonces la distribución empírica asigna probabilidad\(k/n\) a\(x\).
Si la variable subyacente es de valor real, entonces claramente la media de la muestra es simplemente la media de la distribución empírica. De ello se deduce que la media muestral satisface todas las propiedades de valor esperado, no solo las propiedades lineales y propiedades crecientes dadas anteriormente. Estas propiedades son solo las más importantes, y así se repitieron para enfatizar.
Densidad Empírica
Supongamos ahora que la variable poblacional\(x\) toma valores en un conjunto\(S \subseteq \R^d\) para algunos\(d \in \N_+\). Recordemos que la medida estándar en\(\R^d\) viene dada por\[ \lambda_d(A) = \int_A 1 \, dx, \quad A \subseteq \R^d \] En particular\(\lambda_1(A)\) es la longitud de\(A\), para\(A \subseteq \R\);\(\lambda_2(A)\) es el área de\(A\), para\(A \subseteq \R^2\); y\(\lambda_3(A)\) es el volumen de\(A\), para\(A \subseteq \R^3\). Supongamos que\(x\) es una variable continua en el sentido de que\(\lambda_d(S) \gt 0\). Típicamente,\(S\) es un intervalo si\(d = 1\) y un producto cartesiano de intervalos si\(d \gt 1\). Ahora para\(A \subseteq S\) con\(\lambda_d(A) \gt 0\), la densidad empírica de\(A\) correspondiente a\(\bs{x}\) es\[ D(A) = \frac{p(A)}{\lambda_d(A)} = \frac{1}{n \, \lambda_d(A)} \sum_{i=1}^n \bs{1}(x_i \in A) \] Así, la densidad empírica de\(A\) es la proporción de valores de datos en\(A\), dividido por el tamaño de\(A\). En la imagen de abajo (correspondiente a\(d = 2\)), si\(A\) tiene área 5, digamos, entonces\(D(A) = 4/75\).
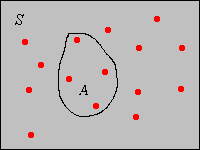.png)
La función de distribución empírica
Supongamos nuevamente que\(\bs{x} = (x_1, x_2, \ldots, x_n)\) es una muestra de tamaño\(n\) de una variable de valor real. Para\(x \in \R\), vamos a\(F(x)\) denotar la frecuencia relativa (probabilidad empírica) de\((-\infty, x]\) correspondiente al conjunto de datos\(\bs{x}\). Así, para cada uno\(x \in \R\),\(F(x)\) es la media muestral de los datos\(\{\bs{1}(x_i \le x): i \in \{1, 2, \ldots, n\}\}:\)\[ F(x) = p\left((-\infty, x]\right) = \frac{1}{n} \sum_{i=1}^n \bs{1}(x_i \le x) \]
\(F\)es una función de distribución.
- \(F\)aumenta de 0 a 1.
- \(F\)es una función de paso con saltos en los distintos valores de muestra\(\{x_1, x_2, \ldots, x_n\}\).
Prueba
Supongamos que\((y_1,y_2, \ldots, y_k)\) son los valores distintos de los datos, ordenados de menor a mayor, y eso\(y_j\) ocurre\(n_j\) tiempos en los datos. Entonces\(F(x) = 0\) para\(x \lt y_1\),\(F(x) = n_1 / n\) para\(y_1 \le x \lt y_2\),\(F(x) = (n_1 + n_2)/n\) para\(y_2 \le x \lt y_3\), y así sucesivamente.
Apropiadamente,\(F\) se llama la función de distribución empírica asociada\(\bs{x}\) y es simplemente la función de distribución de la distribución empírica correspondiente a\(\bs{x}\). Si conocemos el tamaño de la muestra\(n\) y la función de distribución empírica\(F\), podemos recuperar los datos, excepto por el orden de las observaciones. Los valores distintos de los datos son los lugares donde\(F\) salta, y el número de valores de datos en ese punto es el tamaño del salto, multiplicado por el tamaño de la muestra\(n\).
La función de densidad discreta empírica
Supongamos ahora que\(\bs{x} = (x_1, x_2, \ldots, x_n)\) es una muestra\(n\) de tamaño de una variable discreta que toma valores en un conjunto contable\(S\). For\(x \in S\), deja\(f(x)\) ser la frecuencia relativa (probabilidad empírica) de\(x\) corresponder al conjunto de datos\(\bs{x}\). Así, para cada uno\(x \in S\),\(f(x)\) es la media muestral de los datos\(\{\bs{1}(x_i = x): i \in \{1, 2, \ldots, n\}\}\):\[ f(x) = p(\{x\}) = \frac{1}{n} \sum_{i=1}^n \bs{1}(x_i = x) \] En la imagen de abajo, los puntos son los posibles valores de la variable subyacente. Los puntos rojos representan los datos, y los números indican valores repetidos. Los puntos azules son posibles valores de la variable que no ocurrieron en los datos. Entonces, el tamaño de la muestra es 12, y para el valor\(x\) que ocurre 3 veces, tenemos\(f(x) = 3/12\).
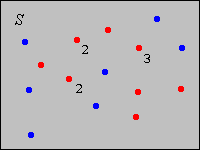
\(f\)es una función discreta de densidad probabiltiy:
- \(f(x) \ge 0\)para\(x \in S\)
- \(\sum_{x \in S} f(x) = 1\)
Prueba
La parte (a) es obvia. Para la parte b), tenga en cuenta que\[ \sum_{x \in S} f(x) = \sum_{x \in S} p(\{x\}) = 1 \]
Apropiadamente,\(f\) se llama la función de densidad de probabilidad empírica o la función de frecuencia relativa asociada a\(\bs{x}\), y es simplemente la función de densidad probabiltiy de la distribución empírica correspondiente a\(\bs{x}\). Si conocemos el PDF empírico\(f\) y el tamaño de la muestra\(n\), entonces podemos recuperar el conjunto de datos, excepto por el orden de las observaciones.
Si la variable de población subyacente es de valor real, entonces la media de la muestra es el valor esperado calculado en relación con la función de densidad empírica. Es decir,\[ \frac{1}{n} \sum_{i=1}^n x_i = \sum_{x \in S} x \, f(x) \]
Prueba
Tenga en cuenta que
\[ \sum_{x \in S} x f(x) = \sum_{x \in S} x \frac{1}{n} \sum_{i=1}^n \bs{1}(x_i = x) = \frac{1}{n}\sum_{i=1}^n \sum_{x \in S} x \bs{1}(x_i = x) = \frac{1}{n} \sum_{i=1}^n x_i \]Como señalamos anteriormente, si la variable poblacional es de valor real entonces la media de la muestra es la media de la distribución empírica.
La función de densidad continua empírica
Supongamos ahora que\(\bs{x} = (x_1, x_2, \ldots, x_n)\) es una muestra\(n\) de tamaño de una variable continua que toma valores en un conjunto\(S \subseteq \R^d\). Dejar\(\mathscr{A} = \{A_j: j \in J\}\) ser una partición de\(S\) en un número contable de subconjuntos, cada uno de medida positiva, finita. Recordemos que la palabra partición significa que los subconjuntos son disjuntos por pares y su unión es\(S\). \(f\)Sea la función on\(S\) definida por la regla que\(f(x)\) es la densidad empricial de\(A_j\), correspondiente al conjunto de datos\(\bs{x}\), para cada uno\(x \in A_j\). Así,\(f\) es constante en cada uno de los conjuntos de particiones:\[ f(x) = D(A_j) = \frac{p(A_j)}{\lambda_d(A_j)} = \frac{1}{n \lambda_d(A_j)} \sum_{i=1}^n \bs{1}(x_i \in A_j), \quad x \in A_j \]
\(f\)es una función de densidad probabiltiy continua.
- \(f(x) \ge 0\)para\(x \in S\)
- \(\int_S f(x) \, dx = 1\)
Prueba
La parte (a) es obvia. Para la parte (b) tenga en cuenta que ya\(f\) es constante\(A_j\) para cada uno\(j \in J\) tenemos
\[\int_S f(x) \, dx = \sum_{j \in J} \int_{A_j} f(x) \, dx = \sum_{j \in J} \lambda_k(A_j) \frac{p(A_j)}{\lambda_k(A_j)} = \sum_{j \in J} p(A_j) = 1 \]La función\(f\) se llama la función empírica de densidad de probabilidad asociada con los datos\(\bs{x}\) y la partición\(\mathscr{A}\). Para la distribución de probabilidad definida por\(f\), la probabilidad empírica\(p(A_j)\) se distribuye uniformemente\(A_j\) para cada uno\(j \in J\). En la imagen de abajo, los puntos rojos representan los datos y las líneas negras definen una partición de\(S\) en 9 rectángulos. Para el conjunto de particiones\(A\) en la parte superior derecha, la distribución empírica distribuiría la probabilidad\(3/15 = 1/5\) uniformemente sobre\(A\). Si el área de\(A\) es, digamos, 4, entonces\(f(x) = 1/20 \) para\(x \in A\).
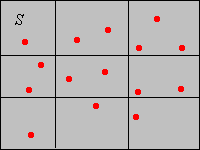
A diferencia del caso discreto, no podemos recuperar los datos del PDF empírico. Si conocemos el tamaño de la muestra, entonces por supuesto podemos determinar el número de puntos de datos en\(A_j\) para cada uno\(j\), pero no la ubicación precisa de estos puntos en\(A_j\). Por esta razón, la media del PDF empírico no es en general la misma que la media de la muestra cuando la variable subyacente es de valor real.
Histogramas
Nuestra siguiente discusión está estrechamente relacionada con la anterior. Supongamos nuevamente que\(\bs{x} = (x_1, x_2, \ldots, x_n)\) es una muestra\(n\) de tamaño de una variable que toma valores en un conjunto\(S\) y que\(\mathscr{A} = (A_1, A_2, \ldots, A_k)\) es una partición de\(S\) en\(k\) subconjuntos. Los conjuntos en la partición a veces se conocen como clases. La variable subyacente puede ser discreta o continua.
- El mapeo que asigna frecuencias a clases se conoce como distribución de frecuencias para el conjunto de datos y la partición dada.
- El mapeo que asigna frecuencias relativas a clases se conoce como distribución de frecuencia relativa para el conjunto de datos y la partición dada.
- En el caso de una variable continua, el mapeo que asigna densidades a clases se conoce como distribución de densidad para el conjunto de datos y la partición dada.
En las dimensiones 1 o 2, el gráfico de barras cualquiera de estas distribuciones, se conoce como histograma. El histograma de una distribución de frecuencia y el histograma de la distribución de frecuencia relativa correspondiente tienen el mismo aspecto, excepto por un cambio de escala en el eje vertical. Si todas las clases tienen el mismo tamaño, el histograma del histograma de densidad correspondiente también se ve igual, nuevamente a excepción de un cambio de escala en el eje vertical. Si la variable subyacente es de valor real, las clases suelen ser intervalos (discretos o continuos) y los puntos medios de estos intervalos a veces se denominan marcas de clase.
Todo el propósito de construir una partición y graficar una de estas distribuciones empíricas correspondientes a la partición es resumir y mostrar los datos de manera significativa. Así, existen algunas pautas generales en la elección de las clases:
- El número de clases debe ser moderado.
- Si es posible, las clases deben tener el mismo tamaño.
Para distribuciones altamente sesgadas, las clases de diferentes tamaños son apropiadas, para evitar numerosas clases con frecuencias muy pequeñas. Para una variable continua con clases de diferentes tamaños, es esencial usar un histograma de densidad, en lugar de un histograma de frecuencia o frecuencia relativa, de lo contrario el gráfico es visualmente engañoso, y de hecho matemáticamente incorrecto.
Es importante darse cuenta de que los datos de frecuencia son inevitables para una variable continua. Por ejemplo, supongamos que nuestra variable representa el peso de una bolsa de M&Ms (en gramos) y que nuestro dispositivo de medición (una báscula) tiene una precisión de 0.01 gramos. Si medimos el peso de una bolsa como 50.32, entonces realmente estamos diciendo que el peso está en el intervalo\([50.315, 50.324)\) (o quizás algún otro intervalo, dependiendo de cómo funcione el dispositivo de medición). De igual manera, cuando dos bolsas tienen el mismo peso medido, la aparente igualdad de los pesos es realmente solo un artefacto de la imprecisión del dispositivo de medición; en realidad las dos bolsas casi con certeza no tienen exactamente el mismo peso. Así, dos bolsas con el mismo peso medido realmente nos dan un recuento de frecuencia de 2 para un cierto intervalo.
Nuevamente, existe un compromiso entre el número de clases y el tamaño de las clases; éstas determinan la resolución de la distribución empírica correspondiente a la partición. En un extremo, cuando el tamaño de la clase es menor que la precisión de los datos registrados, cada clase contiene un solo dato o ningún dato. En este caso, no hay pérdida de información y podemos recuperar el conjunto de datos original a partir de la distribución de frecuencias (excepto por el orden en que se obtuvieron los valores de los datos). Por otro lado, puede ser difícil discernir la forma de los datos cuando tenemos muchas clases con poca frecuencia. En el otro extremo hay una distribución de frecuencia con una clase que contiene todos los valores posibles del conjunto de datos. En este caso, se pierde toda la información, excepto el número de los valores en el conjunto de datos. Entre estos dos casos extremos, una distribución empírica nos da información parcial, pero no información completa. Estos casos intermedios pueden organizar los datos de una manera útil.
Ogives
Supongamos que ahora la variable subyacente es de valor real y que el conjunto de valores posibles se divide en intervalos\((A_1, A_2, \ldots, A_k)\), con los extremos de los intervalos ordenados de menor a mayor. Dejar\(n_j\) denotar la frecuencia de clase\(A_j\), de modo que esa\(p_j = n_j / n\) es la frecuencia relativa de la clase\(A_j\). Dejar\(t_j\) denotar la marca de clase (punto medio) de clase\(A_j\). La frecuencia acumulativa de clase\(A_j\) es\(N_j = \sum_{i=1}^j n_i\) y la frecuencia relativa acumulativa de clase\(A_j\) es\(P_j = \sum_{i=1}^j p_i = N_j / n\). Tenga en cuenta que las frecuencias acumuladas aumentan de\(n_1\) a\(n\) y las frecuencias relativas acumuladas aumentan de\(p_1\) a 1.
- El mapeo que asigna frecuencias acumulativas a clases se conoce como distribución de frecuencia acumulativa para el conjunto de datos y la partición dada. La gráfica poligonal que conecta los puntos\((t_j, N_j)\) para\(j \in \{1, 2, \ldots, k\}\) es la frecuencia acumulada ogive.
- El mapeo que asigna frecuencias relativas acumulativas a clases se conoce como distribución de frecuencia relativa acumulativa para el conjunto de datos y la partición dada. La gráfica poligonal que conecta los puntos\((t_j, P_j)\) para\(j \in \{1, 2, \ldots, k\}\) es la frecuencia relativa acumulativa ogive.
Tenga en cuenta que la frquencia relativa ogive es simplemente la gráfica de la función de distribución correspondiente a la distribución de probabilidad que coloca la probabilidad\(p_j\) en\(t_j\) para cada uno\(j\).
Aproximación a la media
En la configuración de la última subsección, supongamos que no tenemos los datos reales\(\bs{x}\), sino solo la distribución de frecuencias. Un valor aproximado de la media muestral es\[ \frac{1}{n} \sum_{j = 1}^k n_j t_j = \sum_{j = 1}^k p_j t_j \] Esta aproximación se basa en la esperanza de que la media de los valores de datos en cada clase esté cerca del punto medio de esa clase. De hecho, la expresión a la derecha es el valor esperado de la distribución que coloca la probabilidad\(p_j\) en la marca de clase\(t_j\) para cada una\(j\).
Ejercicios
Propiedades Básicas
Supongamos que\(x\) es la temperatura (en grados Fahrenheit) para cierto tipo de componente electrónico después de 10 horas de funcionamiento.
- Clasificar\(x\) por tipo y nivel de medición.
- Una muestra de 30 componentes tiene una media de 113°. Encuentra la media de la muestra si la temperatura se convierte a grados Celsius. La transformación es\(y = \frac{5}{9}(x - 32)\).
Responder
- continuo, intervalo
- 45°
Supongamos que\(x\) es la longitud (en pulgadas) de una pieza mecanizada en un proceso de fabricación.
- Clasificar\(x\) por tipo y nivel de medición.
- Una muestra de 50 partes tiene una media de 10.0. Encuentra la media de la muestra si la longitud se mide en centímetros. La transformación es\(y = 2.54 x\).
Responder
- continuo, relación
- 25.4
Supongamos que ese\(x\) es el número de hermanos y\(y\) el número de hermanas para una persona en cierta población. Así,\(z = x + y\) es el número de hermanos.
- Clasificar las variables por tipo y nivel de medición.
- Para una muestra de 100 personas,\(m(\bs{x}) = 0.8\) y\(m(\bs{y}) = 1.2\). Encuentra\(m(\bs{z})\).
Responder
- discreto, relación
- 2.0
La profesora Moriarity cuenta con una clase de 25 alumnos en su sección de Stat 101 en Enormous State University (ESU). La nota media en el primer examen de mitad de período fue de 64 (de un posible 100 puntos). El profesor Moriarity piensa que las calificaciones son un poco bajas y está considerando diversas transformaciones para aumentar las calificaciones. En cada caso a continuación dar la media de las calificaciones transformadas, o indicar que no hay suficiente información.
- Suma 10 puntos a cada grado, por lo que la transformación es\(y = x + 10\).
- Multiplica cada grado por 1.2, por lo que la transformación es\(z = 1.2 x\)
- Usa la transformación\(w = 10 \sqrt{x}\). Tenga en cuenta que esta es una transformación no lineal que curva las calificaciones en gran medida en el extremo inferior y muy poco en el extremo alto. Por ejemplo, una nota de 100 sigue siendo 100, pero una nota de 36 se transforma a 60.
Uno de los alumnos no cursó estudios en absoluto, y recibió un 10 en el semestre. El profesor Moriarity considera que esta puntuación es un valor atípico.
- ¿Cuál sería la media si se omite esta puntuación?
Responder
- 74
- 76.8
- No hay suficiente información
- 66.25
Ejercicios Computacionales
Todos los paquetes de software estadístico calcularán medias y proporciones, dibujarán diagramas de puntos e histogramas, y en general realizarán los procedimientos numéricos y gráficos discutidos en esta sección. Para experimentos estadísticos reales, particularmente aquellos con grandes conjuntos de datos, el uso de software estadístico es esencial. Por otro lado, hay cierto valor en la realización de los cálculos a mano, con pequeños conjuntos de datos artificiales, con el fin de dominar los conceptos y definiciones. En esta subsección, haga los cómputos y dibuje las gráficas con ayudas tecnológicas mínimas.
Supongamos que\(x\) es el número de cursos de matemáticas realizados por un estudiante de ESU. Una muestra de 10 estudiantes de ESU da los datos\(\bs{x} = (3, 1, 2, 0, 2, 4, 3, 2, 1, 2)\).
- Clasificar\(x\) por tipo y nivel de medición.
- Esbozar la trama de punto.
- Calcular la media muestral\(m\) a partir de la definición e indicar su ubicación en la gráfica de puntos.
- Encuentra la función de densidad empírica\(f\) y dibuja el gráfico.
- Calcular la media de la muestra\(m\) usando\(f\).
- Encuentra la función de distribución empírica\(F\) y dibuja el gráfico.
Responder
- discreto, relación
- 2
- \(f(0) = 1/10\),\(f(1) = 2/10\),\(f(2) = 4/10\),\(f(3) = 2/10\),\(f(4) = 1/10\)
- 2
- \(F(x) = 0\)para\(x \lt 0\),\(F(x) = 1/10\) para\(0 \le x \lt 1\),\(F(x) = 3/10\) para\(1 \le x \lt 2\),\(F(x) = 7/10\) para\(2 \le x \lt 3\),\(F(x) = 9/10\) para\(3 \le x \lt 4\),\(F(x) = 1\) para\(x \ge 4\)
Supongamos que una muestra de tamaño 12 de una variable discreta\(x\) tiene una función de densidad empírica dada por\(f(-2) = 1/12\)\(f(-1) = 1/4\),,\(f(0) = 1/3\),\(f(1) = 1/6\),\(f(2) = 1/6\).
- Esbozar la gráfica de\(f\).
- Calcular la media de la muestra\(m\) usando\(f\).
- Encuentra la función de distribución empírica\(F\)
- Dar los valores de la muestra, ordenados de menor a mayor.
Responder
- \(1/12\)
- \(F(x) = 0\)para\(x \lt -2\),\(F(x) = 1/12\) para\(-2 \le x \lt -1\),\(F(x) = 1/3\) para\(-1 \le x \lt 0\),\(F(x) = 2/3\) para\(0 \le x \lt 1\),\(F(x) = 5/6\) para\(1 \le x \lt 2\),\(F(x) = 1\) para\(x \ge 2\)
- \((-2, -1, -1, -1, 0, 0, 0, 0, 1, 1, 2, 2)\)
La siguiente tabla da una distribución de frecuencia para la distancia de desplazamiento al edificio de matemáticas/estadísticas (en millas) para una muestra de estudiantes de ESU.
| Clase | Freq | Rel Freq | Densidad | Cum Freq | Cum Rel Freq | Punto medio |
|---|---|---|---|---|---|---|
| \((0,2]\) | 6 | |||||
| \((2,6]\) | 16 | |||||
| \((6,10]\) | 18 | |||||
| \((10,20]\) | 10 | |||||
| Total |
- Completa la tabla
- Esbozar el histograma de densidad
- Esbozar la fracción relativa acumulativa ogive.
- Calcular una aproximación a la media
Responder
-
Clase Freq Rel Freq Densidad Cum Freq Cum Rel Freq Punto medio \((0,2]\) 6 0.12 0.06 6 0.12 1 \((2,6]\) 16 0.32 0.08 22 0.44 4 \((6, 10]\) 18 0.36 0.09 40 0.80 8 \((10, 20])\) 10 0.20 0.02 50 1 15 Total 50 1 - 7.28
Ejercicios de App
En el histograma interactivo, haga clic en el\(x\) eje -en varios puntos para generar un conjunto de datos con al menos 20 valores. Varíe el número de clases y cambie entre el histograma de frecuencia y el histograma de frecuencia relativa. Observe cómo cambia la forma del histograma a medida que realiza estas operaciones. Observe en particular cómo el histograma pierde resolución a medida que disminuye el número de clases.
En el histograma interactivo, haga clic en el eje para generar una distribución del tipo dado con al menos 30 puntos. Ahora varíe el número de clases y observe cómo cambia la forma de la distribución.
- Una distribución uniforme
- Una distribución unimodal simétrica
- Una distribución unimodal que está sesgada a la derecha.
- Una distribución unimodal que está sesgada a la izquierda.
- Una distribución bimodal simétrica
- Una distribución\(u\) en forma.
Ejercicios de Análisis de Datos
Se debe utilizar software estadístico para los problemas de esta subsección.
Considere la longitud de los pétalos y las variables de especie en los datos del iris de Fisher.
- Clasificar las variables por tipo y nivel de medición.
- Calcula la media muestral y traza un histograma de densidad para la longitud del pétalo.
- Calcular la media de la muestra y graficar un histograma de densidad para longitud de pétalo por especie.
RESPUESTAS
- longitud de pétalo: continuo, relación. Especie: discreta, nominal
- \(m = 37.8\)
- \(m(0) = 14.6, \; m(1) = 55.5, \; m(2) = 43.2\)
Considere la variable erosión en el conjunto de datos Challenger.
- Clasificar la variable por tipo y nivel de medición.
- Compute la media
- Trazar un histograma de densidad con las clases\([0, 5)\),\([5, 40)\),\([40, 50)\),\([50, 60)\).
Responder
- continuo, relación
- \(m = 7.7\)
Considere los datos de velocidad de la luz de Michelson.
- Clasificar la variable por tipo y nivel de medición.
- Trazar un histograma de densidad.
- Compute la media de la muestra.
- Encuentre la media muestral si la variable se convierte a\(\text{km}/\text{hr}\). La transformación es\(y = x + 299\,000\)
Responder
- continuo, intervalo
- \(m = 852.4\)
- \(m = 299\,852.4\)
Considere los datos del paráax del sol de Short.
- Clasificar la variable por tipo y nivel de medición.
- Trazar un histograma de densidad.
- Compute la media de la muestra.
- Encuentra la media muestral si la variable se convierte a grados. Hay 3600 segundos en un grado.
- Encuentra la media muestral si la variable se convierte en radianes. Hay\(\pi/180\) radianes en un grado.
Responder
- continuo, relación
- 8.616
- 0.00239
- 0.0000418
Considera los datos de la densidad de la tierra de Cavendish.
- Clasificar la variable por tipo y nivel de medición.
- Compute la media de la muestra.
- Trazar un histograma de densidad.
Responder
- continuo, relación
- \(m = 5.448\)
Considere los datos de M&M.
- Clasificar las variables por tipo y nivel de medición.
- Calcular la media de la muestra para cada variable de recuento de colores.
- Calcular la media muestral para el número total de caramelos, utilizando los resultados de (b).
- Trazar un histograma de frecuencia relativa para el número total de caramelos.
- Calcula la media de la muestra y traza un histograma de densidad para el peso neto.
Responder
- recuentos de color: relación discreta. peso neto: relación continua.
- \(m(r) = 9.60\),\(m(g) = 7.40\),\(m(bl) = 7.23\),\(m(o) = 6.63\),\(m(y) = 13.77\),\(m(br) = 12.47\)
- \(m(n) = 57.10\)
- \(m(w) = 49.215\)
Considerar el peso corporal, las especies y las variables de género en los datos de Cicada.
- Clasificar las variables por tipo y nivel de medición.
- Calcula la función de frecuencia relativa para especies y traza la gráfica.
- Calcula la función de frecuencia relativa para género y traza la gráfica.
- Calcula la media de la muestra y grafica un histograma de densidad para el peso corporal.
- Calcular la media de la muestra y graficar un histogrmo de densidad para el peso corporal por especie.
- Calcular la media de la muestra y graficar un histograma de densidad para el peso corporal por género.
Responder
- peso corporal: continuo, relación. Especie: discreta, nominal. género: discreto, nominal.
- \(f(0) = 0.423\),\(f(1) = 0.519\),\(f(2) = 0.058\)
- \(f(0) = 0.567\),\(f(1) = 0.433\)
- \(m = 0.180\)
- \(m(0) = 0.168, \; m(1) = 0.185, \; m(2) = 0.225\)
- \(m(0) = 0.206, \; m(1) = 0.145\)
Considere los datos de altura de Pearson.
- Clasificar las variables por tipo y nivel de medición.
- Calcular la media muestral y graficar un histograma de densidad para la altura del padre.
- Calcular la media muestral y graficar un histograma de densidad para la altura del hijo.
Responder
- relación continua
- \(m(f) = 67.69\)
- \(m(s) = 68.68\)