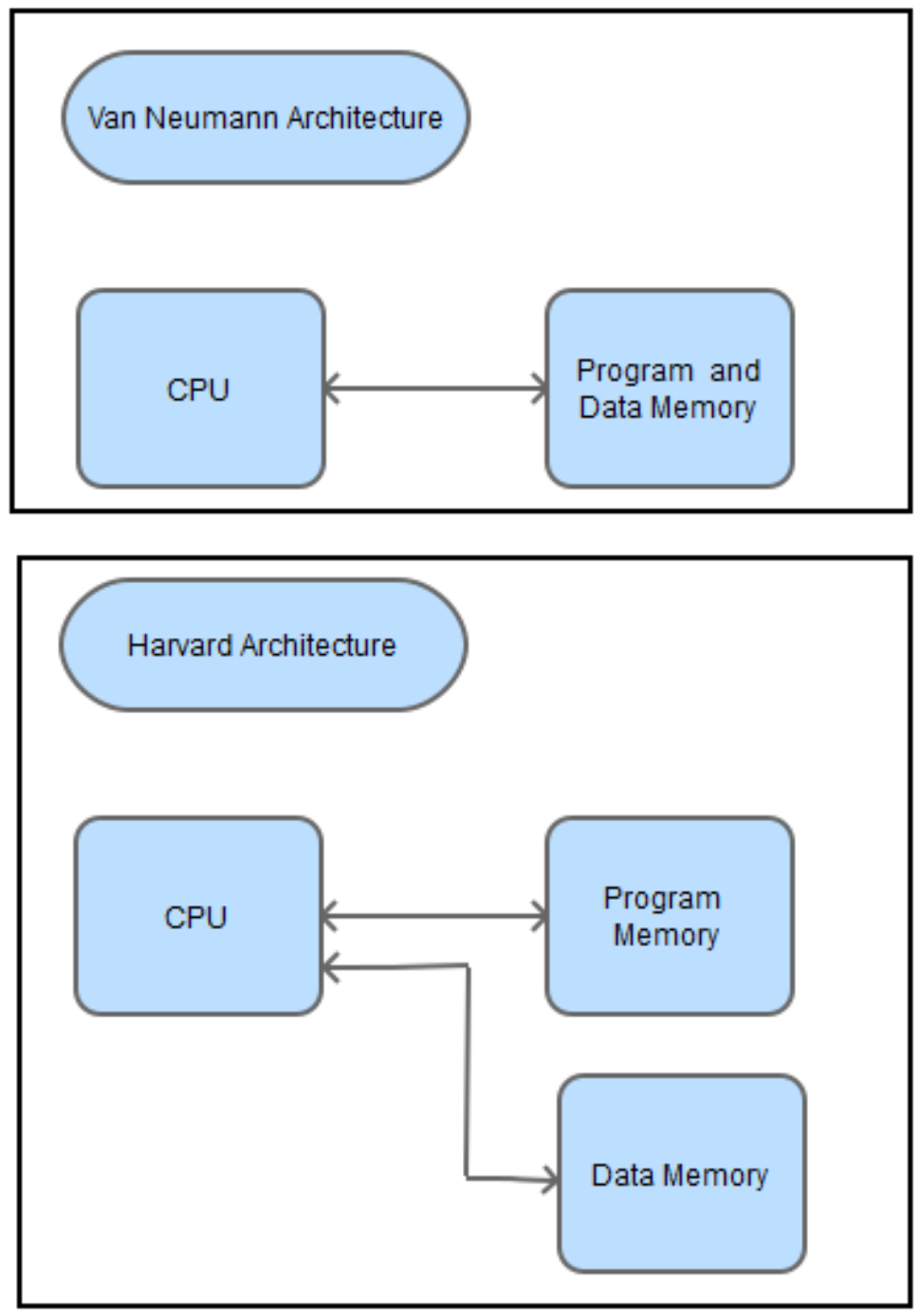
1.3: Arquitecturas de Von Neumann y Harvard
- Page ID
- 80680

Al discutir cómo se accede a la memoria a nivel de CPU, hay dos diseños a considerar. La primera es una arquitectura de Von Neumann, y la segunda es una arquitectura de Harvard. La principal diferencia entre las dos arquitecturas es que en una arquitectura de Von Neumann toda la memoria es capaz de almacenar todos los elementos del programa, datos e instrucciones; en una arquitectura de Harvard la memoria se divide en dos memorias, una para datos y otra para instrucciones.
Para esta monografía, el tema principal que implica decidir qué arquitectura usar es que algunas operaciones tienen que acceder a la memoria tanto para obtener la instrucción a ejecutar, como para acceder a los datos para operar. Debido a que solo se puede acceder a la memoria una vez por ciclo de reloj, en principio una arquitectura de Von Neumann requiere al menos dos ciclos de reloj para ejecutar una instrucción, mientras que una arquitectura de Harvard puede ejecutar instrucciones en un solo ciclo.
La capacidad en una arquitectura de Harvard para ejecutar una instrucción en una sola instrucción conduce a un diseño mucho más simple y limpio para una CPU que uno implementado usando una arquitectura de Von Neumann. Para esta primera monografía se implementará una implementación de Harvard. Posteriormente, monografías analizarán la implementación de la CPU utilizando la arquitectura de Von Neumann.