
1.5: Expresión Génica-Transcripción
- Page ID
- 56606

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)- Describir los roles que desempeñan el promotor, la región codificante y las regiones no traducidas de un gen en la expresión génica.
- Describir los pasos de procesamiento de ARNm.
- Dibuja el proceso de transcripción e incluye lo siguiente en tu dibujo. ADN molde y hebras no molde, ARN polimerasa, nueva cadena de ARN y dirección de la síntesis de ARN.
- Dibuje el proceso de procesamiento de ARNm e incluya lo siguiente en su diagrama, Gen (ADN), promotor, región codificante, intrones, exones, pre-ARNm, ARNm maduro, cola poli A, tapa.
Introducción
Los genes son secuencias de ADN que controlan rasgos en un organismo codificando proteínas (Figura 1). Organismos como plantas y animales tienen decenas de miles de genes. El impacto que la información de un solo gen puede tener en un organismo, sin embargo, es tremendo. Además, los organismos tienen todos sus genes en cada una de sus células, pero solo necesitan usar la información de un subconjunto de estos genes, dependiendo del tipo de célula y la etapa de desarrollo de la célula. Por lo tanto, la clave para la función génica es controlar su expresión.
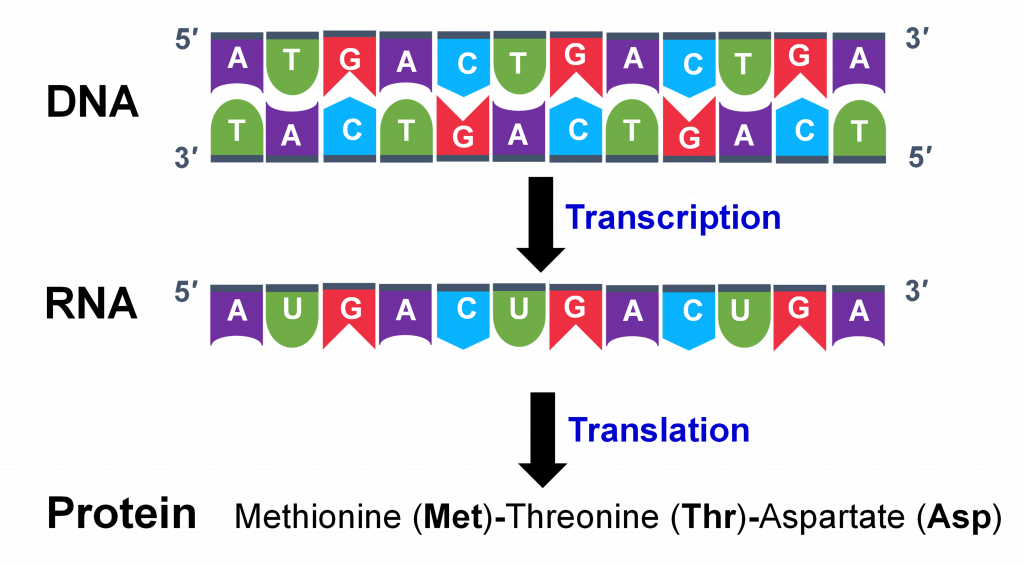
Estructura génica y transcripción
La secuencia de ADN contiene la información para controlar todas las funciones biológicas, incluyendo la manifestación de rasgos importantes para la agricultura (rendimiento, tolerancia a la sequía, resistencia a enfermedades, etc., etc.) ¿Cómo se convierte la información contenida en las secuencias de ADN en las actividades celulares necesarias para que las plantas y otros organismos funcionen? Las secuencias de ADN se utilizan para dirigir la síntesis de otras moléculas que realmente realizan estas funciones celulares.
La mayoría de los genes típicos codifican proteínas. La producción de una proteína a partir de un gen implica varios procesos diferentes (Figura 1). La transcripción implica la copia de la secuencia de nucleótidos del ADN en una molécula nucleotídica intermedia llamada ARN (ácido ribonucleico). La molécula de ARN primaria se procesa en un ARN mensajero maduro (ARNm) que luego proporciona la información para la síntesis de una proteína a través del proceso de traducción. Las proteínas están compuestas por aminoácidos conectados por enlaces peptídicos. La secuencia de aminoácidos está determinada por la secuencia de bases nucleotídicas en el ARNm. Los 20 aminoácidos tienen diferentes propiedades químicas y físicas y la secuencia de aminoácidos determina la estructura y función de la proteína.
Estructura génica
Solo se transcriben regiones particulares del ADN cromosómico. Un gen puede considerarse como la región del ADN transcrito, junto con regiones asociadas de ADN importantes para la regulación de la transcripción (Figura 1). Un gen tiene varias partes que son cada una importantes para la función del gen.
La región reguladora (también conocida como el promotor) contiene la secuencia de ADN involucrada en el control de dónde y cuándo se encenderán los genes para producir ARNm. La región codificante es la parte del gen que se utiliza como molde para producir moléculas de ARN en un proceso llamado transcripción. Algunas moléculas de ARN realizan funciones celulares directamente mientras que muchas otras (ARN mensajeros) se utilizan para dirigir la síntesis de proteínas en un proceso llamado traducción.
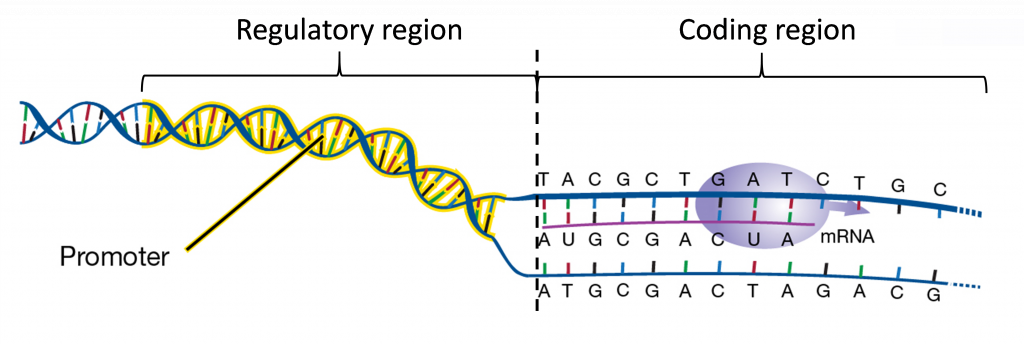
a. Promotor de genes
Las señales para iniciar y detener la transcripción se localizan dentro de las secuencias de ADN. Los segmentos específicos de nucleótidos llamados promotores son reconocidos por la ARN polimerasa para iniciar la síntesis de ARN. Una vez completada la transcripción de la cadena de ARN de longitud completa, un segundo segmento de ADN llamado terminador invoca la terminación de la síntesis de ARN y el desprendimiento de ARN polimerasas del molde de ADN.
b. Región codificante de proteínas
La región codificante de proteínas de un gen está compuesta por la secuencia de nucleótidos que codifica para aminoácidos. Como se describe más adelante en la sección de traducción, la región codificante comienza con un codón de inicio ATG (AUG en ARN) y luego termina con uno de los tres codones de terminación. Estas secuencias incluyen solo exones, pero no todas las secuencias exónicas son codificantes de proteínas, ya que pueden incluir regiones no traducidas.

c. Regiones no traducidas (UTR)
Los transcritos maduros contienen algunas secuencias que no codifican secuencias de aminoácidos en proteínas. Estas se denominan regiones no traducidas o UTR. La mayoría de los transcritos de ARNm contienen una UTR 5' y una 3''. La UTR 5' contiene secuencias hacia el extremo 5' de la secuencia de ARNm, antes del codón de inicio. Estas secuencias a menudo pueden ser importantes para la regulación traslacional, y a veces otras funciones. Las secuencias que siguen al codón de terminación son la UTR 3"”. La UTR de 3 'también puede tener importantes funciones regulando la estabilidad del transcrito o dirigiendo la localización del transcrito dentro de las células, o a veces incluso el transporte (tráfico) entre células.
Las UTR y los intrones suelen ser útiles en estudios genéticos. Las regiones codificantes de proteínas están bajo una fuerte presión selectiva para producir proteínas funcionales, por lo que la variación de secuencia es relativamente rara. Las UTR y los intrones, por otro lado, están bajo selección menos rigurosa y, por lo tanto, son fuentes de variantes de secuencia que pueden usarse para desarrollar marcadores genéticos.
Transcripción
La información genética del ADN se transfiere a una molécula intermedia llamada ARN que a menudo se traduce a secuencias de aminoácidos utilizadas para construir proteínas. El ARN es un ácido nucleico, como el ADN, pero con algunas diferencias importantes. El ARN contiene un grupo de azúcar ribosa en lugar de la desoxirribosa que se encuentra en el ADN. Las moléculas de ARN son monocatenarias, en lugar de ser bicatenarias. El ARN contiene una base de uridina (U) y no contiene una base de timidina. Las otras bases (A, C, G) están contenidas tanto en el ARN como en el ADN. U tiene la propiedad de emparejamiento de bases con A.
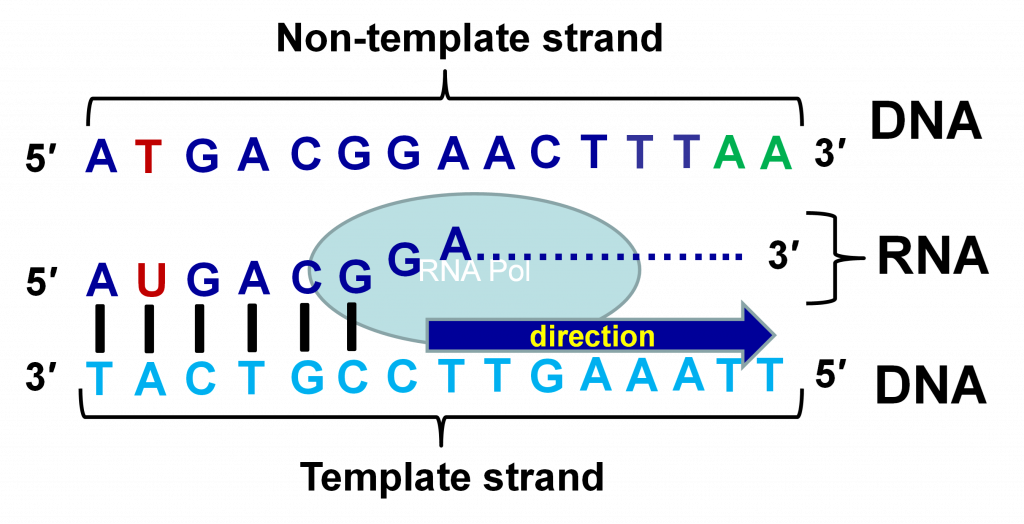
La síntesis de ARN está dirigida por un molde de ADN en un proceso llamado transcripción. Un complejo proteico que contiene la enzima ARN polimerasa sintetiza una molécula de ARN añadiendo nucleósidos al extremo 3" de una cadena en crecimiento. Se utiliza de nuevo el principio de apareamiento de bases y cada base nucleotídica añadida es complementaria a la base correspondiente en el molde de ADN. Así, el ARN es complementario en secuencia a la cadena molde del ADN, que también se denomina cadena “antisentido” o “negativa” (Figura 4). El ARN es idéntico en secuencia (excepto U reemplaza a T) a la otra cadena, que se llama la cadena “sentido” o “positiva”. Debido a que las moléculas de ARN son producidas por el proceso de transcripción, a menudo se las denomina transcripciones.
Procesamiento de ARN
Región de codificación (transcrita)
Esta es la región que es transcrita por la ARN polimerasa, también conocida como la región codificante de ARN. Como se describe a continuación, puede incluir intrones, secuencias que se eliminan de la molécula de ARN madura durante el procesamiento del ARN. La región transcrita es demarcada por secuencias promotoras y terminadoras.
Intrones y exones
Como se mencionó, y se describe en detalle a continuación, los intrones son secuencias que se eliminan de los transcritos durante el procesamiento del ARN. Las secuencias que se retienen en transcritos maduros se denominan exones. Los tramos correspondientes de ADN se denominan típicamente con los mismos términos. Los intrones se encuentran comúnmente en genes de eucariotas pero son raros en organismos procariotas.
Empalme de intrones
El proceso de transcripción produce pre-ARNm que contiene tanto intrones como exones. El proceso de corte y empalme implica la eliminación de intrones del pre-ARNm y la unión de los exones. Un complejo grupo de proteínas que forman un spliceosoma realizan la reacción de empalme.
Los intrones a veces sirven como límites para secuencias que codifican dominios de proteínas funcionales, lo que lleva a la posibilidad de proteínas nuevas y variantes por barajado de exones. Además, los intrones pueden proporcionar la posibilidad de producciones de formas de ARN variantes a través del corte y empalme alternativo permitiendo más de un producto génico de un solo gen. Algunos intrones resultan de la inserción de elementos transponibles y pueden ser empalmados perfectamente o imperfectamente, ofreciendo más posibilidades de nueva diversidad genética.
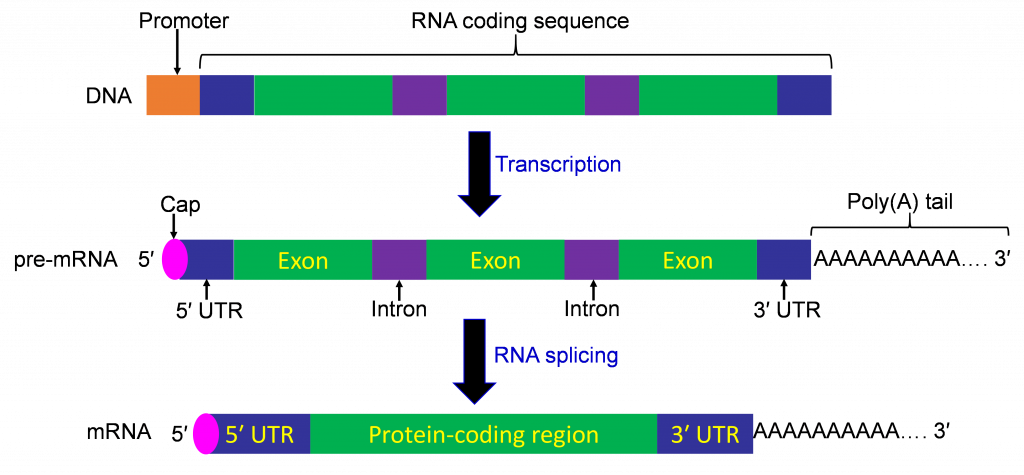
Tapado de 5′
La terminación 5' es la adición de una 7-metil guanidina al primer nucleótido de la molécula de ARNm, generalmente y adenina o guanidina. El enlace fosfodiéster entre 7-metil guanidina y el nucleótido diana es 5′-5' en lugar de 5′-3', y 3 fosfatos en lugar de 1 se retienen en el enlace. La tapa estabiliza el extremo 5' del ARNm y juega un papel en el inicio de la traducción.
Poli adenilación
La transcripción de un gen puede continuar más allá de lo que termina como extremo 3' del ARNm maduro. Así, el extremo 3" del ARNm se forma después de la transcripción. La enzima poli (A) polimerasa agrega numerosas adenosinas al extremo 3' para dar como resultado lo que se llama la cola de poli (A). La cola poli (A) es necesaria para el procesamiento y transporte adecuados del ARNm al citoplasma. La cola poli (A) también es importante para la estabilidad del ARNm y el inicio de la traducción en organismos eucariotas.
La información genética del ADN se transfiere a través de la transcripción a una molécula intermedia llamada ARN. Las señales para iniciar y detener la transcripción se localizan dentro de la secuencia de ADN y se denominan secuencias promotoras y terminadoras. La región codificante de un gen está compuesta por una secuencia de nucleótidos que se transcriben en ARN. Estas secuencias incluyen exones e intrones. Los exones son las secuencias que codifican para las proteínas. La región codificante de un gen contiene exones e intrones. Además, el pre-ARNm contiene tanto intrones como exones. Los intrones en el pre-ARNm se eliminan a través de un proceso llamado corte y empalme de intrones. El ARNm se procesa mediante un remate en 5' y la adición de una cola poli (A).
Actividades de aprendizaje
Dada la siguiente secuencia de ADN bicatenario, predecir la secuencia de la cadena de ARN.
Vea este video: Detalle de transcripción
Un elemento de video ha sido excluido de esta versión del texto. Puedes verlo en línea aquí: https://iastate.pressbooks.pub/genagbiotech/?p=24