
2.5: Nucleótidos
- Page ID
- 53112

Los nucleótidos, los bloques de construcción del ARN y el ADN, están compuestos por un azúcar pentosa unido a una base nitrogenada en un lado y un grupo fosfato en otro. El azúcar es la ribosa de azúcar de 5 carbonos o su primo cercano, la desoxirribosa (el “desoxirribosa” se refiere a un grupo hidroxilo “faltante” en el carbono 2, que en su lugar tiene un H). La base nitrogenada unida puede ser una purina, que es un anillo de 6 miembros fusionado a un anillo de 5 miembros, o una pirimidina, que es un anillo único de 6 miembros. Estas bases suelen ser adenina (purina), guanina (purina), timina (pirimidina) y citosina (pirimidina) por ADN, con una sustitución de uracilo por timina en bases de ARN. Sin embargo, también hay algunas bases poco convencionales y modificadas que aparecen en situaciones especiales, como en los ARNt. Además de ser los componentes monómeros del ADN y ARN, los nucleótidos también tienen otras funciones importantes. El más conocido, el trifosfato de adenosina, o ATP, es la principal fuente de energía “instantánea” para la célula por la energía liberada a través de la hidrólisis de su grupo fosfato terminal.
El ADN o ARN se construyen a partir de nucleótidos a través de enlaces de los azúcares, y la polimerización se produce por reacciones de condensación, pero estos enlaces no son enlaces glicosídicos como con los polisacáridos. En cambio, se forman enlaces entre el grupo fosfato 5' de un nucleótido y el grupo hidroxilo 3' de otro. Estos son enlaces fosfodiéster, y un rápido vistazo a la estructura (Figura\(\PageIndex{8}\)) explica el nombre: un enlace éster es un enlace carbonoxígeno, y el enlace fosfodiéster es un C-O-P-O-C, por lo que hay dos ésteres con un fósforo que los une. Con la base de purina o pirimidina en el 1-carbono, esta disposición coloca las bases en el lado opuesto del azúcar de los enlaces fosfodiéster polimerizantes. Esto forma una cadena principal de azúcar-fosfato al ADN/ARN, que luego tiene las bases que se proyectan fuera de él.
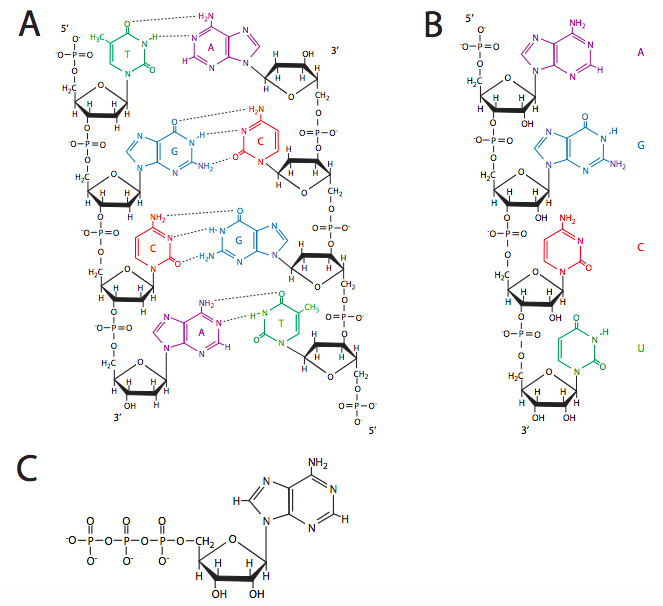
Las bases probablemente interactuarán entonces con las bases de otros nucleótidos, ya sean parte de otra cadena de ácido nucleico o de flotación libre. No solo interactúan, sino que interactúan con gran especificidad y consistencia: las adeninas se emparejan con timinas (o uracilos) a través de dos enlaces de hidrógeno, mientras que las guaninas interactúan con la citosina a través de tres enlaces H. Tenga en cuenta que si bien un enlace de hidrógeno adicional no parece ser particularmente significativo, la atracción entre G-C es 50% más fuerte que entre A-T, y en tramos largos de ADN, las áreas con alto contenido de G-C son significativamente más difíciles de descomprimir (hebras separadas) que las áreas altas en pares A-T. Este emparejamiento de bases específico, conocido como reglas de Chargaff, es la base de la vida: el emparejamiento de bases es necesario para hacer que el ADN sea bicatenario, lo que le da a un organismo una copia de seguridad incorporada de la información genética y también es la base para transformar esa información en proteínas que forman el grueso de una célula.
Los ácidos nucleicos, los polímeros largos de nucleótidos, existen in vitro en formas monocatenarias o bicatenarias. Sin embargo, en la célula, la mayor parte del ARN es monocatenario y la mayor parte del ADN es bicatenario. Esta diferencia es importante para su función: el ARN es una molécula temporal de transferencia de información para un gen en particular, el ADN es el repositorio permanente de toda la información genética necesaria para hacer un organismo. Por lo tanto, el ARN necesita ser fácilmente leído, lo que significa que las bases deben ser accesibles y no bloqueadas a una cadena complementaria. Su estabilidad a largo plazo no es particularmente importante porque cuando se hace, generalmente se hacen muchas copias en su momento, y solo se necesita mientras la célula necesita hacer la proteína que codifica. Por el contrario, la misma cadena de ADN se lee una y otra vez para hacer el ARN, y dado que solo hay dos copias de cada cromosoma (un cromosoma es una molécula de ADN monocatenario doble) en una célula, la capacidad de mantener la integridad del ADN es crucial. Debido al emparejamiento de bases, cada hebra de ADN contiene toda la información necesaria para hacer una copia exacta completa de su cadena complementaria.
Por supuesto, el objetivo de la información genética en el ADN es codificar la producción de proteínas que luego puedan llevar a cabo las funciones que definen la vida celular. Algunas de esas funciones, como la replicación del ADN, la regulación génica, la transcripción y la traducción, requieren que las proteínas interactúen con un ácido nucleico. Por lo general, parte del proceso de reconocimiento implica la aposición de una región cargada positivamente de la proteína al ADN (o ARN), que es una molécula muy cargada negativamente, como se esperaba de todos los fosfatos en la cadena principal de azúcar-fosfato. El ARN, pero no el ADN (con algunas excepciones), también puede interactuar consigo mismo mediante apareamiento de bases complementarias. Si un tramo de secuencia de ARN entra en contacto con un tramo de ARN con una secuencia complementaria en la misma molécula, entonces puede ocurrir el apareamiento de bases. Dependiendo del número de nucleótidos entre las áreas complementarias, se pueden formar estructuras secundarias como tallo-y-bucles y horquillas.