
8.1: Introducción a la Transcripción
- Page ID
- 53282

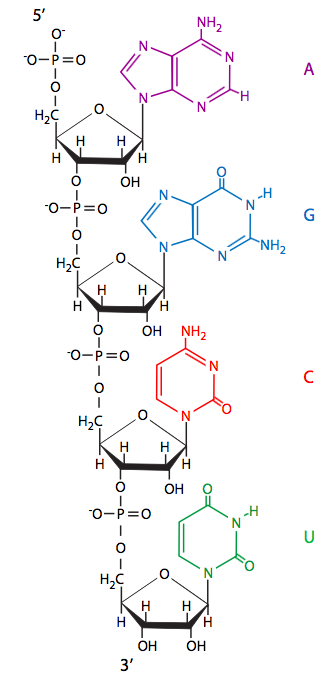
Para obtener la información genética en una forma que sea fácilmente leída y luego utilizada para sintetizar proteínas funcionales, el ADN primero debe transcribirse en ARN (ácido ribonucleico). Como vimos en el capítulo 1, el ARN es extremadamente similar al ADN, utilizando algunas de las mismas bases nitrogenadas (adenina, guanina, citosina) así como una única para el ARN, el uracilo. Observe que el uracilo es muy similar a la timina (capítulo 7, Figura 1), particularmente en la colocación y espaciamiento de los átomos de enlace de hidrógeno. Dado que es la interacción de enlaces de hidrógeno de estas bases (es decir, el apareamiento de bases de guanina a citosina, adenina a timina/uracilo) la que forma la base de la transferencia de información del ADN original al ADN de la célula hija, es lógico esperar que se utilice el mismo tipo de mecanismo de apareamiento de bases para mover el información desde un estado de almacenamiento en el ácido nucleico bicatenario (ADN) hasta un estado más útil/utilizable en forma de un ácido nucleico monocatenario (ARN).
En contraste con su papel celular como portador transitorio y desechable de información genética, se cree que el ARN ha sido la principal molécula responsable de hacer posible la vida en la tierra. Desde hace tiempo se ha postulado que desempeñó funciones duales como depósito de información genética y como enzima rudimentaria para actuar sobre esa información. Desafortunadamente, los químicos prebióticos han sido bloqueados durante décadas en idear una vía sintética razonable por la cual el ARN podría surgir de las moléculas simples de la “sopa” primordial de la tierra. El problema clave era que la ribosa se podía sintetizar, aunque no de manera particularmente eficiente, y las bases podían sintetizarse, pero no había forma de conectarlas entre sí. La química no permitiría una reacción de condensación entre las bases y los azúcares. En 2009, al dejar atrás la idea convencional de que los ribonucleótidos deben haber sido sintetizados a partir de ribosa y purinas/pirimidinas, Powner, Gerland y Sutherland (Nature 459:239-242, 2009) demostraron que, de hecho, los ribonucleótidos podrían sintetizarse a partir de las condiciones químicas de un recién formado tierra. En lugar de intentar hacer cada “parte” y ponerlas juntas, Powner et al sintetizaron una molécula que contenía partes de lo que eventualmente sería tanto la ribosa como una pirimidina, 2-aminooxazol. A través de una serie de reacciones que utilizaron fosfato como catalizador y captador, todas las cuales fueron claramente plausibles en el modelo actual de tierra primordial, se crearon tanto ribocitidina como ribouridina. Por supuesto, esto es sólo el comienzo, ya que esto no se extiende directamente a la formación de nucleótidos de purina, sino que es un paso muy significativo en la química prebiótica, y un excelente ejemplo de las virtudes de “salir de la caja” a veces.
El proceso de copiar ADN en ARN se llama transcripción. Tanto en procariotas como en eucariotas, la transcripción requiere de ciertos elementos de control (secuencias de nucleótidos dentro del ADN) para proceder adecuadamente. Estos elementos son un promotor, un sitio de inicio y un sitio de parada. La necesidad de un punto reconocible para comenzar y un punto para terminar el proceso es bastante obvia. El promotor es algo diferente. El promotor controla la frecuencia de transcripción. Si imaginas las necesidades de una célula en un momento dado, claramente no todos los productos génicos son necesarios en la misma cantidad al mismo tiempo. Debe haber una manera de controlar cuándo o si se produce la transcripción, y a qué velocidad.
La versión básica del proceso es algo como esto: (1) las proteínas especiales de acoplamiento reconocen la secuencia promotora y se unen a ella, desenrollando una pequeña sección alrededor del sitio de “inicio”; (2) la ARN polimerasa se une a esas proteínas especiales y al poco ADN monocatenario que acaba de abrirse; ( 3) una enzima helicasa (parte de, o unida a la polimerasa) desbloquea el ADN; (4) la ARN polimerasa sigue detrás de la helicasa, “leyendo” la secuencia de ADN, tomando ribonucleótidos del ambiente, emparejándolos con el molde de ADN, y si coinciden, agregándolos al ribonucleótido o ARN anterior cadena. Esto continúa hasta que la polimerasa alcanza el sitio de parada, momento en el cual, se desprende del ADN molde, liberando también la copia de ARN recién hecha de ese ADN. Por supuesto, si eso fuera todo lo que había para ello, no habría revistas enteras dedicadas a estudiar el ARN, su transcripción, y el control de esa transcripción.
La secuencia del promotor está directamente relacionada con su función. Puede haber promotores para genes domésticos (necesarios constantemente, pero con un número de copias bajo), genes “normales” (necesarios según lo dicte la situación de la célula, la tasa de transcripción también varía), genes de respuesta al estrés (raramente se necesitan) y una variedad de otras categorías. Incluso dentro de una categoría, la secuencia del promotor determina su fuerza. Esto se basa en lo que se conoce como la “secuencia consenso”. La secuencia consenso es un promotor teórico “mejor” basado en una encuesta de todos los genes en una categoría particular. La siguiente figura muestra un alineamiento de las secuencias promotoras de una variedad de genes diferentes, todos los cuales están regulados por el mismo tipo de promotor y proteína de unión al promotor. Los recuadros resaltados muestran áreas centradas alrededor de -35 (35 nucleótidos aguas arriba del sitio de inicio) y -10.
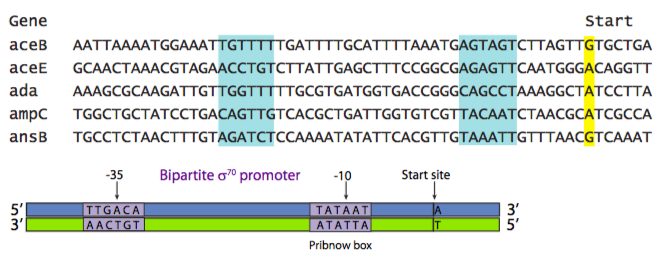
La secuencia consenso en la Figura\(\PageIndex{2}\) muestra el nucleótido más común encontrado en cada posición dentro de esas áreas de similitud. En este ejemplo se muestra el promotor procariota más común: el promotor σ 70, llamado así porque es reconocido y unido por el factor de transcripción σ 70. [Aquí, y por convención universalmente aceptada, las secuencias de reconocimiento de ADN se escriben como los nucleótidos ocurrirían de 5' a 3' en la cadena sentido o no molde.] Es un promotor de dos partes, con una región centrada alrededor de -35 (consenso TTGACA), y una región (a veces llamada Pribnow box, consenso TATAAT) centrada alrededor de -10. El signo (-) indica que el nucleótido está “aguas arriba” del sitio de inicio. Aguas arriba significa “a la izquierda” cuando los nucleótidos se escriben como una cadena de letras, y significa “en el lado 5' de” con respecto a la direccionalidad 5'-3' de una cadena de ADN. Observe la relación entre los diversos promotores individuales y la secuencia consensuada. En general, aquellos promotores con más coincidencias con la secuencia consenso son promotores más fuertes.
Hace unos párrafos, la tarea del promotor se definió como controlar la frecuencia de transcripción. ¿Cómo hace eso? ¿Qué significa ser un promotor más fuerte (o más débil)? En primer lugar, hay que tener en cuenta que la expresión de cualquier gen dado no es automática, o 100%. En cualquier momento, muchos de los genes de una célula estarán cerca del 0%, o se apagarán. Sin embargo, incluso los genes que se encienden se transcriben a diferentes velocidades. Uno de los factores gobernantes es el reconocimiento del sitio promotor por la ARN Polimerasa. Para promotores más fuertes, es más probable que la ARN polimerasa reconozca el sitio, se acople correctamente, abra la doble hélice y comience a transcribir. Por otro lado, la ARN polimerasa puede reconocer potencialmente promotores más débiles, pero es menos probable que lo haga, en lugar de pasarlo como solo otro tramo sin importancia de ADN. Si bien esto es parcialmente una cuestión de reconocimiento por parte de la polimerasa, hay que tener en cuenta que en realidad se rige por el reconocimiento de la secuencia promotora por los factores generales de transcripción (que se discutirán en breve) como los factores sigma en procariotas que son reconocidos por la polimerasa.
Observe que existe una alta proporción de (A) deninos y (T) himnos en las secuencias promotoras σ 70. Esto es cierto para muchos promotores tanto en genes procariotas como eucariotas. Como probablemente sospechaste, esto es ventajoso porque solo hay dos enlaces H entre pares A-T (a diferencia de 3 enlaces H entre pares G-C), lo que significa que es 33% más fácil de descomprimir.