
14.2: La complejidad del ADN genómico
- Page ID
- 54277

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Para la década de 1960, cuando Roy Britten y Eric Davidson estudiaban la regulación de genes eucariotas, sabían que había ADN más que suficiente para dar cuenta de los genes necesarios para codificar un organismo. También era probable que el ADN fuera más complejo estructuralmente de lo que se pensaba originalmente. Sabían que la centrifugación por gradiente de densidad de cloruro de cesio (CsCl) separaba las moléculas en función de las diferencias de densidad y que el ADN fragmentado se separaría en una banda principal y una banda menor de diferente densidad en tubo de centrífuga. La banda menor fue apodada ADN satelital, recordando el satélite Sputnik lanzado recientemente por Rusia. Bandas de ADN de diferente densidad no podrían existir si las proporciones de A, G, T y C en el ADN (ya conocidas como específicas de especie) fueran las mismas en todo el genoma. En cambio, debe haber regiones de ADN que sean más ricas en pares A-T que G-C y viceversa. El análisis de las bandas satelitales que se movieron más en el gradiente (es decir, fueron más densas) que la banda principal fueron de hecho más ricas en contenido de GC. Los que estaban por encima de la banda principal eran más ricos en AT.
Considera estimaciones tempranas de cuántos genes se necesitan para hacer un ser humano, ratón, pollo o petunia: ¡alrededor de 100.000! ¡Sabemos ahora que se necesita menos! Sin embargo, incluso con estimaciones infladas del número de genes que se necesitan para hacer un eucariota típico, sus genomas contienen 100-1000 veces más ADN del necesario para dar cuenta de 100,000 genes. ¿Cómo entonces explicar este ADN extra? Los elegantes experimentos de cinética de renaturalización de Britten y Davidson revelaron algunas características físicas de los genes y el llamado ADN 'extra'. Veamos estos experimentos con cierto detalle.
A. El protocolo cinético de renaturalización
El primer paso en un experimento cinético de renaturalización es cizallar los aislados de ADN a un tamaño promedio de 10 Kbp empujando ADN de alto peso molecular a través de una aguja hipodérmica a presión constante. Los fragmentos bicatenarios resultantes (ADNbc) se calientan luego a 100 o C para desnaturalizar (separar) las dos cadenas. Luego, las soluciones se enfrían a 600C para permitir que los fragmentos de ADN monocatenario (ADNmc) vuelvan a formar lentamente cadenas dobles complementarias. En diferentes momentos después de la incubación a 60oC, se muestreó el ADN parcialmente renaturalizado y se separaron y cuantificaron ssDNA y dsDNA.
El experimento se resume en el siguiente dibujo.
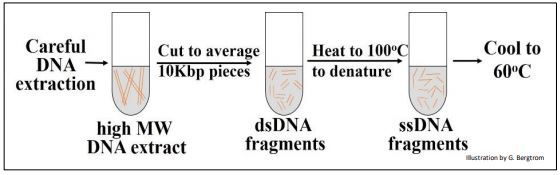
Se podría graficar la cantidad, o porcentaje de ADN que se había renaturalizado con el tiempo.
B. Datos cinéticos de renaturalización
Se formó una parcela de ADNbc en diferentes momentos (¡a muchos días!) se muestra a continuación para un experimento de cinética de renaturalización usando ADN de rata.
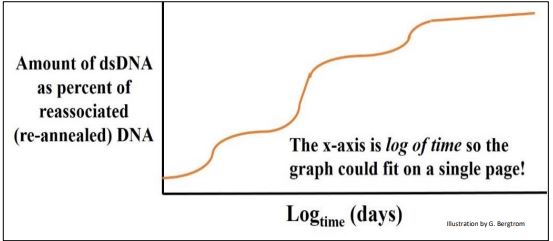
En este ejemplo, los fragmentos de ADN podrían colocarse en tres grupos principales con diferentes tasas globales de renaturalización. Britten y Davidson razonaron que el ADNbc que se había formado más rápidamente estaba compuesto por secuencias que debían ser más repetitivas que el resto del ADN. El genoma de la rata también tuvo una menor cantidad de fragmentos de ADNbc más moderadamente repetidos que tardaron más en hibridarse que la fracción altamente repetitiva, e incluso menos de una fracción de ADN de rehibridación muy lenta. Estas últimas secuencias fueron tan raras en el extracto que podrían tardar días en volver a formar cadenas dobles, y se clasificaron como ADN de secuencia no repetitiva, única (o casi única), como se ilustra a continuación.
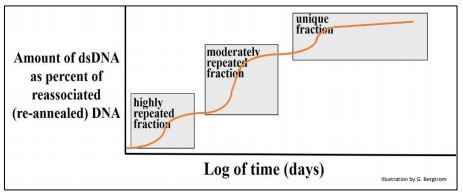
Quedó claro que el genoma de la rata (de hecho la mayoría de los genomas eucariotas) consiste en diferentes clases de ADN que difieren en su redundancia. De la gráfica, sorprendentemente una gran fracción del genoma fue repetitiva en mayor o menor medida.
238 Descubrimiento de ADN Repetitivo
Cuando se determinó la cinética de renaturalización para el ADN de E. coli, solo se observó una 'clase redundante' de ADN, como se muestra a continuación.
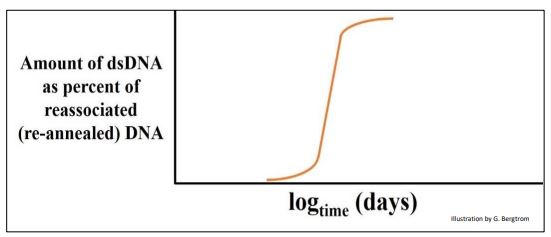
Con base en estudios de mapeo de genes de E. coli y el pequeño tamaño del 'cromosoma' de E. coli, la suposición razonable fue que hay poco espacio para ADN 'extra' en un genoma bacteriano, y que la clase única de ADN en esta parcela debe ser ADN de secuencia única.
C. Complejidad genómica
Britten y Davidson definieron las cantidades relativas de secuencias de ADN repetidas y únicas (o de una sola copia) en el genoma de un organismo como su complejidad genómica. Así, los genomas procariotas tienen una complejidad genómica menor que los eucariotas. Utilizando los mismos datos que en las dos gráficas anteriores, Britten y Davidson demostraron la diferencia entre la complejidad del genoma eucariota y procariota por un simple recurso. En lugar de trazar la fracción de ADNbc formada frente al tiempo de renaturalización, trazaron el porcentaje de ADN reasociado frente a la concentración del ADN renaturalizado multiplicada por el tiempo que el ADN tardó en volver a hibridarse (el valor CoT). Cuando los valores de CoT de los datos de renaturalización de rata y E. coli se trazan en la misma gráfica, se obtienen las curvas de CoT en la gráfica de abajo.
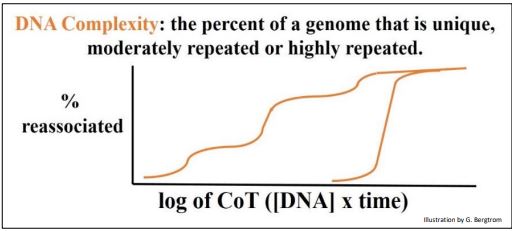
Este cálculo extra engañosamente simple (¡a partir de los mismos datos!) permite comparar las complejidades de cualquier número de genomas. Estas curvas CoT nos dicen que ~ 100% del genoma bacteriano consiste en secuencias únicas, en comparación con el genoma de rata con sus tres clases de redundancia de ADN. Los genomas procariotas están compuestos en gran parte de ADN de secuencia única (no repetitiva) que debe incluir genes de copia única (u operones) que codifican proteínas, ARN ribosómicos y ARN de transferencia.
D. Diferencias funcionales entre las clases CoT de ADN
La siguiente pregunta, por supuesto, ¿qué tipo de secuencias se repiten y cuáles son 'únicas' en el ADN eucariota? Los ADN satélite eucariotas, los transposones y los genes de ARN ribosómico fueron los primeros sospechosos. Para comenzar a responder a estas preguntas, el ADN satelital se aisló de los gradientes de CsCl, se hizo radiactivo y luego se calentó para separar las cadenas de ADN. En un experimento cinético de renaturalización separado, se muestreó el ADN de rata en diferentes momentos. Las fracciones de Cot aisladas se desnaturalizaron nuevamente y se mezclaron con ADN satélite radiactivo desnaturalizado por calor. Después, la mezcla se enfrió para permitir la renaturalización. A continuación se ilustra el protocolo experimental.
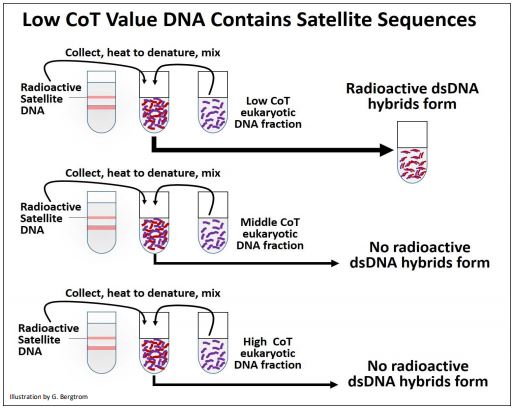
Los resultados de este experimento mostraron que el ADN satélite radiactivo solo se hibridó con el ADN de la fracción Cot baja (altamente repetida) fracción de ADN. El ADN satélite es así altamente repetido en el genoma eucariota. En experimentos similares, los ARNr aislados produjeron híbridos de ARN-ADN formados radiactivos cuando se mezclaron y enfriaron con la fracción CoT media desnaturalizada del ADN eucariota. Así, los genes rRNA fueron moderadamente repetitivos. Con el advenimiento de las tecnologías de ADN recombinante, se exploró la redundancia de otros tipos de ADN utilizando genes clonados (que codifican ARNr, proteínas, transposones y otras secuencias) para sondear fracciones de ADN obtenidas de experimentos de cinética de renaturalización. Los resultados de dichos experimentos se resumen en la siguiente tabla.
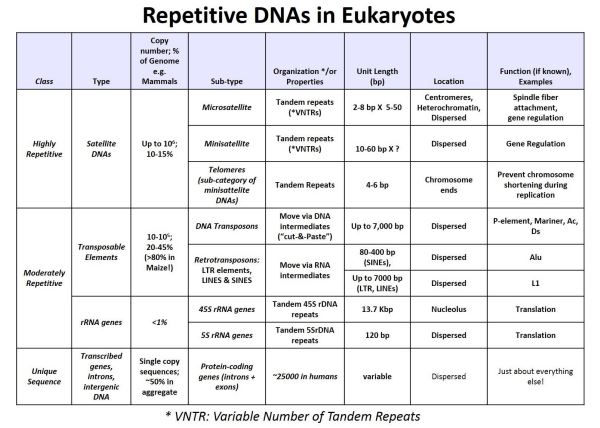
En la tabla se comparan las propiedades (longitudes, número de copias, funciones, porcentaje del genoma, ubicación en el genoma, etc.) de diferentes tipos de ADN de secuencia repetitiva. ¡La observación de que la mayor parte de un genoma eucariota está compuesto por ADN repetido, y que los transposones pueden ser hasta el 80% de un genoma fue una sorpresa!
240 Identificación de diferentes tipos de ADN en cada fracción de CoT
241 Algunas funciones repetitivas del ADN
A continuación nos centraremos en los diferentes tipos de elementos transponibles