Espero que ahora quede claro que el filtrado funciona reemplazando cada punto en la forma de onda con una copia escalada de la función de respuesta al impulso. Sin embargo, probablemente no sea obvio por qué esto termina filtrando las frecuencias altas. Hay una forma de pensar ligeramente diferente —pero matemáticamente equivalente— sobre el filtrado que lo hace más obvio.
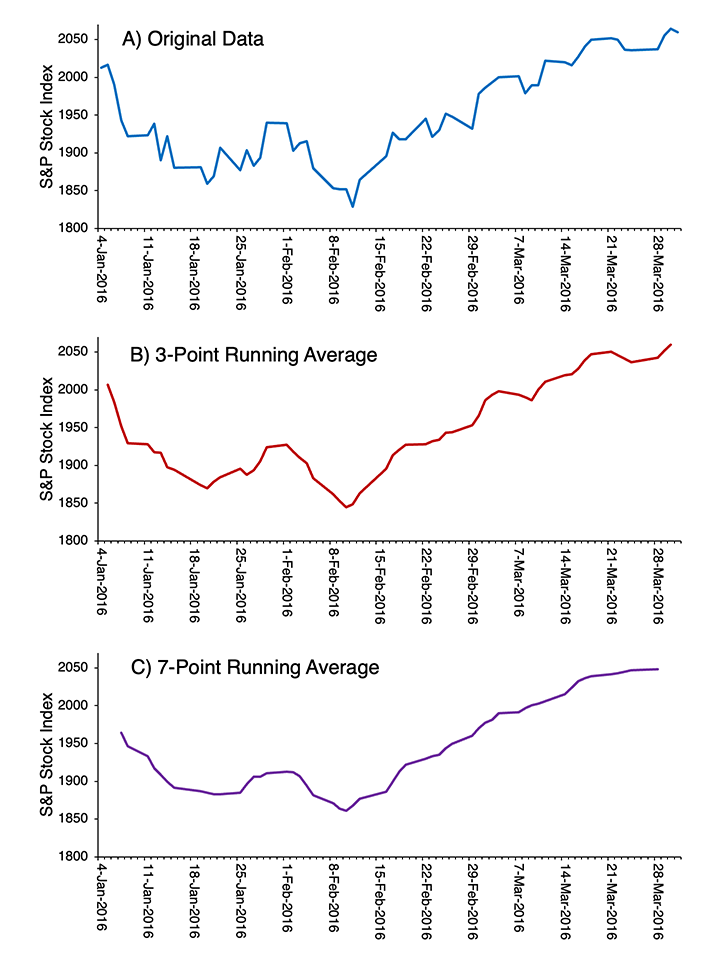
Empecemos olvidando todo lo que sabes sobre EEG y filtrado, y en su lugar pensemos en los precios bursátiles. La Figura 4.2.A muestra los valores diarios del índice bursátil Standard & Poor 500 durante un periodo de 3 meses. Hay muchas variaciones del día a día que son en gran parte aleatorias y no significan mucho para la economía en general. ¿Cuál sería una manera fácil de minimizar estas fluctuaciones del día a día para que puedas visualizar mejor la tendencia general?
Figura 4.2. A) Valores diarios del índice bursátil Standard & Poor 500 entre el 4 de enero y el 31 de marzo de 2016. B) Valores después de aplicar un promedio lineal de 3 puntos. C) Valores después de aplicar un promedio lineal de 7 puntos.
Un enfoque común es tomar un promedio corriente. La Figura 4.2.B muestra un promedio lineal de 3 puntos de los valores de la Figura 4.2.A. Cada valor para un día determinado en el promedio corriente es solo el promedio de los valores del día anterior, ese día y el día siguiente. Por ejemplo, el valor promedio corriente del 2 de febrero es el promedio de los valores del 1, 2 y 3 de febrero. Se puede ver que el promedio de funcionamiento es más suave que los datos originales.
Podemos hacer que los datos sean aún más fluidos con un promedio de funcionamiento de 7 días (Figura 4.2.C). Ahora, el promedio corriente para un día determinado es el promedio del valor en ese día, los tres días anteriores y los tres días posteriores. Cuantos más puntos incluyamos en nuestra media corriente, más atenuamos los cambios rápidos del día a día y vemos las tendencias más lentas en los datos. Es decir, al aumentar el número de puntos en la media corriente se incrementa el filtrado de altas frecuencias en los datos. Entonces, tomar un promedio corriente es una forma simple de filtrado paso bajo, y podemos controlar la frecuencia de corte cambiando el número de puntos que se promedian juntos. Podemos aplicar este mismo algoritmo para filtrar altas frecuencias en el EEG o en los ERPs (ver Capítulo 7 en Suerte, 2014 para más detalles).
Artefactos de borde
El enfoque de promedio corriente para el filtrado expone un problema que siempre enfrentamos en el filtrado, sin importar qué algoritmo usemos. Los valores del índice S&P 500 mostrados en la Figura 4.2.A comienzan el 4 de enero y terminan el 31 de marzo. Para calcular el valor promedio de 3 puntos para el 4 de enero, necesitaríamos valores para el 3, 4 y 5 de enero, pero no tenemos el valor para el 3 de enero. De igual manera, no podemos calcular el valor promedio corriente para el 31 de marzo porque no tenemos el valor para el 1 de abril. Las cosas son aún peores para el promedio de carrera de 7 puntos porque ahora necesitamos 3 días antes y 3 días después de un día determinado. Como resultado, no podemos calcular el promedio corriente para el 4, 5 o 6 de enero o para el 29, 30 o 31 de marzo con los datos que tenemos disponibles. Se puede ver que estos puntos faltan en los promedios corrientes en la Figura 4.2.
Este problema es menos obvio cuando filtramos usando funciones de respuesta de impulso o la transformada de Fourier, pero el mismo problema está presente para todos los algoritmos de filtrado. Resolvemos este problema en ERPLAB utilizando un algoritmo de extrapolación para estimar los valores para los puntos que son necesarios pero no disponibles. Funciona bastante bien en la mayoría de los casos, pero puede generar problemas cuando hay que extrapolar demasiados puntos. La situación más común donde eso surge es cuando usamos un filtro de paso alto para filtrar las bajas frecuencias del EEG continuo, lo que requiere una cantidad muy grande de puntos antes y después del punto actual. En esta situación, a veces vemos “artefactos de borde” al principio y al final de las formas de onda del EEG. Para evitar estos artefactos de borde, recomiendo registrar ~10 segundos adicionales de datos antes del primer estímulo al inicio de cada bock de ensayo y otros ~10 segundos después del último estímulo al final de cada bloque de prueba. De esa manera, los bordes de las formas de onda están lejos del período de tiempo que te importa, y los artefactos de borde ocurren durante un período de tiempo que está fuera de las épocas que usarás para promediar.
Además, la herramienta de filtrado de ERPLAB tiene una opción que puede ayudar a reducir los artefactos de borde. Esta opción está etiquetada como “Eliminar valor medio (desplazamiento de CC) antes de filtrar”. Normalmente se debe usar cuando se están filtrando datos EEG continuos. Sin embargo, no debe usarse para datos corregidos por la línea de base (por ejemplo, EEG de época o ERPs promediados) porque la corrección de línea de base ya elimina el desplazamiento de CC (y normalmente funciona mejor que eliminar el valor medio).