
15.9: Comprobación del modelo
- Page ID
- 151886

El foco principal de esta sección es el diagnóstico de regresión, término que se refiere al arte de verificar que se hayan cumplido los supuestos de tu modelo de regresión, averiguar cómo arreglar el modelo si se violan los supuestos, y en general verificar que nada “gracioso” está pasando. Me refiero a esto como el “arte” de verificar modelos con buena razón: no es fácil, y si bien hay muchas herramientas bastante estandarizadas que puedes usar para diagnosticar y tal vez incluso curar los problemas que le afectan a tu modelo (¡si hay alguna, eso es!) , realmente necesitas ejercer una cierta cantidad de juicio al hacer esto. Es fácil perderse en todos los detalles de revisar esta cosa o esa cosa, y es bastante agotador tratar de recordar cuáles son todas las cosas diferentes. Esto tiene el efecto secundario muy desagradable de que mucha gente se frustra al tratar de aprender todas las herramientas, así que en su lugar deciden no hacer ninguna comprobación de modelo. ¡Esto es un poco de preocupación!
En esta sección, describo varias cosas diferentes que puedes hacer para comprobar que tu modelo de regresión está haciendo lo que se supone que debe hacer. No cubre todo el espacio de cosas que podrías hacer, pero sigue siendo mucho más detallado que lo que veo que mucha gente hace en la práctica; y no suelo cubrir todo esto en mi clase de estadísticas introductorias yo mismo. No obstante, sí creo que es importante que tengas una idea de qué herramientas están a tu disposición, así que voy a tratar de presentarles un montón de ellas aquí. Por último, debo señalar que esta sección se basa bastante en el texto de Fox y Weisberg (2011), el libro asociado con el paquete del automóvil. El paquete de autos es notable por proporcionar algunas herramientas excelentes para el diagnóstico de regresión, y el libro en sí habla de ellos de una manera admirablemente clara. No quiero sonar demasiado efusivo al respecto, pero sí creo que bien merece la pena leer Fox y Weisberg (2011).
Tres tipos de residuos
La mayoría de los diagnósticos de regresión giran en torno a mirar los residuales, y a estas alturas probablemente ya hayas formado una teoría de la estadística lo suficientemente pesimista para poder adivinar que —precisamente por el hecho de que nos importan mucho los residuos— hay varios diferentes tipos de residuos que podríamos considerar. En particular, en esta sección se hace referencia a los siguientes tres tipos de residuos: “residuos ordinarios”, “residuales normalizados” y “Residuales Studentised”. Hay un cuarto tipo al que verán referidos en algunas de las Figuras, y ese es el “residual de Pearson”: sin embargo, para los modelos de los que estamos hablando en este capítulo, el residual de Pearson es idéntico al residual ordinario.
El primer y más simple tipo de residuos que nos importan son los residuales ordinarios. Estos son los residuos reales, brutos de los que he estado hablando a lo largo de este capítulo. El residuo ordinario es solo la diferencia entre el valor ajustado\(\ \hat{Y_i}\) y el valor observado Y i. He estado usando la notación i para referirme al i-ésimo residual ordinario, y por goma me voy a apegar a él. Con esto en mente, tenemos la ecuación muy simple
\(\ \epsilon_i = Y_i - \hat{Y_i}\)
Esto es por supuesto lo que vimos antes, y a menos que me refiera específicamente a algún otro tipo de residuo, este es de lo que estoy hablando. Entonces no hay nada nuevo aquí: solo quería repetirme. En cualquier caso, puede obtener R para generar un vector de residuos ordinarios, puede usar un comando como este:
residuals( object = regression.2 )## 1 2 3 4 5 6
## -2.1403095 4.7081942 1.9553640 -2.0602806 0.7194888 -0.4066133
## 7 8 9 10 11 12
## 0.2269987 -1.7003077 0.2025039 3.8524589 3.9986291 -4.9120150
## 13 14 15 16 17 18
## 1.2060134 0.4946578 -2.6579276 -0.3966805 3.3538613 1.7261225
## 19 20 21 22 23 24
## -0.4922551 -5.6405941 -0.4660764 2.7238389 9.3653697 0.2841513
## 25 26 27 28 29 30
## -0.5037668 -1.4941146 8.1328623 1.9787316 -1.5126726 3.5171148
## 31 32 33 34 35 36
## -8.9256951 -2.8282946 6.1030349 -7.5460717 4.5572128 -10.6510836
## 37 38 39 40 41 42
## -5.6931846 6.3096506 -2.1082466 -0.5044253 0.1875576 4.8094841
## 43 44 45 46 47 48
## -5.4135163 -6.2292842 -4.5725232 -5.3354601 3.9950111 2.1718745
## 49 50 51 52 53 54
## -3.4766440 0.4834367 6.2839790 2.0109396 -1.5846631 -2.2166613
## 55 56 57 58 59 60
## 2.2033140 1.9328736 -1.8301204 -1.5401430 2.5298509 -3.3705782
## 61 62 63 64 65 66
## -2.9380806 0.6590736 -0.5917559 -8.6131971 5.9781035 5.9332979
## 67 68 69 70 71 72
## -1.2341956 3.0047669 -1.0802468 6.5174672 -3.0155469 2.1176720
## 73 74 75 76 77 78
## 0.6058757 -2.7237421 -2.2291472 -1.4053822 4.7461491 11.7495569
## 79 80 81 82 83 84
## 4.7634141 2.6620908 -11.0345292 -0.7588667 1.4558227 -0.4745727
## 85 86 87 88 89 90
## 8.9091201 -1.1409777 0.7555223 -0.4107130 0.8797237 -1.4095586
## 91 92 93 94 95 96
## 3.1571385 -3.4205757 -5.7228699 -2.2033958 -3.8647891 0.4982711
## 97 98 99 100
## -5.5249495 4.1134221 -8.2038533 5.6800859Un inconveniente del uso de residuos ordinarios es que siempre están en una escala diferente, dependiendo de cuál sea la variable de resultado y qué tan bueno sea el modelo de regresión. Es decir, a menos que hayas decidido ejecutar un modelo de regresión sin término de intercepción, los residuales ordinarios tendrán media 0; pero la varianza es diferente para cada regresión. En muchos contextos, especialmente donde solo te interesa el patrón de los residuos y no sus valores reales, es conveniente estimar los residuos estandarizados, que se normalizan de tal manera que tengan desviación estándar 1. La forma en que calculamos estos es dividiendo el residuo ordinario por una estimación de la desviación estándar (poblacional) de estos residuos. Por razones técnicas, murmullo murmullo, la fórmula para esto es:
\(\epsilon_{i}^{\prime}=\dfrac{\epsilon_{i}}{\hat{\sigma} \sqrt{1-h_{i}}}\)
donde\(\ \hat{\sigma}\) en este contexto se encuentra la desviación estándar poblacional estimada de los residuos ordinarios, y h i es el “valor hat” de la i-ésima observación. Aún no te he explicado los valores del sombrero (pero no tengas miedo, 220 viene en breve), así que esto no tendrá mucho sentido. Por ahora, basta con interpretar los residuos estandarizados como si hubiéramos convertido los residuales ordinarios a puntuaciones z. De hecho, esa es más o menos la verdad, es solo que estamos siendo un poco más elegantes. Para obtener los residuos estandarizados, el comando que desea es el siguiente:
rstandard( model = regression.2 )## 1 2 3 4 5 6
## -0.49675845 1.10430571 0.46361264 -0.47725357 0.16756281 -0.09488969
## 7 8 9 10 11 12
## 0.05286626 -0.39260381 0.04739691 0.89033990 0.95851248 -1.13898701
## 13 14 15 16 17 18
## 0.28047841 0.11519184 -0.61657092 -0.09191865 0.77692937 0.40403495
## 19 20 21 22 23 24
## -0.11552373 -1.31540412 -0.10819238 0.62951824 2.17129803 0.06586227
## 25 26 27 28 29 30
## -0.11980449 -0.34704024 1.91121833 0.45686516 -0.34986350 0.81233165
## 31 32 33 34 35 36
## -2.08659993 -0.66317843 1.42930082 -1.77763064 1.07452436 -2.47385780
## 37 38 39 40 41 42
## -1.32715114 1.49419658 -0.49115639 -0.11674947 0.04401233 1.11881912
## 43 44 45 46 47 48
## -1.27081641 -1.46422595 -1.06943700 -1.24659673 0.94152881 0.51069809
## 49 50 51 52 53 54
## -0.81373349 0.11412178 1.47938594 0.46437962 -0.37157009 -0.51609949
## 55 56 57 58 59 60
## 0.51800753 0.44813204 -0.42662358 -0.35575611 0.58403297 -0.78022677
## 61 62 63 64 65 66
## -0.67833325 0.15484699 -0.13760574 -2.05662232 1.40238029 1.37505125
## 67 68 69 70 71 72
## -0.28964989 0.69497632 -0.24945316 1.50709623 -0.69864682 0.49071427
## 73 74 75 76 77 78
## 0.14267297 -0.63246560 -0.51972828 -0.32509811 1.10842574 2.72171671
## 79 80 81 82 83 84
## 1.09975101 0.62057080 -2.55172097 -0.17584803 0.34340064 -0.11158952
## 85 86 87 88 89 90
## 2.10863391 -0.26386516 0.17624445 -0.09504416 0.20450884 -0.32730740
## 91 92 93 94 95 96
## 0.73475640 -0.79400855 -1.32768248 -0.51940736 -0.91512580 0.11661226
## 97 98 99 100
## -1.28069115 0.96332849 -1.90290258 1.31368144Tenga en cuenta que esta función usa un nombre diferente para el argumento de entrada, pero sigue siendo solo un objeto de regresión lineal que la función quiere tomar como entrada aquí.
El tercer tipo de residuos son residuos Studentised (también llamados “residuos jackknifed”) e incluso son más elegantes que los residuales estandarizados. Nuevamente, la idea es tomar el residuo ordinario y dividirlo por alguna cantidad para estimar alguna noción estandarizada del residuo, pero la fórmula para hacer los cálculos esta vez es sutilmente diferente:
\(\epsilon_{i}^{*}=\dfrac{\epsilon_{i}}{\hat{\sigma}_{(-i)} \sqrt{1-h_{i}}}\)
Observe que nuestra estimación de la desviación estándar aquí está escrita\(\ \hat{\sigma_{-i}}\). A lo que esto corresponde es la estimación de la desviación estándar residual que habría obtenido, si acaba de eliminar la i-ésima observación del conjunto de datos. Esto suena como el tipo de cosas que sería una pesadilla de calcular, ya que parece estar diciendo que hay que ejecutar N nuevos modelos de regresión (incluso una computadora moderna podría quejarse un poco en eso, especialmente si tienes un conjunto de datos grande). Afortunadamente, alguna persona terriblemente inteligente ha demostrado que esta estimación de desviación estándar en realidad viene dada por la siguiente ecuación:
\(\hat{\sigma}_{(-i)}=\hat{\sigma} \sqrt{\dfrac{N-K-1-\epsilon_{i}^{\prime 2}}{N-K-2}}\)
¿No es eso un pip? De todos modos, el comando que usarías si quisieras sacar los residuos Studentised para nuestro modelo de regresión es
rstudent( model = regression.2 )## 1 2 3 4 5 6
## -0.49482102 1.10557030 0.46172854 -0.47534555 0.16672097 -0.09440368
## 7 8 9 10 11 12
## 0.05259381 -0.39088553 0.04715251 0.88938019 0.95810710 -1.14075472
## 13 14 15 16 17 18
## 0.27914212 0.11460437 -0.61459001 -0.09144760 0.77533036 0.40228555
## 19 20 21 22 23 24
## -0.11493461 -1.32043609 -0.10763974 0.62754813 2.21456485 0.06552336
## 25 26 27 28 29 30
## -0.11919416 -0.34546127 1.93818473 0.45499388 -0.34827522 0.81089646
## 31 32 33 34 35 36
## -2.12403286 -0.66125192 1.43712830 -1.79797263 1.07539064 -2.54258876
## 37 38 39 40 41 42
## -1.33244515 1.50388257 -0.48922682 -0.11615428 0.04378531 1.12028904
## 43 44 45 46 47 48
## -1.27490649 -1.47302872 -1.07023828 -1.25020935 0.94097261 0.50874322
## 49 50 51 52 53 54
## -0.81230544 0.11353962 1.48863006 0.46249410 -0.36991317 -0.51413868
## 55 56 57 58 59 60
## 0.51604474 0.44627831 -0.42481754 -0.35414868 0.58203894 -0.77864171
## 61 62 63 64 65 66
## -0.67643392 0.15406579 -0.13690795 -2.09211556 1.40949469 1.38147541
## 67 68 69 70 71 72
## -0.28827768 0.69311245 -0.24824363 1.51717578 -0.69679156 0.48878534
## 73 74 75 76 77 78
## 0.14195054 -0.63049841 -0.51776374 -0.32359434 1.10974786 2.81736616
## 79 80 81 82 83 84
## 1.10095270 0.61859288 -2.62827967 -0.17496714 0.34183379 -0.11101996
## 85 86 87 88 89 90
## 2.14753375 -0.26259576 0.17536170 -0.09455738 0.20349582 -0.32579584
## 91 92 93 94 95 96
## 0.73300184 -0.79248469 -1.33298848 -0.51744314 -0.91435205 0.11601774
## 97 98 99 100
## -1.28498273 0.96296745 -1.92942389 1.31867548Antes de seguir adelante, debo señalar que a menudo no es necesario extraer manualmente estos residuos usted mismo, a pesar de que están en el centro de casi todos los diagnósticos de regresión. Es decir, las funciones residuales (), rstandard () y rstudent () son todas útiles de conocer, pero la mayoría de las veces las diversas funciones que ejecutan los diagnósticos se encargarán de estos cálculos por usted. Aun así, siempre es agradable saber cómo hacerse con estas cosas usted mismo en caso de que alguna vez necesite hacer algo no estándar.
Tres tipos de datos anómalos
Un peligro con el que puede encontrarse con los modelos de regresión lineal es que su análisis pueda ser desproporcionadamente sensible a un número pequeño de observaciones “inusuales” o “anómalas”. Ya discutí esta idea anteriormente en la Sección 6.5.2 en el contexto de discutir los valores atípicos que se identifican automáticamente por la función boxplot (), pero esta vez necesitamos ser mucho más precisos. En el contexto de la regresión lineal, existen tres formas conceptualmente distintas en las que una observación podría llamarse “anómala”. Los tres son interesantes, pero tienen implicaciones bastante diferentes para su análisis.
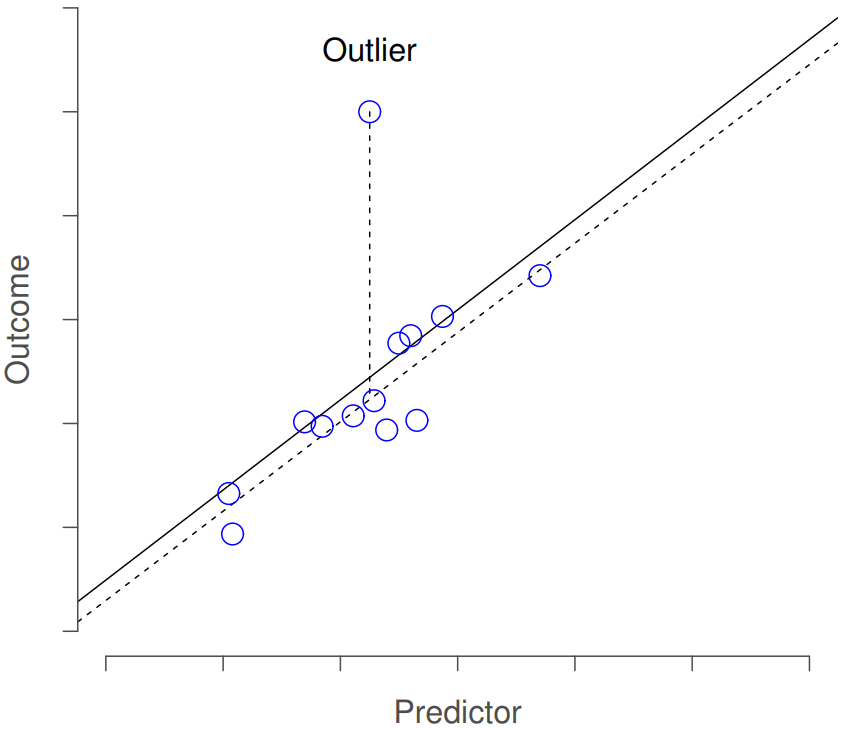
El primer tipo de observación inusual es un valor atípico. La definición de un valor atípico (en este contexto) es una observación que es muy diferente a lo que predice el modelo de regresión. Un ejemplo se muestra en la Figura 15.7. En la práctica, operacionalizamos este concepto diciendo que un valor atípico es una observación que tiene un residuo Studentised muy grande,\(\ {\epsilon_i}^*\). Los valores atípicos son interesantes: un gran valor atípico podría corresponder a datos basura, por ejemplo, las variables podrían haberse ingresado incorrectamente o algún otro defecto puede ser detectable. Ten en cuenta que no debes tirar una observación solo porque es un valor atípico. Pero el hecho de que sea un valor atípico suele ser una señal para mirar más de cerca ese caso, y tratar de averiguar por qué es tan diferente.
La segunda forma en que una observación puede ser inusual es si tiene un alto apalancamiento: esto sucede cuando la observación es muy diferente de todas las demás observaciones. Esto no necesariamente tiene que corresponder a un residuo grande: si la observación resulta inusual en todas las variables precisamente de la misma manera, en realidad puede estar muy cerca de la línea de regresión. Un ejemplo de esto se muestra en la Figura 15.8. El apalancamiento de una observación se opera en términos de su valor hat, generalmente escrito hi. La fórmula para el valor hat es bastante complicada 221 pero su interpretación no es: h i es una medida del grado en que la observación i-ésima está “en control” de donde termina yendo la línea de regresión. Puede extraer los valores hat usando el siguiente comando:
hatvalues( model = regression.2 )## 1 2 3 4 5 6
## 0.02067452 0.04105320 0.06155445 0.01685226 0.02734865 0.03129943
## 7 8 9 10 11 12
## 0.02735579 0.01051224 0.03698976 0.01229155 0.08189763 0.01882551
## 13 14 15 16 17 18
## 0.02462902 0.02718388 0.01964210 0.01748592 0.01691392 0.03712530
## 19 20 21 22 23 24
## 0.04213891 0.02994643 0.02099435 0.01233280 0.01853370 0.01804801
## 25 26 27 28 29 30
## 0.06722392 0.02214927 0.04472007 0.01039447 0.01381812 0.01105817
## 31 32 33 34 35 36
## 0.03468260 0.04048248 0.03814670 0.04934440 0.05107803 0.02208177
## 37 38 39 40 41 42
## 0.02919013 0.05928178 0.02799695 0.01519967 0.04195751 0.02514137
## 43 44 45 46 47 48
## 0.04267879 0.04517340 0.03558080 0.03360160 0.05019778 0.04587468
## 49 50 51 52 53 54
## 0.03701290 0.05331282 0.04814477 0.01072699 0.04047386 0.02681315
## 55 56 57 58 59 60
## 0.04556787 0.01856997 0.02919045 0.01126069 0.01012683 0.01546412
## 61 62 63 64 65 66
## 0.01029534 0.04428870 0.02438944 0.07469673 0.04135090 0.01775697
## 67 68 69 70 71 72
## 0.04217616 0.01384321 0.01069005 0.01340216 0.01716361 0.01751844
## 73 74 75 76 77 78
## 0.04863314 0.02158623 0.02951418 0.01411915 0.03276064 0.01684599
## 79 80 81 82 83 84
## 0.01028001 0.02920514 0.01348051 0.01752758 0.05184527 0.04583604
## 85 86 87 88 89 90
## 0.05825858 0.01359644 0.03054414 0.01487724 0.02381348 0.02159418
## 91 92 93 94 95 96
## 0.02598661 0.02093288 0.01982480 0.05063492 0.05907629 0.03682026
## 97 98 99 100
## 0.01817919 0.03811718 0.01945603 0.01373394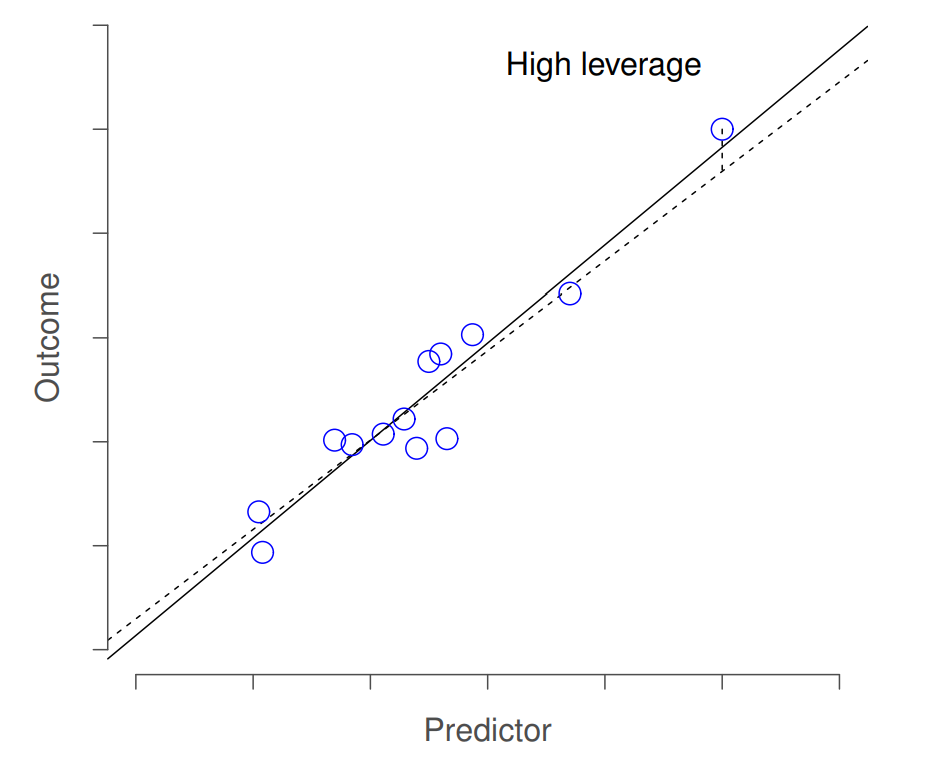
En general, si una observación se encuentra lejos de las otras en términos de las variables predictoras, tendrá un gran valor hat (como guía aproximada, el apalancamiento alto es cuando el valor hat es más de 2-3 veces el promedio; y tenga en cuenta que la suma de los valores hat está restringida para ser igual a K+1). También vale la pena mirar con más detalle los puntos de alto apalancamiento, pero es mucho menos probable que sean motivo de preocupación a menos que también sean valores atípicos.% guía de Venables y Ripley.
Esto nos lleva a nuestra tercera medida de inusualidad, la influencia de una observación. Una observación de alta influencia es un valor atípico que tiene un alto apalancamiento. Es decir, se trata de una observación que es muy diferente a todas las demás en algún aspecto, y además se encuentra muy lejos de la línea de regresión. Esto se ilustra en la Figura 15.9. Observe el contraste con las dos cifras anteriores: los valores atípicos no mueven mucho la línea de regresión, y tampoco los puntos de apalancamiento altos. Pero algo que es un valor atípico y tiene un alto apalancamiento... que tiene un gran efecto en la línea de regresión.
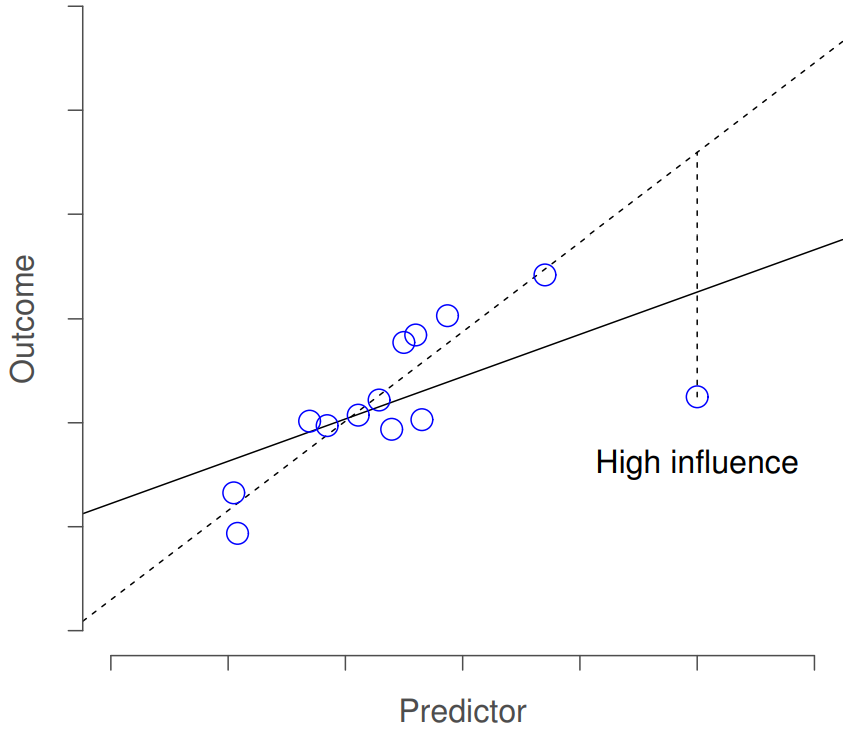
Por eso llamamos a estos puntos de alta influencia; y es por eso que son la mayor preocupación. Operacionalizamos la influencia en términos de una medida conocida como distancia de Cook,
\(D_{i}=\dfrac{\epsilon_{i}^{* 2}}{K+1} \times \dfrac{h_{i}}{1-h_{i}}\)
Observe que esto es una multiplicación de algo que mide el valor atípico de la observación (el bit de la izquierda), y algo que mide el apalancamiento de la observación (el bit a la derecha). Es decir, para tener una gran distancia de Cook, una observación debe ser un valor atípico bastante sustancial y tener un alto apalancamiento. En un impresionante giro de eventos, puedes obtener estos valores usando el siguiente comando:
cooks.distance( model = regression.2 )## 1 2 3 4 5
## 1.736512e-03 1.740243e-02 4.699370e-03 1.301417e-03 2.631557e-04
## 6 7 8 9 10
## 9.697585e-05 2.620181e-05 5.458491e-04 2.876269e-05 3.288277e-03
## 11 12 13 14 15
## 2.731835e-02 8.296919e-03 6.621479e-04 1.235956e-04 2.538915e-03
## 16 17 18 19 20
## 5.012283e-05 3.461742e-03 2.098055e-03 1.957050e-04 1.780519e-02
## 21 22 23 24 25
## 8.367377e-05 1.649478e-03 2.967594e-02 2.657610e-05 3.448032e-04
## 26 27 28 29 30
## 9.093379e-04 5.699951e-02 7.307943e-04 5.716998e-04 2.459564e-03
## 31 32 33 34 35
## 5.214331e-02 6.185200e-03 2.700686e-02 5.467345e-02 2.071643e-02
## 36 37 38 39 40
## 4.606378e-02 1.765312e-02 4.689817e-02 2.316122e-03 7.012530e-05
## 41 42 43 44 45
## 2.827824e-05 1.076083e-02 2.399931e-02 3.381062e-02 1.406498e-02
## 46 47 48 49 50
## 1.801086e-02 1.561699e-02 4.179986e-03 8.483514e-03 2.444787e-04
## 51 52 53 54 55
## 3.689946e-02 7.794472e-04 1.941235e-03 2.446230e-03 4.270361e-03
## 56 57 58 59 60
## 1.266609e-03 1.824212e-03 4.804705e-04 1.163181e-03 3.187235e-03
## 61 62 63 64 65
## 1.595512e-03 3.703826e-04 1.577892e-04 1.138165e-01 2.827715e-02
## 66 67 68 69 70
## 1.139374e-02 1.231422e-03 2.260006e-03 2.241322e-04 1.028479e-02
## 71 72 73 74 75
## 2.841329e-03 1.431223e-03 3.468538e-04 2.941757e-03 2.738249e-03
## 76 77 78 79 80
## 5.045357e-04 1.387108e-02 4.230966e-02 4.187440e-03 3.861831e-03
## 81 82 83 84 85
## 2.965826e-02 1.838888e-04 2.149369e-03 1.993929e-04 9.168733e-02
## 86 87 88 89 90
## 3.198994e-04 3.262192e-04 4.547383e-05 3.400893e-04 7.881487e-04
## 91 92 93 94 95
## 4.801204e-03 4.493095e-03 1.188427e-02 4.796360e-03 1.752666e-02
## 96 97 98 99 100
## 1.732793e-04 1.012302e-02 1.225818e-02 2.394964e-02 8.010508e-03Como guía aproximada, la distancia de Cook mayor que 1 a menudo se considera grande (eso es lo que normalmente uso como regla rápida y sucia), aunque un escaneo rápido de Internet y algunos artículos sugieren que 4/N también se ha sugerido como una posible regla general.
Como se insinuó anteriormente, no suele necesitar hacer uso de estas funciones, ya que puede hacer que R dibuje automáticamente las gráficas críticas. 222 Para el modelo de regresión.2, estas son las gráficas que muestran la distancia de Cook (Figura 15.10) y el desglose más detallado que muestra la gráfica de dispersión del residuo Studentised contra apalancamiento (Figura 15.11). Para dibujar estos, podemos usar la función plot (). Cuando el argumento principal x de esta función es un objeto modelo lineal, dibujará una de las seis gráficas diferentes, cada una de las cuales es bastante útil para hacer diagnósticos de regresión. Especificas cuál quieres usando el argumento qué (un número entre 1 y 6). Si no haces esto entonces R dibujará los seis. Las dos gráficas que nos interesan en este contexto se generan usando los siguientes comandos:
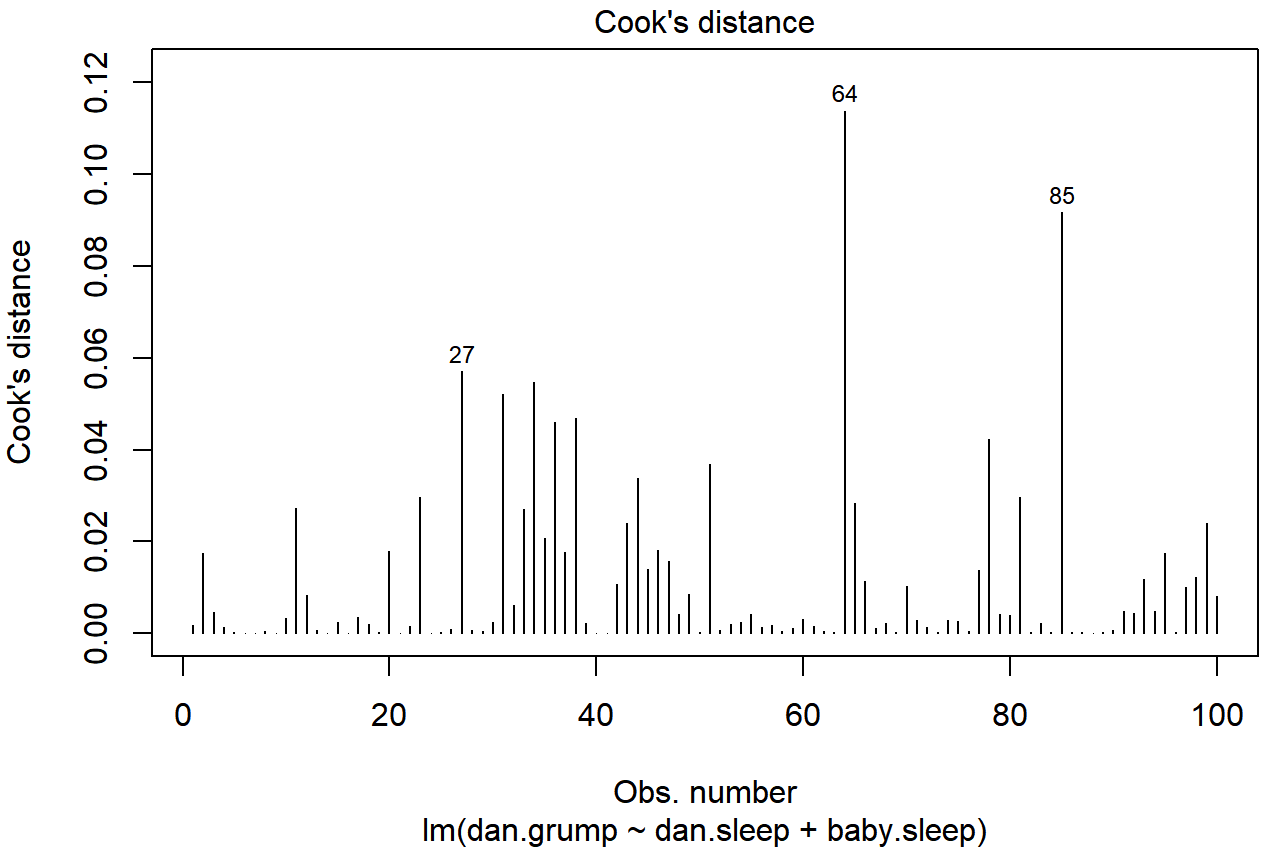
plot () cuando la entrada es un objeto de regresión lineal. Se obtiene fijando qué=4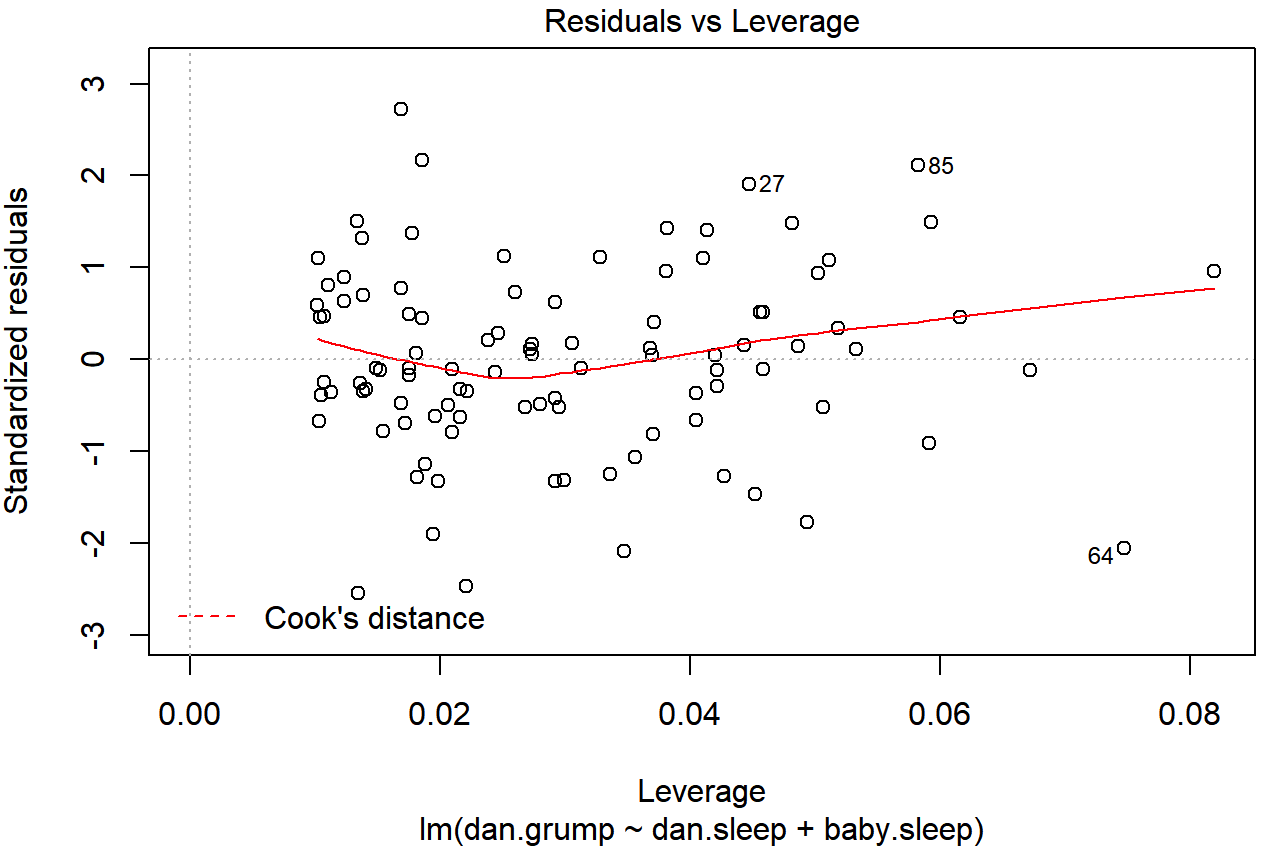
plot () cuando la entrada es un objeto de regresión lineal. Se obtiene fijando qué=5.Una pregunta obvia para hacer a continuación es, si tienes grandes valores de la distancia de Cook, ¿qué debes hacer? Como siempre, no hay reglas duras y rápidas. Probablemente lo primero que hay que hacer es intentar ejecutar la regresión con ese punto excluido y ver qué sucede con el desempeño del modelo y con los coeficientes de regresión. Si realmente son sustancialmente diferentes, es hora de comenzar a indagar en tu conjunto de datos y tus notas que sin duda estabas garabateando mientras dirigías tu estudio; trata de averiguar por qué el punto es tan diferente. Si empiezas a convencerte de que este punto de datos está distorsionando gravemente tus resultados, podrías considerar excluirlo, pero eso es menos que ideal a menos que tengas una explicación sólida de por qué este caso en particular es cualitativamente diferente de los demás y por lo tanto merece ser manejado por separado. 223 Para dar un ejemplo, eliminemos la observación del día 64, la observación con la mayor distancia de Cook para el modelo de regresión.2. Podemos hacer esto usando el argumento subconjunto:
lm( formula = dan.grump ~ dan.sleep + baby.sleep, # same formula
data = parenthood, # same data frame...
subset = -64 # ...but observation 64 is deleted
)##
## Call:
## lm(formula = dan.grump ~ dan.sleep + baby.sleep, data = parenthood,
## subset = -64)
##
## Coefficients:
## (Intercept) dan.sleep baby.sleep
## 126.3553 -8.8283 -0.1319Como puede ver, esos coeficientes de regresión apenas han cambiado en comparación con los valores que obtuvimos antes. En otras palabras, realmente no tenemos ningún problema en lo que respecta a los datos anómalos.
Comprobación de la normalidad de los residuos
Como muchas de las herramientas estadísticas que hemos discutido en este libro, los modelos de regresión se basan en una suposición de normalidad. En este caso, suponemos que los residuos se distribuyen normalmente. Las herramientas para probar esto no son fundamentalmente diferentes a las que discutimos anteriormente en la Sección 13.9. En primer lugar, creo firmemente que nunca está de más dibujar un histograma anticuado. El comando que uso podría ser algo como esto:
hist( x = residuals( regression.2 ), # data are the residuals
xlab = "Value of residual", # x-axis label
main = "", # no title
breaks = 20 # lots of breaks
)La gráfica resultante se muestra en la Figura 15.12, y como se puede ver la trama se ve bastante cerca de lo normal, casi de manera poco natural.
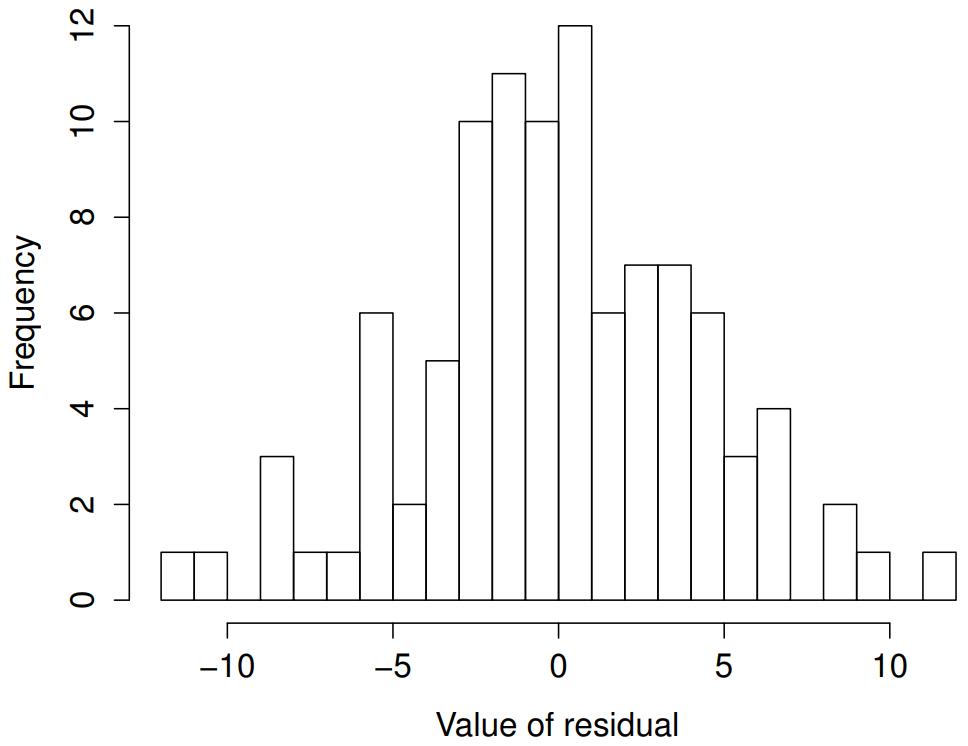
regresión.2. Estos residuos se ven muy cerca de estar distribuidos normalmente, mucho más de lo que normalmente se ve con los datos reales. Esto no debería sorprenderte... ¡no son datos reales, y no son residuos reales!También podría ejecutar una prueba de Shapiro-Wilk para verificar, usando la función shapiro.test (); el valor W de .99, a este tamaño de muestra, no es significativo (p=.84), sugiriendo nuevamente que la suposición de normalidad no está en peligro aquí. Como tercera medida, también podríamos querer dibujar una gráfica QQ usando la función qqnorm (). La gráfica QQ es excelente para dibujar, por lo que tal vez no te sorprenda descubrir que es una de las gráficas de regresión que podemos producir usando la función plot ():
plot( x = regression.2, which = 2 ) # Figure @ref{fig:regressionplot2}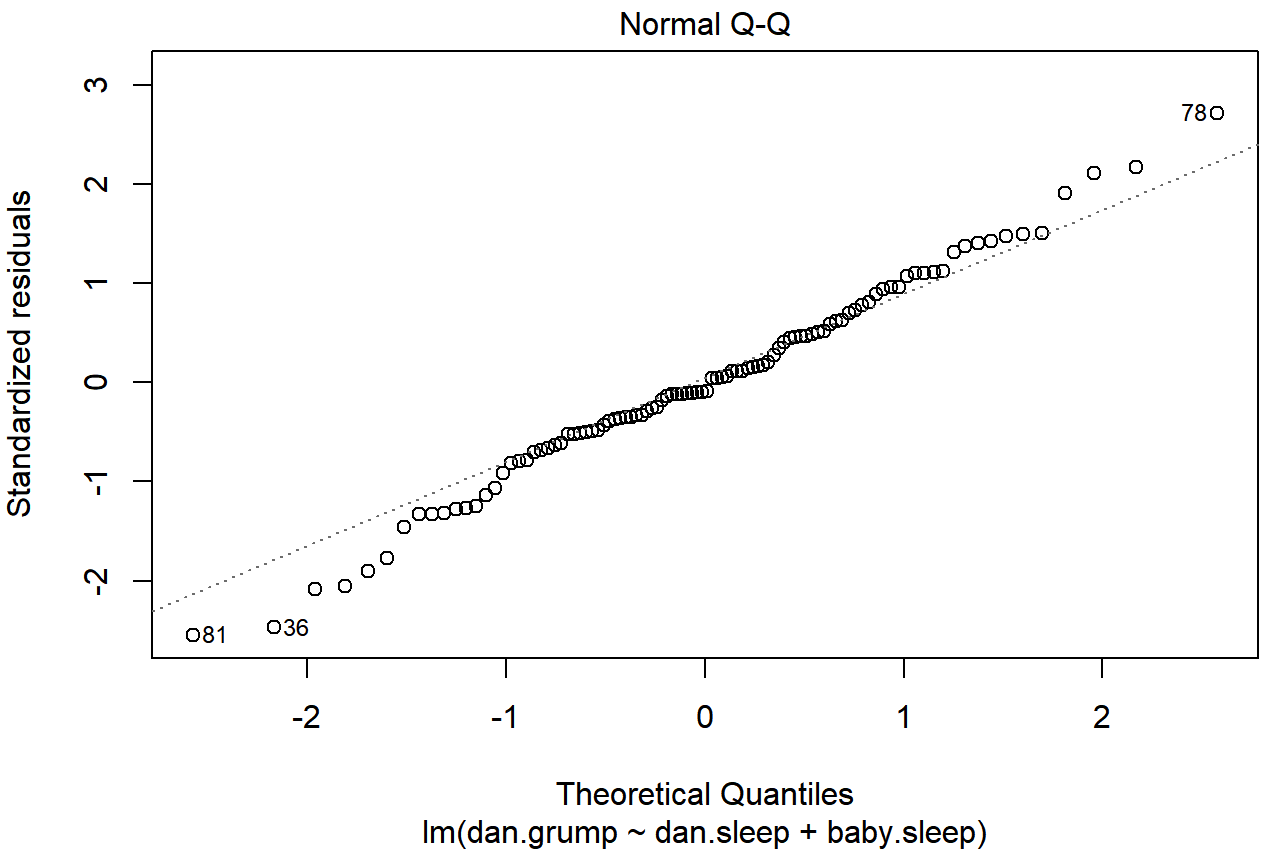
plot () cuando la entrada es un objeto de regresión lineal. Se obtiene fijando qué=2.La salida se muestra en la Figura 15.13, mostrando los residuos estandarizados trazados en función de sus cuantiles teóricos según el modelo de regresión. El hecho de que la salida añada la especificación del modelo a la imagen es agradable.
Comprobación de la linealidad de la relación
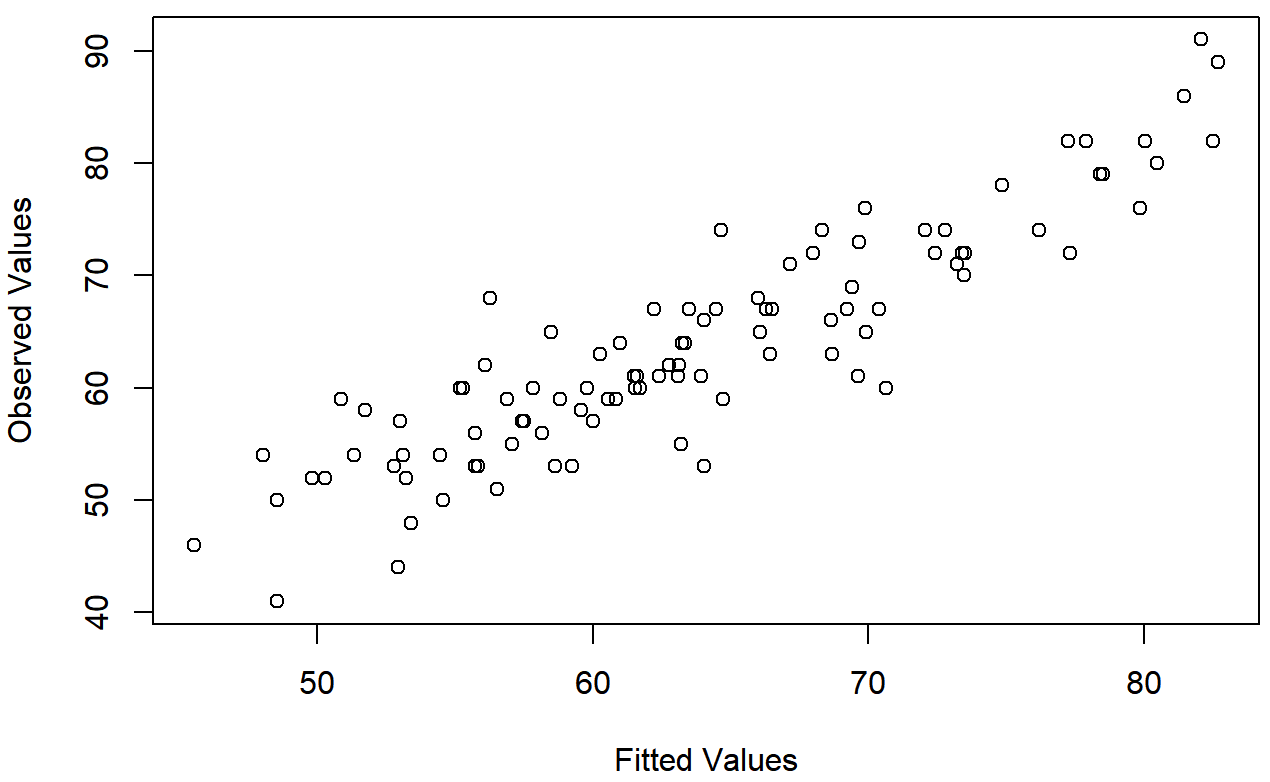
La tercera cosa que podríamos querer probar es la linealidad de las relaciones entre los predictores y los resultados. Hay algunas cosas diferentes que quizás quieras hacer para verificar esto. En primer lugar, nunca está de más trazar la relación entre los valores ajustados\(\ \hat{Y_i}\) y los valores observados Y i para la variable de resultado, como se ilustra en la Figura 15.14. Para dibujar esto podríamos usar la función.values () fitted.values () para extraer los\(\ \hat{Y_i}\) valores de la misma manera que usamos la función residuals () para extraer los valores de i. Entonces los comandos para dibujar esta figura podrían verse así:
yhat.2 <- fitted.values( object = regression.2 )
plot( x = yhat.2,
y = parenthood$dan.grump,
xlab = "Fitted Values",
ylab = "Observed Values"
)Una de las razones por las que me gusta dibujar estas tramas es que te dan una especie de “vista de panorama general”. Si esta trama se ve aproximadamente lineal, entonces probablemente no estemos haciendo demasiado mal (aunque eso no quiere decir que no haya problemas). Sin embargo, si puedes ver grandes desviaciones de la linealidad aquí, entonces sugiere fuertemente que necesitas hacer algunos cambios.
En cualquier caso, para obtener una imagen más detallada suele ser más informativo observar la relación entre los valores ajustados y los propios residuos. Nuevamente, podríamos dibujar esta trama usando comandos de bajo nivel, pero hay una manera más fácil. Simplemente grafique () el modelo de regresión y seleccione cuál = 1:
plot(x = regression.2, which = 1)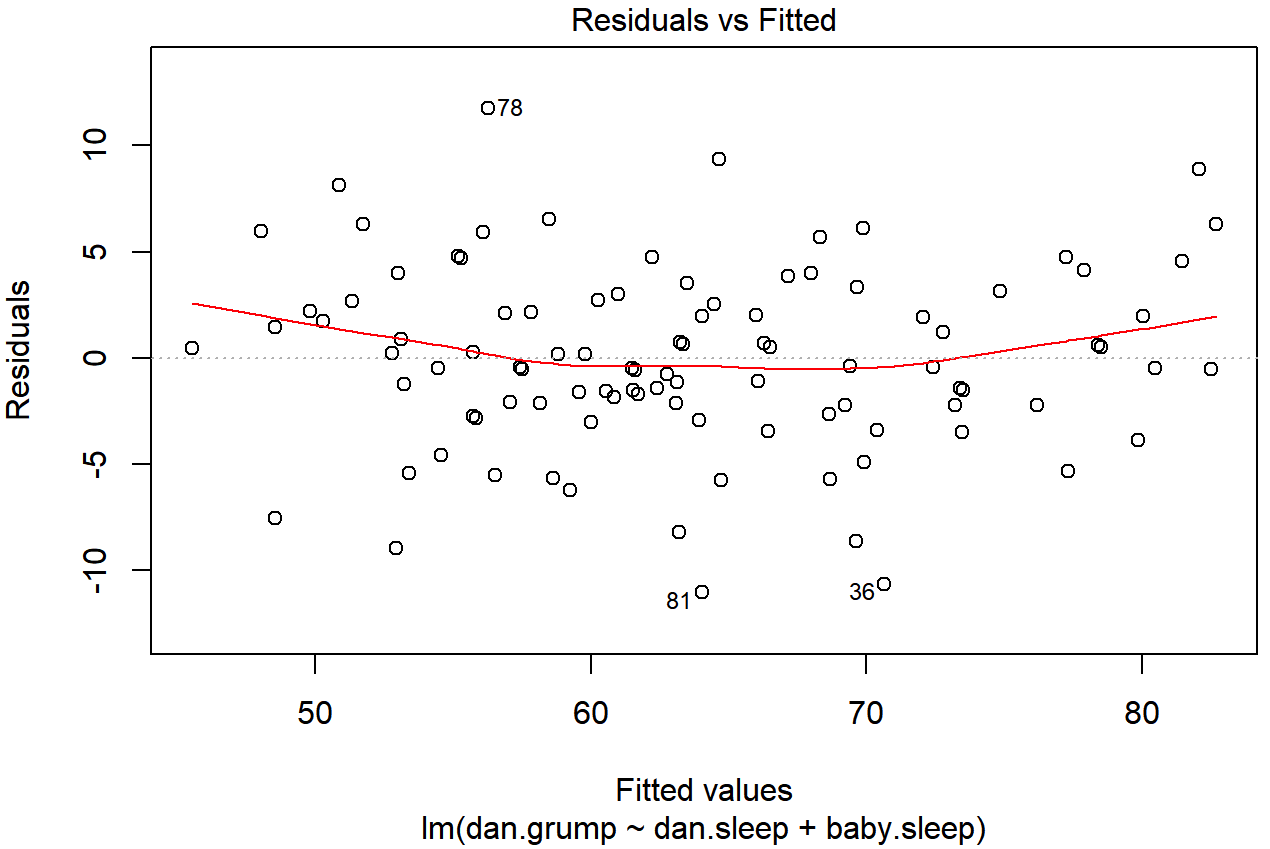
regresión.2, con una línea que muestra la relación entre ambos. Si esto es horizontal y recto, entonces podemos sentirnos razonablemente seguros de que el “residual promedio” para todos los “valores ajustados” es más o menos lo mismo. Esta es una de las gráficas de regresión estándar producidas por la función plot () cuando la entrada es un objeto de regresión lineal. Se obtiene fijando qué=1.La salida se muestra en la Figura 15.15. Como puede ver, no sólo dibuja la gráfica de dispersión mostrando el valor ajustado contra los residuales, sino que también traza una línea a través de los datos que muestra la relación entre los dos. Idealmente, esta debería ser una línea recta, perfectamente horizontal. Aquí hay algún indicio de curvatura, pero no está claro si nos preocupa o no.
Una versión algo más avanzada de la misma parcela es producida por la función ResidualPlot () en el paquete de autos. Esta función no solo dibuja gráficas comparando los valores ajustados con los residuales, sino que lo hace para cada predictor individual. El comando es y las gráficas resultantes se muestran en la Figura 15.16.
residualPlots( model = regression.2 ) ## Loading required package: carData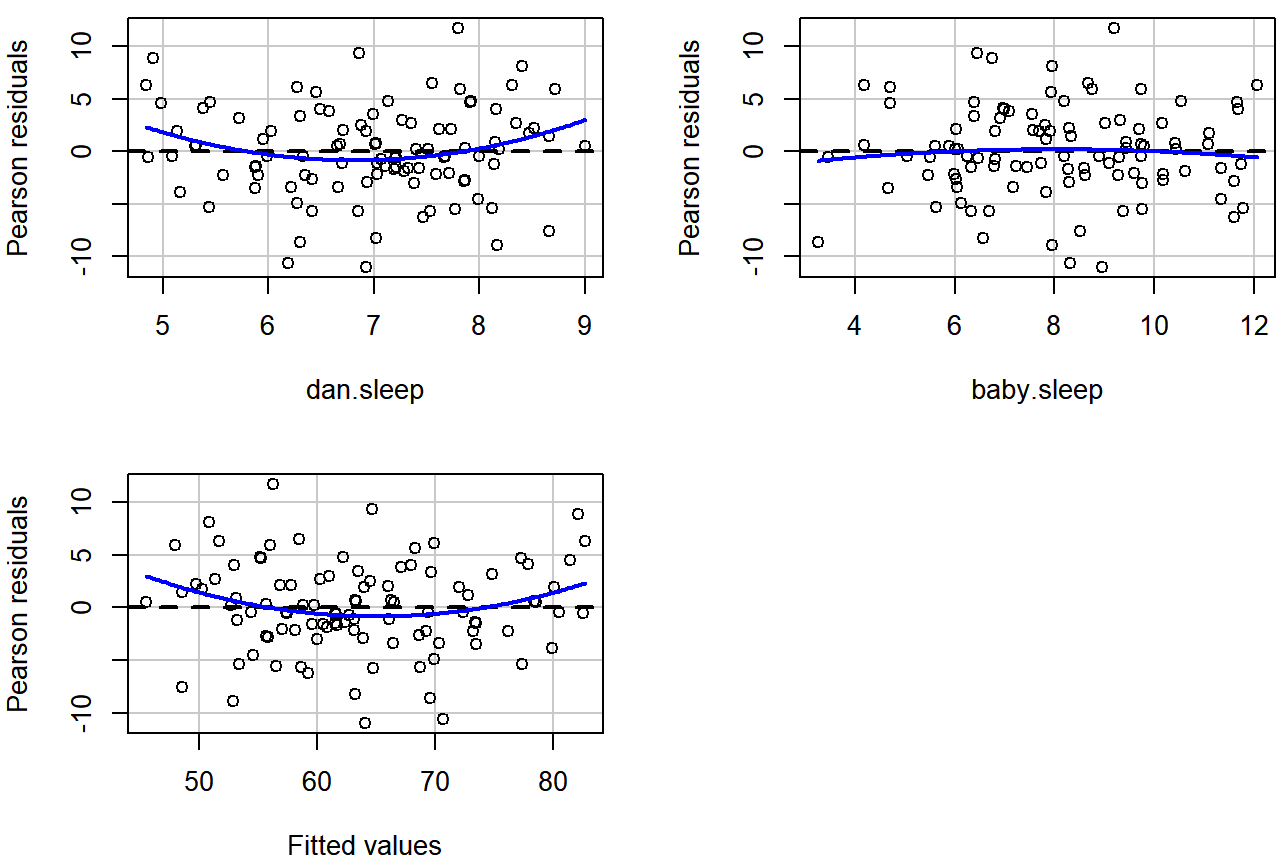
regresión.2, junto con parcelas similares para los dos predictores individualmente. Esta parcela es producida por la función ResidualPlot () en el paquete de autos. Tenga en cuenta que se refiere a los residuos como “residuales de Pearson”, pero en este contexto estos son los mismos que los residuales ordinarios.## Test stat Pr(>|Test stat|)
## dan.sleep 2.1604 0.03323 *
## baby.sleep -0.5445 0.58733
## Tukey test 2.1615 0.03066 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Tenga en cuenta que esta función también reporta los resultados de un montón de pruebas de curvatura. Para una variable predictora X en algún modelo de regresión, esta prueba equivale a agregar un nuevo predictor al modelo correspondiente a X 2, y ejecutar la prueba t sobre el coeficiente b asociado a este nuevo predictor. Si surge significativo, implica que existe alguna relación no lineal entre la variable y los residuales.
La tercera línea aquí es la prueba de Tukey, que es básicamente la misma prueba, excepto que en lugar de cuadrar uno de los predictores y agregarlo al modelo, cuadras el valor ajustado. En todo caso, el hecho de que las pruebas de curvatura hayan salido significativas es insinuar que la curvatura que podemos ver en las Figuras 15.15 y 15.16 es genuina; 224 aunque aún cabe recordar que el patrón en la Figura 15.14 es bastante recto: en otras palabras, las desviaciones de la linealidad son bastante pequeñas, y probablemente no valga la pena preocuparse.
En muchos casos, la solución a este problema (y a muchos otros) es transformar una o más de las variables. Discutimos los fundamentos de la transformación de variables en las Secciones 7.2 y (mathfunc), pero sí quiero hacer especial nota de una posibilidad adicional que no mencioné antes: la transformación de Box-Cox. La función Box-Cox es bastante simple, pero es muy utilizada
\(f(x, \lambda)=\dfrac{x^{\lambda}-1}{\lambda}\)
para todos los valores de λ excepto λ=0. Cuando λ=0 simplemente tomamos el logaritmo natural (es decir, ln (x)). Puedes calcularlo usando la función BoxCox () en el paquete del auto. Mejor aún, si lo que estás tratando de hacer es convertir un dato a normal, o lo más normal posible, existe la función PowerTransformation () en el paquete del auto que puede estimar el mejor valor de λ. La transformación variable es otro tema que merece un tratamiento bastante detallado, pero (de nuevo) debido a limitaciones de plazos, tendrá que esperar hasta una versión futura de este libro.
Comprobación de la homogeneidad de la varianza
Todos los modelos de regresión de los que hemos hablado hacen una suposición de homogeneidad de varianza: se supone que la varianza de los residuos es constante. La gráfica “por defecto” que proporciona R para ayudar a hacer esto (que = 3 al usar plot ()) muestra una gráfica de la raíz cuadrada del tamaño del residuo\(\ \sqrt{|\epsilon_i|}\), en función del valor ajustado\(\ \hat{Y_i}\). Podemos producir la trama usando el siguiente comando,
plot(x = regression.2, which = 3)y la gráfica resultante se muestra en la Figura 15.17. Tenga en cuenta que esta gráfica en realidad usa los residuos estandarizados (es decir, convertidos a puntuaciones z) en lugar de los crudos, pero es inmaterial desde nuestro punto de vista. Lo que estamos buscando ver aquí es una línea recta, horizontal que recorre la mitad de la trama.
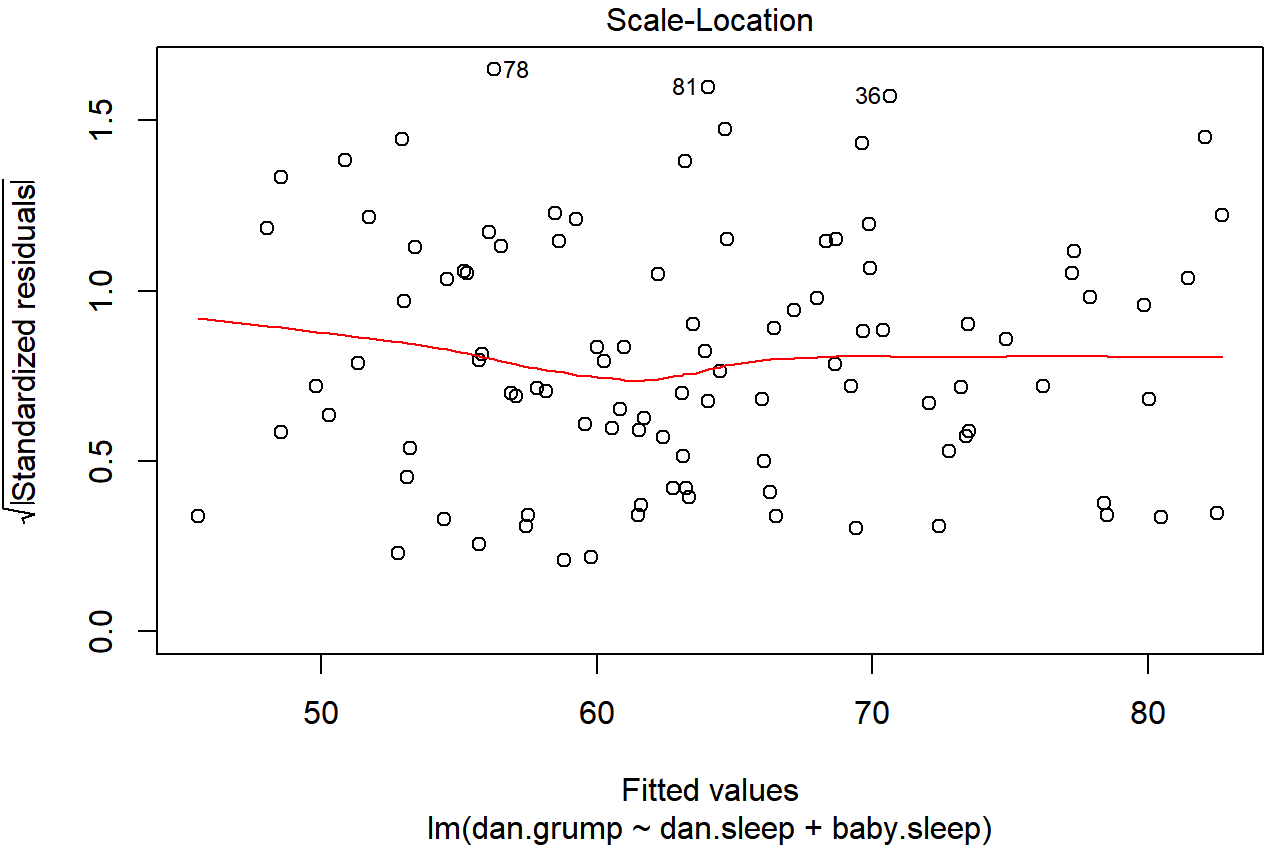
plot () cuando la entrada es un objeto de regresión lineal. Se obtiene fijando qué=3.Un enfoque un poco más formal es realizar pruebas de hipótesis. El paquete del automóvil proporciona una función llamada NCVTest () (prueba de varianza no constante) que se puede utilizar para este propósito (Cook y Weisberg 1983). No voy a explicar los detalles de cómo funciona, aparte de decir que la idea es que lo que haces es ejecutar una regresión para ver si existe una relación entre los residuales cuadrados i y los valores ajustados\(\ \hat{Y_i}\), o posiblemente ejecutar una regresión usando todos los predictores originales en lugar de justo\(\ \hat{Y_i}\). 225 Usando los ajustes predeterminados, el NCVTest () busca una relación entre\(\ \hat{Y_i}\) y la varianza de los residuales, convirtiéndolo en un análogo directo de la Figura 15.17. Entonces, si lo ejecutamos para nuestro modelo,
ncvTest( regression.2 )## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 0.09317511, Df = 1, p = 0.76018Vemos que nuestra impresión original era correcta: no hay violaciones de homogeneidad de varianza en estos datos.
Está un poco más allá del alcance de este capítulo hablar demasiado sobre cómo lidiar con las violaciones de la homogeneidad de la varianza, pero te voy a dar una idea rápida de lo que debes considerar. Lo principal de lo que hay que preocuparse, si se viola la homogeneidad de la varianza, es que las estimaciones de error estándar asociadas a los coeficientes de regresión ya no son del todo confiables, por lo que sus pruebas t para los coeficientes tampoco son del todo correctas. Una solución simple al problema es hacer uso de una “matriz de covarianza corregida por heterocedasticidad” al estimar los errores estándar. Estos suelen llamarse estimadores sandwich, por razones que solo tienen sentido si entiendes las matemáticas a un nivel bajo 226 han implementado como defecto en la función hccm () es un tweak sobre esto, propuesto por Long y Ervin (2000). Esta versión usa\(\Sigma=\operatorname{diag}\left(\epsilon_{i}^{2} /\left(1-h_{i}^{2}\right)\right)\), donde hi es el i-ésimo valor hat. Cielos, la regresión es divertida, ¿no?] No necesitas entender lo que esto significa (no para una clase introductoria), pero podría ser útil notar que hay una función hccm () en el paquete car () que lo hace. Mejor aún, ni siquiera necesitas usarlo. Puedes usar la función coeftest () en el paquete lmtest, pero necesitas cargar el paquete del auto:
library(lmtest)
library(car)
coeftest( regression.2, vcov= hccm )##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 125.965566 3.247285 38.7910 <2e-16 ***
## dan.sleep -8.950250 0.615820 -14.5339 <2e-16 ***
## baby.sleep 0.010524 0.291565 0.0361 0.9713
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1No es sorprendente que estas pruebas t sean prácticamente idénticas a las que vimos cuando usamos antes el comando summary (regression.2); porque no se violó la suposición de homogeneidad de varianza. Pero si lo hubiera sido, podríamos haber visto algunas diferencias más sustanciales.
Comprobación de la colinealidad
El último tipo de diagnóstico de regresión que voy a discutir en este capítulo es el uso de factores de inflación de varianza (VIF), que son útiles para determinar si los predictores en su modelo de regresión están o no muy correlacionados entre sí. Hay un factor de inflación de varianza asociado a cada predictor Xk en el modelo, y la fórmula para el k-ésimo VIF es:
\(\mathrm{VIF}_{k}=\dfrac{1}{1-R_{(-k)}^{2}}\)
donde\(\ {R^2}_{(-k)}\) se refiere al valor R-cuadrado que obtendría si ejecutara una regresión usando Xk como variable de resultado, y todas las demás variables X como predictores. La idea aquí es que\(\ {R^2}_{(-k)}\) es una muy buena medida del grado en que X k se correlaciona con todas las demás variables del modelo. Mejor aún, la raíz cuadrada del VIF es bastante interpretable: te dice cuánto más amplio es el intervalo de confianza para el coeficiente correspondiente b k, relativo a lo que habrías esperado si los predictores son todos agradables y no están correlacionados entre sí. Si solo tienes dos predictores, los valores VIF siempre van a ser los mismos, ya que podemos ver si usamos la función vif () (car package)...
vif( mod = regression.2 )## dan.sleep baby.sleep
## 1.651038 1.651038Y como la raíz cuadrada de 1.65 es 1.28, vemos que la correlación entre nuestros dos predictores no está causando mucho problema.
Para dar una idea de cómo podríamos terminar con un modelo que tiene mayores problemas de colinealidad, supongamos que iba a ejecutar un modelo de regresión mucho menos interesante, en el que traté de predecir el día en que se recopilaron los datos, en función de todas las demás variables del conjunto de datos. Para ver por qué esto sería un problema, echemos un vistazo a la matriz de correlación para las cuatro variables:
cor( parenthood )## dan.sleep baby.sleep dan.grump day
## dan.sleep 1.00000000 0.62794934 -0.90338404 -0.09840768
## baby.sleep 0.62794934 1.00000000 -0.56596373 -0.01043394
## dan.grump -0.90338404 -0.56596373 1.00000000 0.07647926
## day -0.09840768 -0.01043394 0.07647926 1.00000000¡Tenemos algunas correlaciones bastante grandes entre algunas de nuestras variables predictoras! Cuando ejecutamos el modelo de regresión y miramos los valores VIF, vemos que la colinealidad está causando mucha incertidumbre sobre los coeficientes. Primero, ejecutar la regresión...
regression.3 <- lm( day ~ baby.sleep + dan.sleep + dan.grump, parenthood )y segundo, mira los VIF...
vif( regression.3 )## baby.sleep dan.sleep dan.grump
## 1.651064 6.102337 5.437903Sí, esa es una muy fina colinealidad la que tienes ahí.