
4.8: Prueba de Kruskal—Wallis
- Page ID
- 149119

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Objetivos de aprendizaje
- Aprender a usar la prueba de Kruskal—Wallis cuando se tiene una variable nominal y una variable clasificada. Se pone a prueba si los rangos medios son los mismos en todos los grupos.
Cuándo usarlo
El uso más común de la prueba de Kruskal—Wallis es cuando se tiene una variable nominal y una variable de medición, un experimento que normalmente analizaría usando anova unidireccional, pero la variable de medición no cumple con el supuesto de normalidad de un anova unidireccional. Algunas personas tienen la actitud de que a menos que tengas un tamaño de muestra grande y puedas demostrar claramente que tus datos son normales, debes usar rutinariamente Kruskal—Wallis; piensan que es peligroso usar anova unidireccional, que asume normalidad, cuando no sabes con certeza que tus datos son normales. Sin embargo, el anova unidireccional no es muy sensible a las desviaciones de la normalidad. He hecho simulaciones con una variedad de distribuciones no normales, incluyendo planas, altamente pico, altamente sesgadas y bimodales, y la proporción de falsos positivos es siempre alrededor\(5\%\) o un poco menor, tal como debería ser. Por esta razón, no recomiendo la prueba de Kruskal-Wallis como alternativa al anova unidireccional. Debido a que mucha gente lo usa, deberías estar familiarizado con él aunque te convenza de que se usa en exceso.
La prueba de Kruskal-Wallis es una prueba no paramétrica, lo que significa que no asume que los datos provienen de una distribución que puede describirse completamente por dos parámetros, media y desviación estándar (la forma en que una distribución normal puede). Al igual que la mayoría de las pruebas no paramétricas, lo realiza en datos clasificados, por lo que convierte las observaciones de medición a sus rangos en el conjunto de datos general: el valor más pequeño obtiene un rango de\(1\), el siguiente más pequeño obtiene un rango de\(2\), y así sucesivamente. Pierdes información cuando sustituyes rangos por los valores originales, lo que puede hacer de esta una prueba algo menos poderosa que un anova unidireccional; esta es otra razón para preferir el anova unidireccional.
El otro supuesto del anova unidireccional es que la variación dentro de los grupos es igual (homocedasticidad). Si bien Kruskal-Wallis no asume que los datos son normales, sí asume que los diferentes grupos tienen la misma distribución, y los grupos con diferentes desviaciones estándar tienen distribuciones diferentes. Si tus datos son heteroscedásticos, Kruskal—Wallis no es mejor que el anova unidireccional, y puede ser peor. En su lugar, deberías usar el anova de Welch para los datos heteoscedásticos.
La única vez que recomiendo usar Kruskal-Wallis es cuando tu conjunto de datos original consiste en una variable nominal y una variable clasificada; en este caso, no puedes hacer un anova unidireccional y debes usar la prueba de Kruskal—Wallis. Las jerarquías de dominancia (en biología conductual) y las etapas de desarrollo son las únicas variables clasificadas que se me ocurren y que son comunes en biología.
La prueba de Mann-Whitney (también conocida como\(U\) prueba de Mann—Whitney—Wilcoxon, prueba de suma de rangos de Wilcoxon o prueba de dos muestras de Wilcoxon) se limita a variables nominales con solo dos valores; es el análogo no paramétrico a la prueba t de dos muestras. Utiliza una estadística de prueba diferente (\(U\)en lugar de la prueba\(H\) de Kruskal—Wallis), pero el\(P\) valor es matemáticamente idéntico al de una prueba de Kruskal—Wallis. Por simplicidad, solo me referiré a Kruskal—Wallis en el resto de esta página web, pero todo también aplica a la\(U\) prueba de Mann—Whitney.
La prueba de Kruskal—Wallis a veces se denomina anova unidireccional de Kruskal—Wallis o anova unidireccional no paramétrico. Creo que llamar a la prueba de Kruskal—Wallis un anova es confuso, y te recomiendo que solo la llames la prueba de Kruskal—Wallis.
Hipótesis nula
La hipótesis nula de la prueba de Kruskal—Wallis es que los rangos medios de los grupos son los mismos. El rango medio esperado depende únicamente del número total de observaciones (para\(n\) las observaciones, el rango medio esperado en cada grupo es (\(\frac{n+1}{2}\)), por lo que no es una descripción muy útil de los datos; no es algo que trazarías en una gráfica.
A veces se verá la hipótesis nula de la prueba de Kruskal—Wallis dada como “Las muestras provienen de poblaciones con la misma distribución”. Esto es correcto, ya que si las muestras provienen de poblaciones con la misma distribución, la prueba de Kruskal—Wallis no mostrará diferencia entre ellas. Creo que es un poco engañoso, sin embargo, porque sólo algunos tipos de diferencias en la distribución serán detectadas por la prueba. Por ejemplo, si dos poblaciones tienen distribuciones simétricas con el mismo centro, pero una es mucho más ancha que la otra, sus distribuciones son diferentes pero la prueba de Kruskal—Wallis no detectará ninguna diferencia entre ellas.
La hipótesis nula de la prueba de Kruskal—Wallis no es que las medias sean las mismas. Por lo tanto, es incorrecto decir algo así como “La concentración media de fructosa es mayor en peras que en manzanas (prueba de Kruskal—Wallis,\(P=0.02\))”, aunque verá datos resumidos con medias y luego comparados con las pruebas de Kruskal—Wallis en muchas publicaciones. El malentendido común de la hipótesis nula de Kruskal-Wallis es otra razón más que no me gusta.
A menudo se dice que la hipótesis nula de la prueba de Kruskal—Wallis es que las medianas de los grupos son iguales, pero esto sólo es cierto si se asume que la forma de la distribución en cada grupo es la misma. Si las distribuciones son diferentes, la prueba de Kruskal—Wallis puede rechazar la hipótesis nula aunque las medianas sean las mismas. Para ilustrar este punto, conformé estos tres conjuntos de números. Tienen medias idénticas (\(43.5\)) e idénticas medianas (\(27.5\)), pero los rangos medios son diferentes (\(34.6\),\(27.5\) y, respectivamente)\(20.4\), resultando en una prueba significativa (\(P=0.025\)) de Kruskal—Wallis:
| Grupo 1 | Grupo 2 | Grupo 3 |
|---|---|---|
| 1 | 10 | 19 |
| 2 | 11 | 20 |
| 3 | 12 | 21 |
| 4 | 13 | 22 |
| 5 | 14 | 23 |
| 6 | 15 | 24 |
| 7 | 16 | 25 |
| 8 | 17 | 26 |
| 9 | 18 | 27 |
| 46 | 37 | 28 |
| 47 | 58 | 65 |
| 48 | 59 | 66 |
| 49 | 60 | 67 |
| 50 | 61 | 68 |
| 51 | 62 | 69 |
| 52 | 63 | 70 |
| 53 | 64 | 71 |
| 342 | 193 | 72 |
Cómo funciona la prueba
Aquí hay algunos datos sobre Wright\(F_{ST}\) (una medida de la cantidad de variación geográfica en un polimorfismo genético) en dos poblaciones de la ostra americana, Crassostrea virginica. McDonald et al. (1996) recopilaron datos sobre\(F_{ST}\) seis polimorfismos de ADN anónimos (variación en bits aleatorios de ADN sin función conocida) y compararon los\(F_{ST}\) valores de los seis polimorfismos de ADN con\(F_{ST}\) valores en\(13\) proteínas de Buroker (1983). La cuestión biológica fue si los polimorfismos proteicos tendrían generalmente\(F_{ST}\) valores menores o mayores que los polimorfismos de ADN anónimos. McDonald et al. (1996) sabían que la distribución teórica de\(F_{ST}\) para dos poblaciones es altamente sesgada, por lo que analizaron los datos con una prueba de Kruskal—Wallis.
Cuando se trabaja con una variable de medición, la prueba de Kruskal—Wallis comienza sustituyendo el rango en el conjunto de datos general por cada valor de medición. El valor más pequeño obtiene un rango de\(1\), el segundo más pequeño obtiene un rango de\(2\), etc Las observaciones empatadas obtienen rangos promedio; en este conjunto de datos, los dos\(F_{ST}\) valores de\(-0.005\) están empatados para segundo y tercero, por lo que obtienen un rango de\(2.5\).
| gen | clase | F ST | Rango | Rango |
|---|---|---|---|---|
| CVJ5 | ADN | -0.006 | 1 | |
| CVB1 | ADN | -0.005 | 2.5 | |
| 6Pgd | proteína | -0.005 | 2.5 | |
| Pgi | proteína | -0.002 | 4 | |
| CVL3 | ADN | 0.003 | 5 | |
| Est-3 | proteína | 0.004 | 6 | |
| Lap-2 | proteína | 0.006 | 7 | |
| Pgm-1 | proteína | 0.015 | 8 | |
| Aat-2 | proteína | 0.016 | 9.5 | |
| Adk-1 | proteína | 0.016 | 9.5 | |
| Sdh | proteína | 0.024 | 11 | |
| Acp3 | proteína | 0.041 | 12 | |
| Pgm-2 | proteína | 0.044 | 13 | |
| Lap-1 | proteína | 0.049 | 14 | |
| CVL1 | ADN | 0.053 | 15 | |
| Mpi-2 | proteína | 0.058 | 16 | |
| Ap-1 | proteína | 0.066 | 17 | |
| CVJ6 | ADN | 0.095 | 18 | |
| CVB2m | ADN | 0.116 | 19 | |
| Est-1 | proteína | 0.163 | 20 |
Se calcula la suma de los rangos para cada grupo, luego el estadístico de prueba,\(H\). \(H\)viene dada por una fórmula bastante formidable que básicamente representa la varianza de las filas entre grupos, con un ajuste por el número de empates. \(H\)es aproximadamente chi-cuadrado distribuido, es decir, que la probabilidad de obtener un valor particular de\(H\) por casualidad, si la hipótesis nula es verdadera, es el\(P\) valor correspondiente a un chi-cuadrado igual a\(H\); los grados de libertad es el número de grupos menos\(1\). Para los datos de ejemplo, el rango medio para el ADN es\(10.08\) y el rango medio para la proteína es\(10.68\)\(H=0.043\),, hay\(1\) grado de libertad, y el\(P\) valor es\(0.84\). No se rechaza la hipótesis nula\(F_{ST}\) de que los polimorfismos de ADN y proteínas tienen los mismos rangos medios.
Por las razones dadas anteriormente, creo que en realidad sería mejor analizar los datos de ostra con anova unidireccional. Da un\(P\) valor de\(0.75\), que afortunadamente no cambiaría las conclusiones de McDonald et al. (1996).
Si los tamaños de muestra son demasiado pequeños,\(H\) no sigue muy bien una distribución de chi-cuadrado, y los resultados de la prueba deben usarse con precaución. \(N\)menos que\(5\) en cada grupo parece ser la definición aceptada de “demasiado pequeña”.
Supuestos
La prueba de Kruskal—Wallis NO asume que los datos se distribuyen normalmente; esa es su gran ventaja. Si lo estás usando para probar si las medianas son diferentes, sí se asume que las observaciones en cada grupo provienen de poblaciones con la misma forma de distribución, así que si diferentes grupos tienen formas diferentes (uno está sesgado a la derecha y otro está sesgado a la izquierda, por ejemplo, o tienen diferentes varianzas), la prueba de Kruskal—Wallis puede dar resultados inexactos (Fagerland y Sandvik 2009). Si te interesa alguna diferencia entre los grupos que haga que los rangos medios sean diferentes, entonces la prueba de Kruskal—Wallis no hace suposiciones.
La heterocedasticidad es una forma en la que diferentes grupos pueden tener diferentes distribuciones de formas. Si las distribuciones son heteroscedásticas, la prueba de Kruskal—Wallis no te ayudará; en cambio, deberías usar la prueba t de Welch para dos grupos, o el anova de Welch para más de dos grupos.
Ejemplo

Bolek y Coggins (2003) recolectaron múltiples individuos del sapo Bufo americanus, la rana Rana pipiens y la salamandra Ambystoma laterale de una pequeña área de Wisconsin. Diseccionaron los anfibios y contaron el número de gusanos helmintos parásitos en cada individuo. Hay una variable de medición (gusanos por anfibio individual) y una variable nominal (especie de anfibio), y los autores no pensaron que los datos se ajustaban a los supuestos de un anova. Los resultados de una prueba de Kruskal—Wallis fueron significativos (\(H=63.48\)\(2 d.f.\),,\(P=1.6\times 10^{-14}\)); los rangos medios de gusanos por individuo son significativamente diferentes entre las tres especies.
| Perro | Sexo | Rango |
|---|---|---|
| Merlino | Macho | 1 |
| Gastone | Macho | 2 |
| Pippo | Macho | 3 |
| León | Macho | 4 |
| Gilia | Macho | 5 |
| Lancillotto | Macho | 6 |
| Mamy | Hembra | 7 |
| Nanà | Hembra | 8 |
| Isotta | Hembra | 9 |
| Diana | Hembra | 10 |
| Simba | Macho | 11 |
| Pongo | Macho | 12 |
| Semola | Macho | 13 |
| Kimba | Macho | 14 |
| Morgana | Hembra | 15 |
| Stella | Hembra | 16 |
| Hansel | Macho | 17 |
| Cucciola | Macho | 18 |
| Mammolo | Macho | 19 |
| Dotto | Macho | 20 |
| Gongolo | Macho | 21 |
| Gretel | Hembra | 22 |
| Brontolo | Hembra | 23 |
| Eolo | Hembra | 24 |
| Mag | Hembra | 25 |
| Emy | Hembra | 26 |
| Pisola | Hembra | 27 |
Cafazzo et al. (2010) observaron un grupo de perros domésticos de rango libre en las afueras de Roma. Con base en la dirección de\(1815\) las observaciones del comportamiento sumiso, fueron capaces de colocar a los perros en una jerarquía de dominancia, desde los más dominantes (Merlino) hasta los más sumisos (Pisola). Debido a que esta es una verdadera variable clasificada, es necesario usar la prueba de Kruskal—Wallis. El rango medio para los hombres (\(11.1\)) es menor que el rango medio para las mujeres (\(17.7\)), y la diferencia es significativa (\(H=4.61\),\(1 d.f.\),\(P=0.032\)).
Graficando los resultados
Es complicado saber cómo mostrar visualmente los resultados de una prueba de Kruskal—Wallis. Sería engañoso trazar las medias o medianas en un gráfico de barras, ya que la prueba de Kruskal—Wallis no es una prueba de la diferencia en medias o medianas. Si hay un número relativamente pequeño de observaciones, podría poner las observaciones individuales en un gráfico de barras, con el valor de la variable de medición en el\(Y\) eje y su rango en el\(X\) eje, y usar un patrón diferente para cada valor de la variable nominal. Aquí hay un ejemplo usando los\(F_{ST}\) datos de ostra:
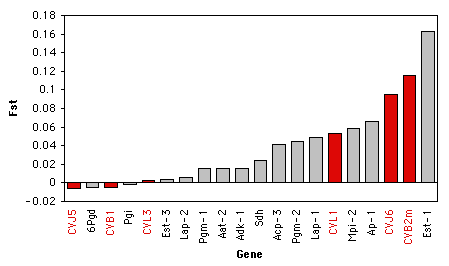
Si hay un mayor número de observaciones, podría trazar un histograma para cada categoría, todas con la misma escala, y alinearlas verticalmente. No tengo datos adecuados para esto a mano, así que aquí hay una ilustración con datos imaginarios:
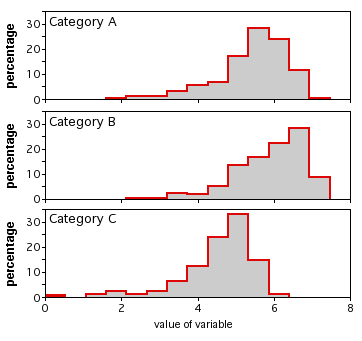
Pruebas similares
El anova unidireccional es más potente y mucho más fácil de entender que la prueba de Kruskal—Wallis, así que a menos que tengas una verdadera variable clasificada, deberías usarla.
Cómo hacer la prueba
Hoja de Cálculo
He elaborado una hoja de cálculo para hacer la prueba Kruskal—Wallis kruskalwallis.xls en hasta\(20\) grupos, con hasta\(1000\) observaciones por grupo.
Páginas web
Richard Lowry tiene páginas web para realizar la prueba de Kruskal—Wallis para dos grupos, tres grupos o cuatro grupos.
R
El\(R\) compañero de Salvatore Mangiafico cuenta con un programa R de muestra para la prueba de Kruskal—Wallis.
SAS
Para hacer una prueba de Kruskal—Wallis en SAS, use el procedimiento NPAR1WAY (ese es el numeral “uno”, no la letra “el”, en NPAR1WAY). WILCOXON le dice al procedimiento que solo haga la prueba de Kruskal—Wallis; si lo dejas fuera, también obtendrás varias otras pruebas estadísticas, tentándote a elegir la que más te guste de los resultados. La variable nominal que da los nombres de grupo se da con el parámetro CLASS, mientras que la variable de medición o clasificada se da con el parámetro VAR. Aquí hay un ejemplo, usando los datos de ostra de arriba:
Ostras DATA;
INPUT Markername $ marcadortype $ fst;
DATALINES;
CVB1 DNA -0.005 CVB2m DNA 0.116
CVJ5 DNA
-0.006 CVJ6 DNA 0.095
CVL1 DNA 0.053
CVL3 DNA 0.003 Proteína
6Pgd -0.005 Proteína
Aat-2 0.016 Proteína
Acp3 0.041 Proteína
Adk-1 0.016 Proteína
Ap-1 0.066 Proteína
Est-1 0.163 Proteína
Est-3 0.004 Proteína
Lap-1 0. 049 Proteína
Lap-2 0.006 Proteína
Mpi-2 0.058 Proteína
Pgi -0.002 Proteína
Pgm-1 0.015 Proteína
Pgm-2 0.044 Proteína
Sdh 0.024
;
PROC NPAR1WAY DATA=Ostras WILCOXON;
CLASE Markertype;
VAR fst;
RUN;
El resultado contiene una tabla de “puntuaciones de Wilcoxon”; la “puntuación media” es el rango medio en cada grupo, que es lo que estás probando la homogeneidad de. “Chi-cuadrado” es el\(H\) -estadístico de la prueba de Kruskal—Wallis, el cual es aproximadamente chi-cuadrado distribuido. El “Pr > Chi-Cuadrado” es su\(P\) valor. Usted reportaría estos resultados como "\(H=0.04\),\(1 d.f.\),\(P=0.84\).”
Puntajes Wilcoxon (Sumas de rango) para Variable fst clasificados por Variable markertype
Suma de Desv estándar esperado Media
marcadortype N Puntuaciones bajo H0 Bajo H0 Puntuación
—
ADN 6 60.50 63.0 12.115236 10.083333
proteína 14 149.50 147.0 12.115236 10.678571
Kruskal—Wallis Prueba
Chi-Cuadrado 0.0426
DF 1
Pr > Chi-Cuadrado 0.8365
Análisis de potencia
No conozco una técnica para estimar el tamaño de muestra necesario para una prueba de Kruskal—Wallis.
Referencias
- Bolek, M.G., y J.R. Coggins. 2003. Estructura de la comunidad de helmintos de sapo simpátrico del este americano, Bufo americanus americanus, rana leopardo del norte, Rana pipiens y salamandra manchada azul, Ambystoma laterale, del sureste de Wisconsin. Revista de Parasitología 89:673-680.
- Buroker, N. E. 1983. Genética poblacional de la ostra americana Crassostrea virginica a lo largo de la costa atlántica y el Golfo de México. Biología Marina 75:99-112.
- Cafazzo, S., P. Valsecchi, R. Bonanni, y E. Natoli. 2010. Dominio en relación con la edad, el sexo y los contextos competitivos en un grupo de perros domésticos de rango libre. Ecología del Comportamiento 21:443-455.
- Fagerland, M.W., y L. Sandvik. 2009. La prueba de Wilcoxon-Mann-Whitney bajo escrutinio. Estadística en Medicina 28:1487-1497.
- McDonald, J.H., B.C. Verrelli y L.B. Geyer. 1996. Falta de variación geográfica en polimorfismos nucleares anónimos en la ostra americana, Crassostrea virginica. Biología Molecular y Evolución 13:1114-1118.