
10.8: Un ejemplo completo
- Page ID
- 151181
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
- Ver un análisis completo de correlación lineal y regresión, en un entorno práctico, como un todo cohesivo
En las secciones anteriores se introdujeron e ilustraron numerosos conceptos, pero el análisis se partió en piezas disjuntas por secciones. En esta sección pasaremos por un ejemplo completo del uso del análisis de correlación y regresión de datos de principio a fin, tocando todos los temas de este capítulo en secuencia.
En general, los educadores están convencidos de que, siendo iguales todos los demás factores, la asistencia a clases tiene una influencia significativa en el desempeño del curso. Para investigar la relación entre asistencia y desempeño, un investigador de educación selecciona para estudiar un curso introductorio de estadística de múltiples secciones en una gran universidad. Los instructores del curso acuerdan llevar un registro preciso de asistencia a lo largo de un semestre. Al final del semestre se selecciona al azar a\(26\) los alumnos. Por cada alumno de la muestra se toman dos medidas:\(x\), el número de días que el alumno estuvo ausente, y\(y\), la puntuación del alumno en el examen final común en el curso. Los datos se resumen en la Tabla\(\PageIndex{1}\).
| Ausencias | Score | Ausencias | Score |
|---|---|---|---|
| \(x\) | \(y\) | \(x\) | \(y\) |
| \ (x\) ">2 | \ (y\) ">76 | \ (x\) ">4 | \ (y\) ">41 |
| \ (x\) ">7 | \ (y\) ">29 | \ (x\) ">5 | \ (y\) ">63 |
| \ (x\) ">2 | \ (y\) ">96 | \ (x\) ">4 | \ (y\) ">88 |
| \ (x\) ">7 | \ (y\) ">63 | \ (x\) ">0 | \ (y\) ">98 |
| \ (x\) ">2 | \ (y\) ">79 | \ (x\) ">1 | \ (y\) ">99 |
| \ (x\) ">7 | \ (y\) ">71 | \ (x\) ">0 | \ (y\) ">89 |
| \ (x\) ">0 | \ (y\) ">88 | \ (x\) ">1 | \ (y\) ">96 |
| \ (x\) ">0 | \ (y\) ">92 | \ (x\) ">3 | \ (y\) ">90 |
| \ (x\) ">6 | \ (y\) ">55 | \ (x\) ">1 | \ (y\) ">90 |
| \ (x\) ">6 | \ (y\) ">70 | \ (x\) ">3 | \ (y\) ">68 |
| \ (x\) ">2 | \ (y\) ">80 | \ (x\) ">1 | \ (y\) ">84 |
| \ (x\) ">2 | \ (y\) ">75 | \ (x\) ">3 | \ (y\) ">80 |
| \ (x\) ">1 | \ (y\) ">63 | \ (x\) ">1 | \ (y\) ">78 |
Un gráfico de dispersión de los datos se da en la Figura\(\PageIndex{1}\). Hay una tendencia a la baja en la trama lo que indica que en promedio los estudiantes con más ausencias tienden a empeorar en el examen final.
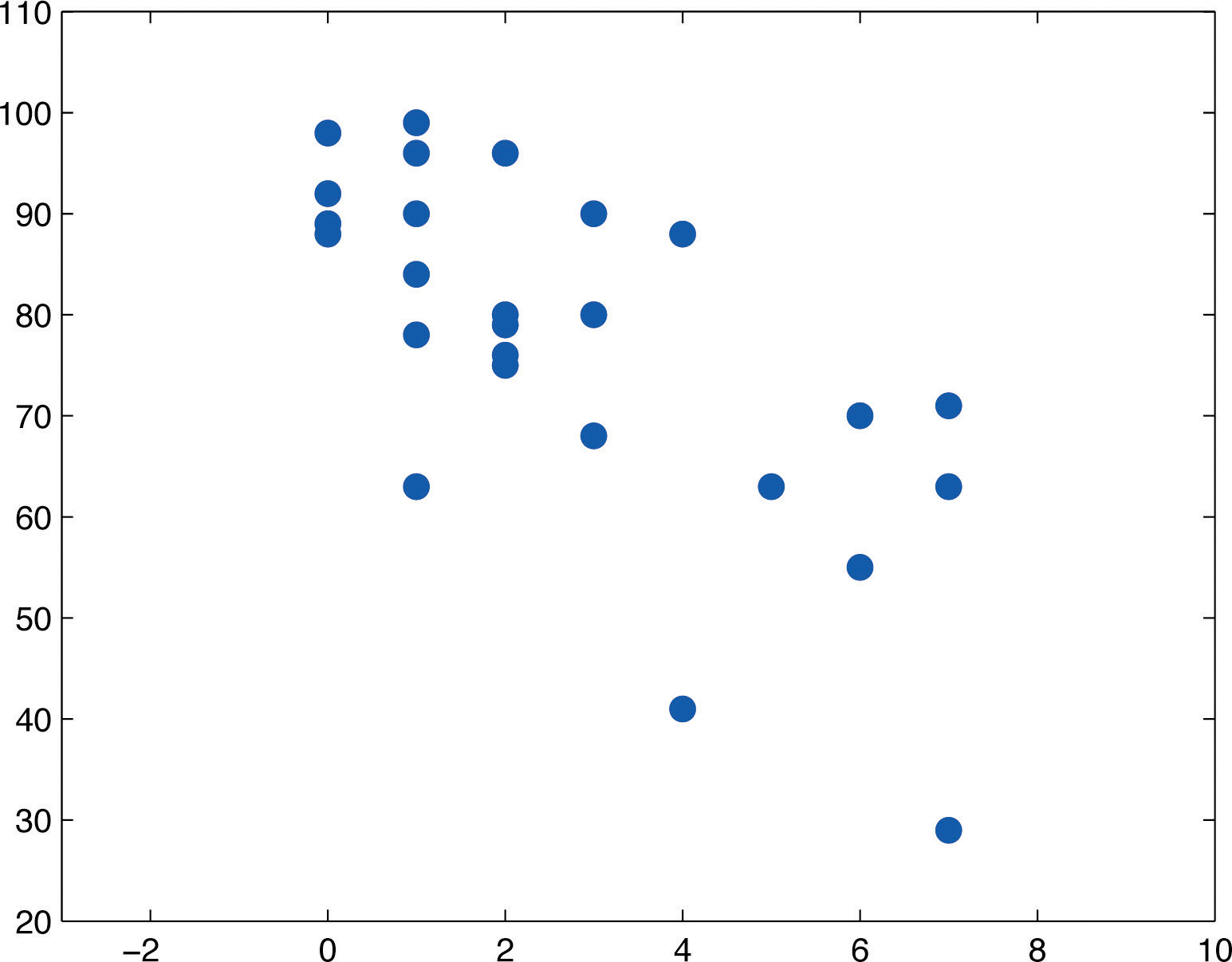
La tendencia observada en la Figura así\(\PageIndex{1}\) como el ancho bastante constante de la banda aparente de puntos en la gráfica hacen razonable asumir una relación entre\(x\) y\(y\) de la forma
donde\(β_1\) y\(β_0\) son parámetros desconocidos y\(\varepsilon\) es una variable aleatoria normal con media cero y desviación estándar desconocida\(\sum\). Obsérvese cuidadosamente que este modelo se está planteando para la población de todos los estudiantes que cursan este curso, no solo los que lo toman este semestre, y desde luego no solo los de la muestra. Los números\(β_1\),\(β_0\), y\(\sum\) son parámetros relativos a esta gran población.
Primero realizamos cálculos preliminares que serán necesarios posteriormente. Los datos se procesan en la Tabla\(\PageIndex{2}\).
| \(x\) | \(y\) | \(x^2\) | \(xy\) | \(y^2\) | \(x\) | \(y\) | \(x^2\) | \(xy\) | \(y^2\) |
|---|---|---|---|---|---|---|---|---|---|
| \ (x\) ">2 | \ (y\) ">76 | \ (x^2\) ">4 | \ (xy\) ">152 | \ (y^2\) ">5776 | \ (x\) ">4 | \ (y\) ">41 | \ (x^2\) ">16 | \ (xy\) ">164 | \ (y^2\) ">1681 |
| \ (x\) ">7 | \ (y\) ">29 | \ (x^2\) ">49 | \ (xy\) ">203 | \ (y^2\) ">841 | \ (x\) ">5 | \ (y\) ">63 | \ (x^2\) ">25 | \ (xy\) ">315 | \ (y^2\) ">3969 |
| \ (x\) ">2 | \ (y\) ">96 | \ (x^2\) ">4 | \ (xy\) ">192 | \ (y^2\) ">9216 | \ (x\) ">4 | \ (y\) ">88 | \ (x^2\) ">16 | \ (xy\) ">352 | \ (y^2\) ">7744 |
| \ (x\) ">7 | \ (y\) ">63 | \ (x^2\) ">49 | \ (xy\) ">441 | \ (y^2\) ">3969 | \ (x\) ">0 | \ (y\) ">98 | \ (x^2\) ">0 | \ (xy\) ">0 | \ (y^2\) ">9604 |
| \ (x\) ">2 | \ (y\) ">79 | \ (x^2\) ">4 | \ (xy\) ">158 | \ (y^2\) ">6241 | \ (x\) ">1 | \ (y\) ">99 | \ (x^2\) ">1 | \ (xy\) ">99 | \ (y^2\) ">9801 |
| \ (x\) ">7 | \ (y\) ">71 | \ (x^2\) ">49 | \ (xy\) ">497 | \ (y^2\) ">5041 | \ (x\) ">0 | \ (y\) ">89 | \ (x^2\) ">0 | \ (xy\) ">0 | \ (y^2\) ">7921 |
| \ (x\) ">0 | \ (y\) ">88 | \ (x^2\) ">0 | \ (xy\) ">0 | \ (y^2\) ">7744 | \ (x\) ">1 | \ (y\) ">96 | \ (x^2\) ">1 | \ (xy\) ">96 | \ (y^2\) ">9216 |
| \ (x\) ">0 | \ (y\) ">92 | \ (x^2\) ">0 | \ (xy\) ">0 | \ (y^2\) ">8464 | \ (x\) ">3 | \ (y\) ">90 | \ (x^2\) ">9 | \ (xy\) ">270 | \ (y^2\) ">8100 |
| \ (x\) ">6 | \ (y\) ">55 | \ (x^2\) ">36 | \ (xy\) ">330 | \ (y^2\) ">3025 | \ (x\) ">1 | \ (y\) ">90 | \ (x^2\) ">1 | \ (xy\) ">90 | \ (y^2\) ">8100 |
| \ (x\) ">6 | \ (y\) ">70 | \ (x^2\) ">36 | \ (xy\) ">420 | \ (y^2\) ">4900 | \ (x\) ">3 | \ (y\) ">68 | \ (x^2\) ">9 | \ (xy\) ">204 | \ (y^2\) ">4624 |
| \ (x\) ">2 | \ (y\) ">80 | \ (x^2\) ">4 | \ (xy\) ">160 | \ (y^2\) ">6400 | \ (x\) ">1 | \ (y\) ">84 | \ (x^2\) ">1 | \ (xy\) ">84 | \ (y^2\) ">7056 |
| \ (x\) ">2 | \ (y\) ">75 | \ (x^2\) ">4 | \ (xy\) ">150 | \ (y^2\) ">5625 | \ (x\) ">3 | \ (y\) ">80 | \ (x^2\) ">9 | \ (xy\) ">240 | \ (y^2\) ">6400 |
| \ (x\) ">1 | \ (y\) ">63 | \ (x^2\) ">1 | \ (xy\) ">63 | \ (y^2\) ">3969 | \ (x\) ">1 | \ (y\) ">78 | \ (x^2\) ">1 | \ (xy\) ">78 | \ (y^2\) ">6084 |
Sumando los números en cada columna en la Tabla\(\PageIndex{2}\) da
Entonces
\[SS_{xx}=\sum x^2-\frac{1}{n}\left ( \sum x \right )^2=329-\frac{1}{26}(71)^2=135.1153846\\ SS_{xy}=\sum xy-\frac{1}{n}\left ( \sum x \right )\left ( \sum y \right )=4758-\frac{1}{26}(71)(2001)=-706.2692308\\ SS_{yy}=\sum y^2-\frac{1}{n}\left ( \sum y \right )^2=161511-\frac{1}{26}(2001)^2=7510.961538\]
y
\[\bar{x}=\frac{\sum x}{n}=\frac{71}{26}=2.730769231\; \; and\; \; \bar{y}=\frac{\sum y}{n}=\frac{2001}{26}=76.96153846\]
Comenzamos el modelado real encontrando la línea de regresión de mínimos cuadrados, la línea que mejor se ajusta a los datos. Su pendiente e\(y\) intercepción son
\[\hat{\beta _1}=\frac{SS_{xy}}{SS_{xx}}=\frac{-706.2692308}{135.1153846}=-5.227156278\]
\[\hat{\beta _0}=\bar{y}-\hat{\beta _1}\bar{x}=76.96153846-(-5.227156278)(2.730769231)=91.23569553\]
Redondeando estos números a dos decimales, la línea de regresión de mínimos cuadrados para estos datos es
\[\hat{y}=-5.23 x+91.24\]
La bondad de ajuste de esta línea al diagrama de dispersión, la suma de sus errores cuadrados, es
\[SSE=SS_{yy}-\hat{\beta _1}SS_{xy}=7510.961538-(-5.227156278)(-706.2692308)=3819.181894\]
Este número no es particularmente informativo en sí mismo, pero lo usamos para calcular la estadística importante
\[S_\varepsilon =\sqrt{\frac{SSE}{n-2}}=\sqrt{\frac{3819.181894}{24}}=12.11988495\]
El estadístico\(S_\varepsilon\) estima la desviación estándar\(\sum\) de la variable aleatoria normal\(\varepsilon\) en el modelo. Su significado es que entre todos los alumnos con el mismo número de ausencias, la desviación estándar de sus puntuaciones en el examen final es sobre\(12.1\) puntos. Un valor tan grande en un examen\(100\) de punto significa que los puntajes finales de cada subpoblación de estudiantes, basados en el número de ausencias, son muy variables.
El tamaño y la señal de la pendiente\(βˆ1=−5.23\) indican que, por cada clase faltada, los estudiantes tienden a anotar aproximadamente\(5.23\) menos puntos más bajos en el examen final en promedio. De manera similar por cada dos clases perdidas los estudiantes tienden a anotar en promedio\(2\times 5.23=10.46\) menos puntos en el examen final, o sobre una nota letra peor en promedio.
Dado que\(0\) está en el rango de\(x\) -valores en el conjunto de datos, el\(y\) -intercept también tiene significado en este problema. Se trata de una estimación de la nota promedio en el examen final de todos los alumnos que tengan una asistencia perfecta. El promedio pronosticado de tales estudiantes es\(\hat{\beta _0}=91.24\).
Antes de usar más la ecuación de regresión, o realizar otros análisis, sería una buena idea examinar la utilidad del modelo de regresión lineal. Esto lo podemos hacer de dos maneras: 1) calculando el coeficiente de correlación\(r\) para ver qué tan fuertemente se correlacionan el número de ausencias\(x\) y la puntuación\(y\) en el examen final, y 2) probando la hipótesis nula\(H_0: \hat{\beta _1}=0\) (la pendiente de la línea de regresión poblacional es cero, entonces \(x\)no es un buen predictor de\(y\)) frente a la alternativa natural\(H_a: \hat{\beta _1}<0\) (la pendiente de la línea de regresión poblacional es negativa, por lo que los puntajes finales de los exámenes\(y\) bajan a medida que suben las ausencias\(x\)).
El coeficiente de correlación\(r\) es
\[r=\frac{SS_{xy}}{\sqrt{SS_{xx}SS_{yy}}}=\frac{-706.2692308}{\sqrt{(135.1153846)(7510.961538)}}=-0.7010840977\]
una correlación negativa moderada.
Pasando a la prueba de hipótesis, probemos en el\(5\%\) nivel de significancia comúnmente utilizado. La prueba es
\[H_0: \beta _1=0\\ vs.\\ H_a: \beta _1<0\; \; @\; \; \alpha =0.05\]
De la Figura 7.1.6, con\(df=26-2=24\) grados de libertad\(t_{0.05}=1.711\), por lo que es la región de rechazo\((-\infty ,-1.711]\). El valor del estadístico de prueba estandarizado es
\[t=\frac{\hat{\beta _1}-B_0}{S_\varepsilon /\sqrt{SS_{xx}}}=\frac{-5.227156278-0}{12.11988495/\sqrt{135.1153846}}=-5.013\]
que cae en la región de rechazo. Rechazamos\(H_0\) a favor de\(H_a\). Los datos proporcionan evidencia suficiente, a\(5\%\) nivel de significancia, para concluir que\(β_1\) es negativo, es decir, que a medida que aumenta el número de ausencias la puntuación promedio en el examen final disminuye.
Como ya se señaló, el valor\(β_1=-5.23\) da una estimación puntual de cuánto se refleja una ausencia adicional en la puntuación promedio del examen final. Por cada ausencia adicional el promedio baja en aproximadamente\(5.23\) puntos. Podemos ampliar esta estimación de punto a un intervalo de confianza para\(β_1\). A nivel de\(95\%\) confianza, a partir de la Figura 7.1.6 con\(df=26-2=24\) grados de libertad,\(t_{\alpha /2}=t_{0.025}=2.064\). El intervalo de\(95\%\) confianza para\(β_1\) basado en nuestros datos de muestra es
\[\hat{\beta _1}\pm t_{\alpha /2}\tfrac{S_\varepsilon }{\sqrt{SS_{xx}}}=-5.23\pm 2.064\tfrac{12.11988495}{\sqrt{135.1153846}}=-5.23\pm 2.15\]
o\((-7.38,-3.08)\). Estamos\(95\%\) seguros de que, entre todos los estudiantes que alguna vez toman este curso, por cada clase adicional se perdió la puntuación promedio en el examen final baja por entre\(3.08\) y\(7.38\) puntos.
Si restringimos la atención a la subpoblación de todos los estudiantes que tienen exactamente cinco ausencias, digamos, entonces usando la ecuación de regresión de mínimos cuadrados\(\hat{y}=-5.23x+91.24\) estimamos que la puntuación promedio en el examen final para esos estudiantes es
\[\hat{y}=-5.23(5)+91.24=65.09\]
Esta es también nuestra mejor suposición en cuanto a la puntuación en el examen final de cualquier estudiante en particular que esté ausente cinco veces. Un intervalo de\(95\%\) confianza para la puntuación promedio en el examen final para todos los estudiantes con cinco ausencias es
\[\begin{align*} \hat{y_p}\pm t_{\alpha /2}S_\varepsilon \sqrt{\frac{1}{n}+\frac{(x_p-\bar{x})^2}{SS_{xx}}} &= 65.09\pm (2.064)(12.11988495)\sqrt{\frac{1}{26}+\frac{(5-2.730769231)^2}{135.1153846}}\\ &= 65.09\pm 25.01544254\sqrt{0.0765727299}\\ &= 65.09\pm 6.92 \end{align*}\]
que es el intervalo\((58.17,72.01)\). Este intervalo de confianza sugiere que la verdadera puntuación media en el examen final para todos los estudiantes que están ausentes de clase exactamente cinco veces durante el semestre es probable que esté entre\(58.17\) y\(72.01\).
Si un alumno en particular pierde exactamente cinco clases durante el semestre, su puntaje en el examen final se predice con\(95\%\) confianza para estar en el intervalo
\[\begin{align*} \hat{y_p}\pm t_{\alpha /2}S_\varepsilon \sqrt{1+\frac{1}{n}+\frac{(x_p-\bar{x})^2}{SS_{xx}}} &= 65.09\pm 25.01544254\sqrt{1.0765727299}\\ &= 65.09\pm 25.96 \end{align*}\]
que es el intervalo\((39.13,91.05)\). Este intervalo de predicción sugiere que es probable que la puntuación final del examen de este estudiante individual esté entre\(39.13\) y\(91.05\). Mientras que el intervalo de\(95\%\) confianza para el puntaje promedio de todos los estudiantes con cinco ausencias dio información real, este intervalo es tan amplio que prácticamente no dice nada sobre cuál podría ser el puntaje del examen final del alumno individual. Este es un ejemplo del efecto dramático que puede tener la presencia del summand extra\(1\) bajo el signo cuadrado en el intervalo de predicción.
Por último, la proporción de la variabilidad en las puntuaciones de los alumnos en el examen final que se explica por la relación lineal entre esa puntuación y el número de ausencias se estima por el coeficiente de determinación,\(r^2\). Como ya hemos calculado r arriba, encontramos fácilmente que
\[r^2=(-0.7010840977)^2=0.491518912\]
o sobre\(49\%\). Así, aunque existe una correlación significativa entre la asistencia y el rendimiento en el examen final, y podemos estimar con justa exactitud la puntuación promedio de los alumnos que falten a cierto número de clases, sin embargo menos de la mitad de la variación total de las puntuaciones de los exámenes en la muestra se explica por la número de ausencias. Esto no debería ser una sorpresa, ya que hay muchos factores además de la asistencia que inciden en el desempeño de los estudiantes en los exámenes.
Llave para llevar
- Es una buena idea asistir a clase.
