
8.2: Formatos de matriz dispersa
- Page ID
- 124939

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
8.2.1 Lista de Listas (LIL)
El formato de matriz dispersa Lista de listas (que es, por alguna razón desconocida, abreviado como LIL en lugar de LOL) es uno de los formatos de matriz dispersa más simples. Se muestra esquemáticamente en la siguiente figura. Cada fila de matriz distinta de cero está representada por un elemento en una especie de estructura de lista llamada “lista enlazada”. Cada elemento de la lista enlazada registra el número de fila y los datos de columna para las entradas de la matriz en esa fila. Los datos de columna consisten en una lista, donde cada elemento de lista corresponde a un elemento de matriz distinto de cero, y almacena información sobre (i) el número de columna y (ii) el valor del elemento de matriz.
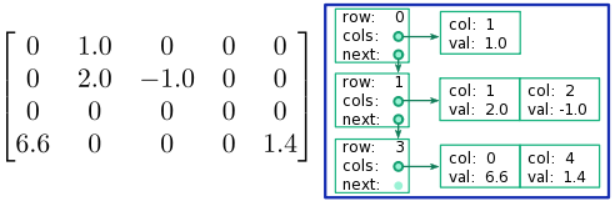
Evidentemente, este formato es bastante eficiente en la memoria. La lista de filas solo necesita ser tan larga como el número de filas de matriz distintas de cero; el resto se omite. Asimismo, cada lista de datos de columna solo necesita ser tan larga como el número de elementos distintos de cero en esa fila. La cantidad total de memoria requerida es proporcional al número de elementos distintos de cero, independientemente del tamaño de la propia matriz.
Comparado con los otros formatos de matriz dispersos que discutiremos, acceder a un elemento de matriz individual en formato LIL es relativamente lento. Esto se debe a que buscar un índice de matriz dado\((i,j)\) requiere pasar por la lista de filas para encontrar un elemento con índice de fila\(i\); y si se encuentra uno, recorrer la fila de columna para encontrar el índice\(j\). Así, por ejemplo, ¡buscar un elemento en una\(N\times N\) matriz diagonal en el formato LIL lleva\(O(N)\) tiempo! Como veremos, los formatos CSR y CSC son mucho más eficientes en el acceso a elementos. Por la misma razón, la aritmética matricial en el formato LIL es muy ineficiente.
Una ventaja del formato LIL, sin embargo, es que es relativamente fácil alterar la “estructura dispersa” de la matriz. Para agregar un nuevo elemento distinto de cero, uno simplemente tiene que recorrer la lista de filas, y o bien (i) insertar un nuevo elemento en la lista enlazada si la fila no estaba previamente en la lista (esta inserción lleva\(O(1)\) tiempo), o (ii) modificar la lista de columnas (que suele ser muy corta si la matriz es muy escasa).
Por esta razón, se prefiere el formato LIL si se necesita construir una matriz dispersa donde los elementos distintos de cero no se distribuyan en ningún patrón útil. Una forma es crear una matriz vacía, luego rellenar los elementos uno por uno, como se muestra en el siguiente ejemplo. La matriz LIL es creada por la función lil_matrix, que es proporcionada por el módulo scipy.sparse.
Aquí hay un programa de ejemplo que construye una matriz LIL y la imprime:
from scipy import * import scipy.sparse as sp A = sp.lil_matrix((4,5)) # Create empty 4x5 LIL matrix A[0,1] = 1.0 A[1,1] = 2.0 A[1,2] = -1.0 A[3,0] = 6.6 A[3,4] = 1.4 ## Verify the matrix contents by printing it print(A)
Cuando ejecutamos el programa anterior, muestra los elementos distintos de cero de la matriz dispersa:
(0, 1) 1.0 (1, 1) 2.0 (1, 2) -1.0 (3, 0) 6.6 (3, 4) 1.4
También puede convertir la matriz dispersa en una matriz 2D convencional, usando el método toarray. Supongamos que reemplazamos la línea de impresión (A) en el programa anterior con
B = A.toarray() print(B)
El resultado es:
[[ 0. 1. 0. 0. 0. ] [ 0. 2. -1. 0. 0. ] [ 0. 0. 0. 0. 0. ] [ 6.6 0. 0. 0. 1.4]]
Nota: tenga cuidado al llamar a toarray en código real. Si la matriz es enorme, la matriz 2D consumirá cantidades irrazonables de memoria. No es raro trabajar con matrices escasas con tamaños del orden de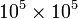 , que pueden ocupar menos 1 MB de memoria en un formato escaso, ¡pero alrededor de 80 GB de memoria en formato de matriz!
, que pueden ocupar menos 1 MB de memoria en un formato escaso, ¡pero alrededor de 80 GB de memoria en formato de matriz!
8.2.2 Almacenamiento Diagonal (DIA)
El formato de Almacenamiento Diagonal (DIA) almacena el contenido de una matriz dispersa a lo largo de sus diagonales. Hace uso de una matriz 2D, que denotamos por datos, y una matriz de enteros 1D, que denotamos por compensaciones. Un ejemplo típico se muestra en la siguiente figura:

Cada fila de la matriz de datos almacena una de las diagonales de la matriz, y los desplazamientos [i] registran a qué diagonal corresponde esa fila de los datos, con “desplazamiento 0" correspondiente a la diagonal principal. Por ejemplo, en el ejemplo anterior, fila\(0\) de datos contiene las entradas [6.6,0,0,0,0]), y offsets [0] contiene el valor\(-3\), indicando que la entrada\(6.6\) ocurre a lo largo de la\(-3\) subdiagonal, en columna\(0\). (Los elementos adicionales en esa fila de datos se encuentran fuera de los límites de la matriz y se ignoran). Se omiten las diagonales que contienen solo cero.
Para matrices dispersas con muy pocas diagonales distintas de cero, como matrices diagonales o tridiagonales, el formato DIA permite operaciones aritméticas muy rápidas. Su principal limitación es que buscar cada elemento de la matriz requiere realizar una búsqueda ciega a través de la matriz de compensaciones. Eso está bien si hay muy pocas diagonales distintas de cero, ya que las compensaciones serán pequeñas. Pero si el número de diagonales distintas de cero se vuelve grande, el rendimiento se vuelve muy pobre. En el peor de los casos de una matriz antidiagonal, ¡la búsqueda de elementos lleva\(O(N)\) tiempo!
Puede crear una matriz dispersa en el formato DIA, usando la función dia_matrix, que es proporcionada por el módulo scipy.sparse. Aquí hay un programa de ejemplo:
from scipy import * import scipy.sparse as sp N = 6 # Matrix size diag0 = -2 * ones(N) diag1 = ones(N) A = sp.dia_matrix(([diag1, diag0, diag1], [-1,0,1]), shape=(N,N)) ## Verify the matrix contents by printing it print(A.toarray())
Aquí, la primera entrada a dia_matrix es una tupla de la forma (data, offsets), donde data y offsets son arrays del tipo descrito anteriormente. Esto devuelve una matriz dispersa en el formato DIA, con el contenido especificado (se ignoran los elementos en los datos que se encuentran fuera de los límites de la matriz). En este ejemplo, la matriz es tridiagonal con -2 a lo largo de la diagonal principal y 1 a lo largo de las diagonales +1 y -1. Al ejecutar el programa anterior se imprime lo siguiente:
[[-2. 1. 0. 0. 0. 0.] [ 1. -2. 1. 0. 0. 0.] [ 0. 1. -2. 1. 0. 0.] [ 0. 0. 1. -2. 1. 0.] [ 0. 0. 0. 1. -2. 1.] [ 0. 0. 0. 0. 1. -2.]]
Otra forma de crear una matriz DIA es crear primero una matriz en otro formato (por ejemplo, una matriz 2D convencional), y proporcionarla como la entrada a dia_matrix. Esto devuelve una matriz dispersa con el mismo contenido, en formato DIA.
8.2.3 Fila dispersa comprimida (CSR)
El formato de fila dispersa comprimida (CSR) representa una matriz dispersa usando tres matrices, que denotamos por datos, índices e indptr. Un ejemplo se muestra en la siguiente figura:

La matriz denotada data almacena los valores de los elementos distintos de cero de la matriz, en orden secuencial de izquierda a derecha a lo largo de cada fila, luego de la fila superior a la inferior. La matriz denotada índices registra el índice de columna para cada uno de estos elementos. En el ejemplo anterior, data [3] almacena un valor de\(6.6\), e indices [3] tiene un valor de\(0\), indicando que un elemento de matriz con valor\(6.6\) se produce en columna\(0\). Estas dos matrices tienen la misma longitud, igual al número de elementos distintos de cero en la matriz dispersa.
La matriz denotada indptr (que significa “puntero índice”) proporciona una asociación entre los índices de fila y los elementos de la matriz, pero de manera indirecta. Su longitud es igual al número de filas de matriz (incluidas las filas cero). Para cada fila\(i\), si la fila es distinta de cero, indptr [i] registra el índice en las matrices de datos e índices correspondientes al primer elemento distinto de cero en la fila\(i\). (Para una fila cero, indptr registra el índice del siguiente elemento distinto de cero que ocurre en la matriz).
Por ejemplo, considere buscar índice\((1,2)\) en la figura anterior. El índice de fila es 1, por lo que examinamos indptr [1] (cuyo valor es\(1\)) e indptr [2] (cuyo valor es\(3\)). Esto significa que los elementos distintos de cero para la fila de la matriz\(1\) corresponden a índices\(1 \le n < 3\) de las matrices de datos e índices. Buscamos índices [1] e índices [2], buscando un índice de columna de\(2\). Esto se encuentra en los índices [2], por lo que buscamos en los datos [2] el valor del elemento matriz, que es\(-1.0\).
Es claro que buscar un elemento de matriz individual es muy eficiente. A diferencia del formato LIL, donde necesitamos pasar por una lista enlazada, en el formato CSR la matriz indptr nos permite saltar directamente a los datos para la fila relevante. Por la misma razón, el formato CSR es eficiente para operaciones de corte de filas (por ejemplo, A [4,:]), y para productos matriz-vector como\(\mathbf{A}\vec{x}\) (lo que implica tomar el producto de cada fila de matriz con el vector\(\vec{x}\)).
El formato CSR tiene varias desventajas. El corte de columnas (por ejemplo, A [:,4]) es ineficiente, ya que requiere buscar en todos los elementos de la matriz de índices el índice de columna relevante. Los cambios en la estructura dispersa (por ejemplo, insertar nuevos elementos) también son muy ineficientes, ya que las tres matrices necesitan ser reordenadas.
Para crear una matriz dispersa en el formato CSR, utilizamos la función csr_matrix, que es proporcionada por el módulo scipy.sparse. Aquí hay un programa de ejemplo:
from scipy import * import scipy.sparse as sp data = [1.0, 2.0, -1.0, 6.6, 1.4] rows = [0, 1, 1, 3, 3] cols = [1, 1, 2, 0, 4] A = sp.csr_matrix((data, [rows, cols]), shape=(4,5)) print(A)
Aquí, la primera entrada a csr_matrix es una tupla de la forma (data, idx), donde data es una matriz 1D que especifica los elementos de matriz distintos de cero, idx [0,:] especifica los índices de fila e idx [1,:] especifica los índices de columna. Al ejecutar el programa se obtienen los resultados esperados:
(0, 1) 1.0 (1, 1) 2.0 (1, 2) -1.0 (3, 0) 6.6 (3, 4) 1.4
La función csr_matrix calcula y genera las tres matrices de CSR automáticamente; no es necesario que las resuelvas tú mismo. Pero si lo desea, puede inspeccionar el contenido de las matrices CSR directamente:
>>> A.data array([ 1. , 2. , -1. , 6.6, 1.4]) >>> A.indices array([1, 1, 2, 0, 4], dtype=int32) >>> A.indptr array([0, 1, 3, 3, 5], dtype=int32)
(Hay un elemento final adicional de\(5\) en la matriz indptr. Por simplicidad, no mencionamos esto en la discusión anterior, pero deberías poder averiguar por qué está ahí).
Otra forma de crear una matriz CSR es crear primero una matriz en otro formato (por ejemplo, una matriz 2D convencional, o una matriz dispersa en formato LIL), y proporcionarla como la entrada a csr_matrix. Esto devuelve la matriz especificada en formato CSR. Por ejemplo:
>>> A = sp.lil_matrix((6,6)) >>> A[0,1] = 4.0 >>> A[2,0] = 5.0 >>> B = sp.csr_matrix(A)
8.2.4 Columna dispersa comprimida (CSC)
El formato de columna dispersa comprimida (CSC) es muy similar al formato CSR, excepto que se intercambia el rol de filas y columnas. La matriz de datos almacena elementos de matriz distintos de cero en orden secuencial de arriba a abajo a lo largo de cada columna, luego de la columna más a la izquierda a la más derecha. La matriz de índices almacena índices de fila, y cada elemento de la matriz indptr corresponde a una columna de la matriz. A continuación se muestra un ejemplo:

El formato CSC es eficiente en la búsqueda de matriz, operaciones de corte de columnas (por ejemplo, A [:,4]) y productos vector-matriz como\(\vec{x}^{\,T} \mathbf{A}\) (lo que implica tomar el producto del vector\(\vec{x}\) con cada columna de matriz). Sin embargo, es ineficiente para el corte en hileras (por ejemplo, A [4,:]) y para los cambios en la estructura dispersa.
Para crear una matriz dispersa en el formato CSC, usamos la función csc_matrix. Esto es análogo a la función csr_matrix para matrices CSR. Por ejemplo,
>>> from scipy import * >>> import scipy.sparse as sp >>> data = [1.0, 2.0, -1.0, 6.6, 1.4] >>> rows = [0, 1, 1, 3, 3] >>> cols = [1, 1, 2, 0, 4] >>> >>> A = sp.csc_matrix((data, [rows, cols]), shape=(4,5)) >>> A <4x5 sparse matrix of type '<class 'numpy.float64'>' with 5 stored elements in Compressed Sparse Column format>