
7.2: Análisis de múltiples capas
- Page ID
- 88801
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
- El objetivo de esta sección es familiarizarse con conceptos y términos relacionados con la implementación de operaciones básicas de múltiples capas y metodologías utilizadas en datasets de entidades vectoriales.
Entre las herramientas más potentes y comúnmente utilizadas en un sistema de información geográfica (SIG) se encuentra la superposición de información cartográfica. En un SIG, una superposición es el proceso de tomar dos o más mapas temáticos diferentes de la misma área y colocarlos uno encima del otro para formar un nuevo mapa (Figura 7.4 “Una superposición de mapa que combina información de capas vectoriales de punto, línea y polígono, así como capas ráster”). Inherente a este proceso, la función de superposición combina no solo las entidades espaciales del dataset sino también la información de atributos.
Figura 7.4 Una superposición de mapa que combina información de capas vectoriales de punto, línea y polígono, así como capas ráster

Un ejemplo común utilizado para ilustrar el proceso de superposición es: “¿Dónde está el mejor lugar para poner un centro comercial?” Imagina que eres un bigwig corporativo y tienes la tarea de determinar dónde se ubicará el próximo centro comercial de tu empresa. ¿Cómo atacarías este problema? Con un SIG a sus órdenes, responder tales preguntas espaciales comienza con la acumulación y superposición de capas de datos espaciales pertinentes. Por ejemplo, es posible que primero desee determinar qué áreas pueden soportar el centro comercial acumulando información sobre qué parcelas de tierra están a la venta y cuáles están divididas por zonas para el desarrollo comercial. Después de recopilar y superponer la información de línea base sobre las zonas de desarrollo disponibles, puede comenzar a determinar qué áreas ofrecen la mayor oportunidad económica al recopilar información regional sobre el ingreso promedio de los hogares, la densidad de población, la ubicación de los centros comerciales proximales, los hábitos de compra locales y más. A continuación, es posible que desee recopilar información sobre restricciones o bloqueos viales al desarrollo, como el costo de la tierra, el costo para desarrollar el terreno, la respuesta comunitaria al desarrollo, la adecuación de los corredores de transporte hacia y desde el centro comercial propuesto, las tasas impositivas, etc. De hecho, simplemente recopilar y superponer conjuntos de datos espaciales proporciona una valiosa herramienta para visualizar y seleccionar el sitio óptimo para tal empresa.
Operaciones de superposición
Varios procesos básicos de superposición están disponibles en un SIG para datasets vectoriales: punto en polígono, polígono-en-punto, línea en línea, línea en polígono, polígono en línea y polígono-polígono. Como puede ser capaz de adivinar a partir de los nombres, uno de los dataset de superposición siempre debe ser una capa de línea o polígono, mientras que la segunda puede ser punto, línea o polígono. La nueva capa producida después de la operación de superposición se denomina capa de “salida”.
La operación de superposición de punto en polígono requiere una capa de entrada de puntos y una capa de superposición de polígonos. Al realizar esta operación, se devuelve una nueva capa de puntos de salida que incluye todos los puntos que ocurren dentro de la extensión espacial de la superposición (Figura 7.4 “Una superposición de mapa que combina información de capas vectoriales de punto, línea y polígono, así como capas ráster”). Además, todos los puntos de la capa de salida contienen su información de atributo original así como la información de atributo de la superposición. Por ejemplo, supongamos que se le asignó la tarea de determinar si una especie en peligro de extinción que reside en un parque nacional se encontró principalmente en una comunidad de vegetación en particular. El primer paso sería adquirir los lugares de ocurrencia puntual para la especie en cuestión, más una capa de superposición poligonal que muestre las comunidades de vegetación dentro del límite del parque nacional. Al realizar la operación de superposición de punto en polígono, se crea un nuevo archivo de puntos que contiene todos los puntos que ocurren dentro del parque nacional. La tabla de atributos de este archivo de puntos de salida también contendría información sobre las comunidades de vegetación utilizadas por la especie en el momento de la observación. Un escaneo rápido de esta capa de salida y su tabla de atributos permitiría determinar dónde se encontró la especie en el parque y revisar las comunidades de vegetación en las que ocurrió. Este proceso permitiría a los empleados del parque tomar decisiones informadas de manejo con respecto a qué hábitats in situ proteger para garantizar la utilización continua del sitio por parte de la especie.
Figura 7.5 Overlay de punto en polígono
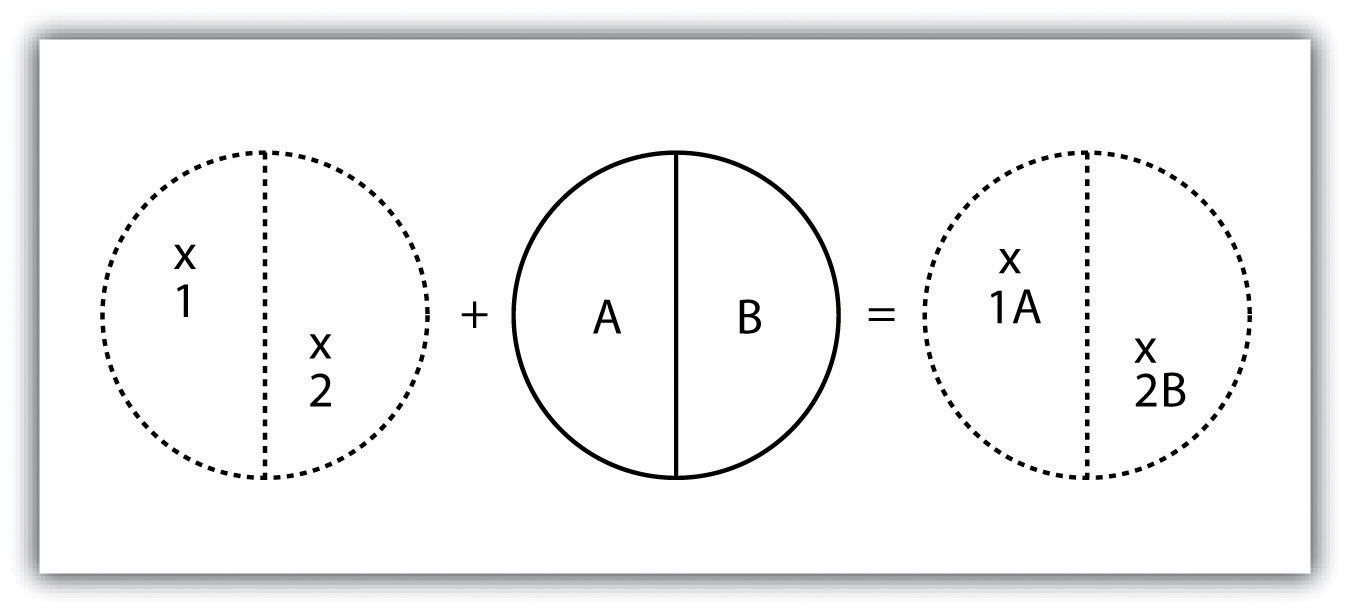
Como su nombre indica, la operación de superposición polígono-punto es la opuesta a la operación punto en polígono. En este caso, la capa poligonal es la entrada, mientras que la capa de puntos es la superposición. Las entidades poligonales que superponen estos puntos se seleccionan y posteriormente se conservan en la capa de salida. Por ejemplo, dado un conjunto de datos de puntos que contiene las ubicaciones de algún tipo de delito y un conjunto de datos de polígonos que representan bloques de ciudades, una operación de superposición polígono-punto permitiría a la policía seleccionar las manzanas de la ciudad en las que se sabe que ocurren los delitos y, por lo tanto, determinar aquellas ubicaciones donde un aumento de la policía se puede garantizar la presencia.
Figura 7.6 Sobreposición de polígono sobre punto

Una operación de superposición de línea en línea requiere entidades de línea tanto para la capa de entrada como de superposición. El resultado de esta operación es un punto o puntos ubicados precisamente en la (s) intersección (es) de los dos datasets lineales (Figura 7.7 “Superposición de línea en línea”). Por ejemplo, un dataset de entidades lineales que contiene vías de ferrocarril puede superponerse en la red de carreteras lineales. El dataset de puntos resultante contiene todas las regiones de los cruces ferroviarios sobre la red de carreteras de una ciudad. La tabla de atributos para este dataset de puntos de cruce ferroviario contendría información tanto sobre el ferrocarril como sobre la carretera por la que pasó.
Figura 7.7 Overlay de línea en línea

La operación de superposición de línea en polígono es similar a la superposición de punto en polígono, con la obvia excepción de que se usa una capa de entrada de línea en lugar de una capa de entrada de punto. En este caso, cada línea que tenga alguna parte de su extensión dentro de la capa poligonal superpuesta se incluirá en la capa de líneas de salida, aunque estas líneas se truncarán en el límite de la superposición (Figura 7.9 “Superposición polígono-en-línea”). Por ejemplo, una superposición de línea en polígono puede tomar una capa de entrada de segmentos de línea interestatales y una superposición de polígonos que representan los límites de la ciudad y producir una capa de salida lineal de segmentos de carretera que se encuentran dentro del límite de la ciudad. La tabla de atributos para el segmento de línea interestatal de salida contendrá información sobre el nombre interestatal así como la ciudad por la que pasan.
Figura 7.8 superposición de línea en polígono

La operación de superposición de polígonos en línea es la opuesta a la operación de línea en polígono. En este caso, la capa poligonal es la entrada, mientras que la capa de línea es la superposición. Las entidades poligonales que superponen estas líneas se seleccionan y posteriormente se conservan en la capa de salida. Por ejemplo, dada una capa que contiene la ruta de una serie de polos/cables telefónicos y un mapa poligonal contiene parcelas de ciudad, una operación de superposición de polígonos en línea permitiría a un asesor de terrenos seleccionar aquellas parcelas que contienen cables telefónicos aéreos.
Figura 7.9 Overlay de polígonos en línea

Finalmente, la operación de superposición polígono-en-polígono emplea una entrada de polígono y una superposición de polígono. Esta es la operación de superposición más utilizada. Usando este método, las capas de entrada y superposición de polígonos se combinan para crear una capa de polígono de salida con la extensión de la superposición. La tabla de atributos contendrá datos espaciales e información de atributos tanto de las capas de entrada como de superposición (Figura 7.10 “Superposición de polígonos en polígonos”). Por ejemplo, puede elegir una capa de polígono de entrada de tipos de suelo con una superposición de campos agrícolas dentro de un condado determinado. La capa poligonal de salida contendría información tanto sobre la ubicación de los campos agrícolas como sobre los tipos de suelo en todo el condado.
Figura 7.10 Overlay Polígono-en-Polígono

Las operaciones de superposición discutidas anteriormente suponen que el usuario desea combinar las capas superpuestas. No siempre es así. Los métodos de superposición pueden ser más complejos que eso y por lo tanto emplean los operadores booleanos básicos: AND, OR y XOR (ver Sección 6.1.2 “Medidas de Tendencia Central”). Dependiendo de qué operador o operadores se utilicen, el método de superposición empleado dará como resultado una intersección, unión, diferencia simétrica o identidad.
Específicamente, el método de superposición de unión emplea al operador OR. Una unión solo se puede usar en el caso de dos capas de entrada de polígonos. Conserva todas las entidades, información de atributos y extensiones espaciales de ambas capas de entrada (parte (a) de la Figura 7.11 “Métodos de superposición vectorial “). Este método de superposición se basa en la operación polígono-en-polígono descrita en la Sección 7.1.1 “Búfer”.
Alternativamente, el método de superposición de intersección emplea el operador AND. Una intersección requiere una superposición de polígono, pero puede aceptar una entrada de punto, línea o polígono. La capa de salida cubre la extensión espacial de la superposición y contiene entidades y atributos tanto de la entrada como de la superposición (parte (b) de la Figura 7.11 “Métodos de superposición vectorial “).
El método de superposición de diferencias simétricas emplea el operador XOR, lo que da como resultado la salida opuesta como una intersección. Este método requiere que ambas capas de entrada sean polígonos. La capa poligonal de salida producida por el método de diferencia simétrica representa aquellas áreas comunes a solo uno de los datasets de entidades (parte (c) de la Figura 7.11 “Métodos de superposición vectorial “).
Además de estas operaciones simples, el método de superposición de identidad (también denominado “menos”) crea una capa de salida con la extensión espacial de la capa de entrada (parte (d) de la Figura 7.11 “Métodos de superposición vectorial “) pero incluye información de atributos de la superposición (denominada “identidad” capa, en este caso). La capa de entrada puede ser puntos, líneas o polígonos. La capa de identidad debe ser un dataset poligonal.
Figura 7.11 Métodos de superposición vectorial

Otras opciones de geoprocesamiento multicapa
Además de los métodos de superposición vectorial mencionados, otras opciones comunes de geoprocesamiento de múltiples capas están disponibles para el usuario. Estas incluían las herramientas de clip, borrado y división. La operación de geoprocesamiento de clips se utiliza para extraer esas entidades de una capa de punto, línea o polígono de entrada que se encuentra dentro de la extensión espacial de la capa de clip (parte (e) de la Figura 7.11 “Métodos de superposición vectorial “). Después del clip, todos los atributos de la parte conservada de la capa de entrada se incluyen en la salida. Si se selecciona alguna entidad durante este proceso, solo las entidades seleccionadas dentro del límite de delimitación se incluirán en la salida. Por ejemplo, la herramienta de clip podría usarse para recortar la extensión de una llanura aluvial fluvial por la extensión de un límite de condado. Esto proporcionaría a los administradores del condado una idea de qué partes de la llanura aluvial son responsables de mantener. Esto es similar al método de superposición de intersección; sin embargo, la información de atributo asociada con la capa de clip no se transporta a la capa de salida después de la superposición.
La operación de geoprocesamiento de borrado es esencialmente lo contrario de un clip. Mientras que la herramienta de clip conserva áreas dentro de una capa de entrada, la herramienta de borrado conserva solo aquellas áreas fuera de la extensión de la capa de borrado análoga (parte (f) de la Figura 7.11 “Métodos de superposición vectorial “). Si bien la capa de entrada puede ser un dataset de punto, línea o polígono, la capa de borrado debe ser un dataset poligonal. Continuando con nuestro ejemplo de clip, los gerentes del condado podrían usar la herramienta de borrado para borrar las áreas de propiedad privada dentro del área de llanura aluvial del condado. Los funcionarios podrían entonces enfocarse específicamente en los alcances públicos de la llanura aluvial en todo el condado para sus responsabilidades de mantenimiento y mantenimiento.
La operación de geoprocesamiento dividido se utiliza para dividir una capa de entrada en dos o más capas basadas en una capa dividida (parte (g) de la Figura 7.11 “Métodos de superposición vectorial “). La capa dividida debe ser un polígono, mientras que las capas de entrada pueden ser de punto, línea o polígono. Por ejemplo, una asociación de propietarios puede optar por dividir un mapa de series de suelos de todo el condado por los límites de las parcelas para que cada propietario tenga un mapa de suelo específico para su propia parcela.
Unión espacial
Una unión espacial es un híbrido entre una operación de atributo y una operación de superposición vectorial. Al igual que la operación de atributo “unir” descrita en la Sección 5.2.2 “Uniones y relaciones”, una combinación espacial da como resultado la combinación de dos tablas de dataset de entidades por un campo de atributo común. A diferencia de la operación de atributos, una unión espacial determina qué campos de la tabla de atributos de una capa de origen se anexan a la tabla de atributos de la capa de destino en función de las ubicaciones relativas de las entidades seleccionadas. Esta relación se basa explícitamente en la propiedad de proximidad o contención entre las capas de origen y destino, en lugar de las claves primarias o secundarias. La opción de proximidad se utiliza cuando la capa de origen es un dataset de entidades de punto o línea, mientras que la opción de contención se usa cuando la capa de origen es un dataset de entidades poligonales.
Cuando se emplea la opción de proximidad (o “más cercana”), se agrega un registro para cada entidad en la tabla de atributos de la capa de origen a la entidad dada más cercana en la tabla de atributos de la capa de destino. La opción de proximidad normalmente agregará un campo numérico a la tabla de atributos de la capa de destino, llamado “Distancia”, dentro de la cual se coloca la distancia medida entre la entidad de origen y destino. Por ejemplo, supongamos que una agencia de la ciudad tiene un conjunto de datos de puntos que muestra todos los contaminadores conocidos en la ciudad y un conjunto de datos de líneas de todos los segmentos de río dentro del límite Esta agencia podría entonces realizar una unión espacial basada en proximidad para determinar el segmento fluvial más cercano que probablemente se vería afectado por cada contaminador.
Cuando se utiliza la opción de contención (o “dentro”), se agrega un registro para cada entidad en la tabla de atributos de la capa de origen del polígono al registro en la tabla de atributos de la capa de destino que contiene. Si una entidad de capa de destino (punto, línea o polígono) no está completamente contenida dentro de un polígono de origen, no se agregará ningún valor. Por ejemplo, supongamos que un negocio de limpieza de piscinas quería perfeccionar sus servicios de marketing proporcionando volantes solo a casas que poseían una piscina. Podrían obtener un dataset de puntos que contiene la ubicación de cada grupo en el condado y un mapa de parcelas poligonales para esa misma área. Ese negocio podría entonces realizar una unión espacial para agregar la información de la parcela a las regiones del grupo. Esto les proporcionaría información sobre cada parcela de tierra que contenía una alberca y posteriormente podrían enviar sus mailers únicamente a esas viviendas.
Errores de superposición
Aunque las superposiciones son una de las herramientas más importantes en la caja de herramientas de un analista de SIG, existen algunos problemas que pueden surgir al utilizar esta metodología. En particular, las astillas son un error común que se produce cuando se superponen dos capas vectoriales ligeramente desalineadas (Figura 7.12 “Astillas”). Esta desalineación puede provenir de varias fuentes incluyendo errores de digitalización, errores de interpretación o errores de mapa fuente (Chang 2008) .Chang, K. 2008. Introducción a los Sistemas de Información Geográfica. Nueva York: McGraw-Hill. Por ejemplo, la mayoría de los mapas de vegetación y suelo se crean a partir de datos de levantamiento de campo, imágenes de satélite y fotografía aérea. Si bien se puede imaginar que los límites de los suelos y la vegetación coinciden frecuentemente, el hecho de que muy probablemente fueron creados por diferentes investigadores en diferentes momentos sugiere que sus límites no se superpondrán perfectamente. Para mejorar este problema, el software SIG incorpora una opción de tolerancia de clúster que obliga a que las líneas cercanas se alineen entre sí si caen dentro de una distancia especificada por el usuario. Se debe tener cuidado a la hora de asignar tolerancia a clústeres. Un entorno demasiado estricto no romperá los límites compartidos, mientras que un escenario demasiado indulgente romperá los límites no deseados, vecinos juntos (Wang y Donaghy 1995) .Wang, F., y P. Donaghy. 1995. “Un estudio del impacto de la edición automatizada en la precisión del análisis de superposición de polígonos”. Computadoras y Geociencias 21:1177—85.
Figura 7.12 Astillas

Una segunda fuente potencial de error asociada con el proceso de superposición es la propagación de errores. La propagación de errores surge cuando las imprecisiones están presentes en las capas de entrada y superposición originales y se propagan a través de la capa de salida (MacDougall 1975) .MacDougall, E. 1975. “La precisión de las superposiciones de mapas”. Planeación del Paisaje 2:23—30. Estos errores pueden estar relacionados con imprecisiones posicionales de los puntos, líneas o polígonos. Alternativamente, pueden surgir de errores de atributo en la tabla o tablas de datos originales. Independientemente de la fuente, la propagación de errores representa un problema común en el análisis de superposición, cuyo impacto depende en gran medida de los requisitos de precisión y precisión del proyecto en cuestión.
Claves para llevar
- Los procesos de superposición colocan dos o más mapas temáticos uno encima del otro para formar un nuevo mapa.
- Las operaciones de superposición disponibles para su uso con datos vectoriales incluyen los modelos punto en polígono, polígono sobre punto, línea en línea, línea en polígono, polígono en línea y polígono en polígono.
- Unión, intersección, diferencia simétrica e identidad son operaciones comunes que se utilizan para combinar información de varios conjuntos de datos superpuestos.
Ejercicios
- Desde su propio campo de estudio, describa tres capas teóricas de datos que podrían superponerse para crear un nuevo mapa de salida que responda a una pregunta espacial compleja como, “¿Dónde está el mejor lugar para poner un centro comercial?”
- Entra en línea y encuentra los conjuntos de datos vectoriales relacionados con la pregunta que acabas de proponer.