
2.5: Formulaciones matemáticas
- Page ID
- 123202

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Ahora tienes una comprensión intuitiva de cómo la neurona integra la excitación y la inhibición. Podemos capturar esta dinámica en un conjunto de ecuaciones matemáticas que pueden ser utilizadas para simular neuronas en la computadora. El primer conjunto de ecuaciones se centra en los efectos de las entradas a una neurona. El segundo conjunto se enfoca en generar salidas a partir de la neurona. Aquí cubriremos una buena cantidad de terreno matemático. No te preocupes si no sigues todos los detalles. Siempre y cuando sigas conceptualmente lo que están haciendo las ecuaciones, deberías poder construir sobre esta comprensión cuando tengas en tus manos las propias ecuaciones reales y explorar cómo se comportan con diferentes entradas y parámetros. Verás que a pesar de todas las matemáticas, el comportamiento de la neurona es realmente simple: la cantidad de entrada excitatoria determina qué tan excitado se pone, en equilibrio con la cantidad de inhibición y fuga. Y las señales de salida resultantes se comportan más o menos como cabría esperar.
Entradas de Computación
Comenzamos por formalizar la “fuerza” por la que tira cada lado del tira y afloja, para luego mostrar cómo eso hace que la\(V_{m}\) “bandera” se mueva como resultado. Esto proporciona ecuaciones explícitas para el proceso de integración dinámica de tira y afloja. Luego, mostramos cómo calcular realmente los factores de conductancia en esta ecuación de tira y afloja en función de las entradas que entran en la neurona, y los pesos sinápticos (enfocándose en las entradas excitatorias por ahora). Finalmente, proporcionamos una ecuación resumida para el tira y afloja que puede indicarle dónde terminará la bandera al final, para complementar las ecuaciones dinámicas que muestran cómo se mueve a lo largo del tiempo.
Integración Neural
La idea clave detrás de estas ecuaciones es que cada sujeto del tira y afloja tira con una fuerza que es proporcional tanto a su fuerza general (conductancia), como a qué distancia está la “bandera” (\(V_{m}\)) de su posición (indicada por el potencial impulsor E). Imagínese que los remolcadores están plantados en su posición, y sus brazos están completamente contraídos cuando la\(V_{m}\) bandera llega a su posición (E), y no pueden volver a agarrar la cuerda, de tal manera que no puedan tirar más en este punto. Para poner esta idea en una ecuación, podemos escribir la “fuerza” o corriente que ejerce el tipo excitador como:
- corriente excitatoria:
\[I_{e}=g_{e}\left(E_{e}-V_{m}\right)\]
La corriente excitatoria es (I es el término tradicional para una corriente eléctrica, y e nuevamente para excitación), y es el producto de la conductancia
(I es el término tradicional para una corriente eléctrica, y e nuevamente para excitación), y es el producto de la conductancia por lo lejos que está el potencial de membrana del potencial excitador. Si
por lo lejos que está el potencial de membrana del potencial excitador. Si entonces el tipo excitador ha “ganado” el tira y afloja, y ya no tira, y la corriente va a cero (independientemente de cuán grande sea la conductancia — cualquier cosa por 0 es 0). Curiosamente, esto también significa que el tipo excitador tira más fuerte cuando la\(V_{m}\) “bandera” está más alejada de ella, es decir, cuando la neurona está en su potencial de reposo. Así, es más fácil excitar una neurona cuando está bien descansada.
entonces el tipo excitador ha “ganado” el tira y afloja, y ya no tira, y la corriente va a cero (independientemente de cuán grande sea la conductancia — cualquier cosa por 0 es 0). Curiosamente, esto también significa que el tipo excitador tira más fuerte cuando la\(V_{m}\) “bandera” está más alejada de ella, es decir, cuando la neurona está en su potencial de reposo. Así, es más fácil excitar una neurona cuando está bien descansada.
La misma ecuación básica se puede escribir para el tipo de inhibición, y también por separado para el tipo de fuga (que ahora podemos reintroducir como un clon básico del término de inhibición):
- corriente inhibitoria:
\[I_{i}=g_{i}\left(E_{i}-V_{m}\right) \]
- corriente de fuga:
\[I_{l}=g_{l}\left(E_{l}-V_{m}\right)\]
(sólo los subíndices son diferentes).
A continuación, podemos sumar estas tres corrientes diferentes para obtener la corriente neta, que representa el flujo neto de iones cargados a través de la membrana de la neurona (a través de los canales iónicos):
- corriente neta:
\[I_{n e t}=I_{e}+I_{i}+I_{l}=g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\]
Entonces, ¿de qué sirve una corriente neta? Recordemos que la electricidad es como el agua, y fluye para igualarse a sí misma. Cuando el agua fluye de un lugar donde hay mucha agua a un lugar donde hay menos, el resultado es que hay menos agua en primer lugar y más en el segundo. Lo mismo sucede con nuestras corrientes: el flujo de corriente cambia el potencial de membrana (altura del agua) dentro de la neurona:
- actualización del potencial de membrana debido a la corriente neta:
\[V_{m}(t)=V_{m}(t-1)+d t_{v m} I_{n e t}\]
\ [V_ {m} (t)\) es el valor actual de\(V_{m}\), que se actualiza a partir del valor en el paso de tiempo anterior\(V_{m}(t-1)\), y el\(d t_{v m}\) es una constante de velocidad que determina qué tan rápido cambia el potencial de membrana — refleja principalmente la capacitancia de la membrana de la neurona).
¡Las dos ecuaciones anteriores son la esencia de lo que necesitamos para poder simular una neurona en una computadora! Nos dice cómo cambia el potencial de membrana en función de las entradas inhibitorias, fugas y excitatorias, dado números específicos para estas conductancias de entrada, y un\(V_{m}\) valor inicial, podemos entonces calcular iterativamente el nuevo\(V_{m}\) valor de acuerdo con las ecuaciones anteriores, y esto ¡reflejará con precisión cómo respondería una neurona real a tales entradas similares!
Para resumir, aquí hay una versión única de las ecuaciones anteriores que hace todo:
- \(V_{m}(t)=V_{m}(t-1)+d t_{v m}\left[g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\right]\)
Para aquellos de ustedes que notaron el tema con el signo menos anterior, o tienen curiosidad por saber cómo todo esto se relaciona con la ley de Ohm y el proceso de difusión, por favor vea Electrofisiología de la Neurona. Si estás lo suficientemente contento con el lugar donde hemos llegado, siéntete libre de avanzar para averiguar cómo calculamos estas conductancias de entrada, y qué hacemos entonces con el\(V_{m}\) valor para impulsar la señal de salida de la neurona.
Conductancias de entrada de computación
Las conductancias de entrada excitatoria e inhibitoria representan el número total de canales iónicos de cada tipo que actualmente están abiertos y permitiendo así el flujo de iones. En las neuronas reales, estas conductancias se miden típicamente en nanosiemens (nS), que es\(10^{-9}\) siemens (un número muy pequeño — las neuronas son muy pequeñas). Por lo general, los neurocientíficos dividen estas conductancias en dos componentes:
- \(\overline{g}\)(“g-bar”) — un valor constante que determina la conductancia máxima que ocurriría si cada canal iónico estuviera abierto.
- \(g(t)\)— una variable dinámicamente cambiante que indica en el momento presente, qué fracción del número total de canales iónicos están actualmente abiertos (va entre 0 y 1).
Así, las conductancias totales de interés se escriben como:
- conductancia excitatoria:
\[\overline{g}_{e} g_{e}(t)\]
- conductancia inhibitoria:
\[\overline{g}_{i} g_{i}(t)\]
- conductancia de fuga:
\[\overline{g}_{l}\]
(tenga en cuenta que debido a que la fuga es una constante, no tiene un valor que cambie dinámicamente, solo el valor constante de la barra g).
Esta separación de términos facilita el cálculo de la conductancia, ya que todo lo que necesitamos enfocarnos es calcular la proporción o fracción de canales iónicos abiertos de cada tipo. Esto se puede hacer calculando el número promedio de canales iónicos abiertos en cada entrada sináptica a la neurona:
- \(g_{e}(t)=\frac{1}{n} \sum_{i} x_{i} w_{i}\)
donde\(x_{i}\) está la actividad de una neurona emisora particular indexada por el subíndice\(i\),\(w_{i}\) es la fuerza de peso sináptica que conecta la neurona emisora\(i\) a la neurona receptora, y\(n\) es el número total de canales de ese tipo (en este caso, excitatorio) a través de todas las entradas sinápticas a la célula. Como se señaló anteriormente, el peso sináptico determina a qué patrones es sensible la neurona receptora, y es lo que se adapta con el aprendizaje; esta ecuación muestra cómo entra matemáticamente en el cálculo de la cantidad total de conductancia excitatoria.
La ecuación anterior sugiere que la neurona realiza una función muy simple para determinar cuánta entrada está obteniendo: simplemente lo suma todo de todas sus diferentes fuentes (y toma el promedio para calcular una proporción en lugar de una suma, de modo que esta proporción se multiplica por g_bar_e para obtener una real valor de conductancia). Cada fuente de entrada contribuye en proporción a qué tan activo está el remitente, multiplicado por lo mucho que la neurona receptora se preocupa por esa información, el valor del peso sináptico. También nos referimos a esta entrada total promedio como la entrada neta.
La misma ecuación es válida para las conductancias de entrada inhibitorias, que se calculan en términos de las activaciones de las neuronas de envío inhibitorias, multiplicadas por los valores de peso inhibitorio
Hay algunas complejidades adicionales sobre cómo integramos insumos de diferentes categorías de fuentes de entrada (es decir, proyecciones de diferentes áreas del cerebro fuente en una neurona receptora dada), que tratamos en la subsección opcional: Detalle de entrada neta. Pero en general, este aspecto del cálculo es relativamente sencillo y ahora podemos pasar al siguiente paso, de comparar el potencial de membrana con el umbral y generar alguna salida.
Potencial de membrana de equilibrio
Antes de terminar el paso final en el proceso de detección (generar una salida), necesitaremos usar el concepto del potencial de membrana de equilibrio, que es el valor en el\(V_{m}\) que la neurona se asentará y permanecerá, dado un conjunto fijo de entrada excitadora e inhibitoria conductancias (si estas no son estables, entonces es\(V_{m}\) probable que cambien constantemente a medida que cambian). Este valor de equilibrio es interesante porque nos dice más claramente cómo el proceso de tira y afloja dentro de la neurona realmente se equilibra al final. También, veremos en la siguiente sección que es útil matemáticamente.
Para calcular el potencial de membrana de equilibrio\(\left(V_{m}^{e q}\right)\), podemos usar una técnica matemática importante: establecer el cambio en el potencial de membrana (de acuerdo con la ecuación de\(V_{m}\) actualización iterativa desde arriba) a 0, y luego resolver la ecuación para el valor de\(V_{m}\) bajo esta condición. En otras palabras, si queremos averiguar cuál es el estado de equilibrio, simplemente calculamos cuáles son los números que necesitan ser tales que ya no\(V_{m}\) esté cambiando (es decir, su tasa de cambio es 0). Estos son los pasos matemáticos que hacen esto:
- ecuación de\(V_{m}\) actualización iterativa:
\[V_{m}(t)=V_{m}(t-1)+d t_{v m}\left[g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\right]\]
- solo la parte de cambio (constante de tiempo omitida ya que estamos buscando equilibrio):
\[\Delta V_{m}=g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\]
- establecerlo a cero:
\[0=g_{e}\left(E_{e}-V_{m}\right)+g_{i}\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\]
- resolver para\(V_{m}\):
\[V_{m}=\frac{g_{e}}{g_{e}+g_{i}+g_{l}} E_{e}+\frac{g_{i}}{g_{e}+g_{i}+g_{l}} E_{i}+\frac{g_{l}}{g_{e}+g_{i}+g_{l}} E_{l}\]
Aquí mostramos las matemáticas: Derivación del Potencial de Membrana de Equilibrio
En palabras, esto dice que el impulso excitatorio\(E_{e}\) contribuye al\(V_{m}\) conjunto en función de la proporción de la conductancia excitatoria\(g_{e}\) relativa a la suma de todas las conductancias\(\left(g_{e}+g_{i}+g_{l}\right)\). Y lo mismo para cada uno de los demás (inhibición, fuga). Esto es justo lo que esperamos de la imagen tira y afloja: si ignoramos g_l, entonces la\(V_{m}\) “bandera” se posiciona como una función del equilibrio relativo entre\(g_{e}\) y\(g_{i}\) — si son iguales, entonces\(\frac{g_{e}}{g_{e}+g_{i}}\) es .5 (por ejemplo, simplemente ponga un “1" para cada una de las g's — 1/2 = .5), lo que significa que la\(V_{m}\) bandera está a medio camino entre\(E_{i}\) y\(E_{e}\). Entonces, ¡toda esta matemática solo para redescubrir lo que sabíamos ya intuitivamente! (En realidad, esa es la mejor manera de hacer matemáticas — si dibujas la imagen correcta, debería decirte las respuestas antes de hacer todo el álgebra). Pero ya veremos que esta matemática va a ser útil a continuación.
Aquí hay una versión con los términos de conductancia explícitamente separados en las constantes “g-bar” y las partes variables en el tiempo “g (t)”:
- \(V_{m}=\frac{\overline{g}_{e} g_{e}(t)}{\overline{g}_{e} g_{e}(t)+\overline{g}_{i} g_{i}(t)+\overline{g}_{l}} E_{e}+\frac{\overline{g}_{i} g_{i}(t)}{\overline{g}_{e} g_{e}(t)+\overline{g}_{i} g_{i}(t)+\overline{g}_{l}} E_{i}+\frac{\overline{g}_{l}}{\overline{g}_{e} g_{i}(t)+\overline{g}_{i} g_{i}(t)+\overline{g}_{l}} E_{l}\)
Para aquellos a quienes realmente les gustan las matemáticas, se puede demostrar que la ecuación del potencial de membrana de equilibrio es un Detector Óptimo Bayesiano.
Generando Salidas
La salida de la neurona se puede simular en dos niveles diferentes: el spiking discreto (que es como las neuronas realmente se comportan biológicamente), o usando una aproximación de código de velocidad. Cubrimos cada uno a su vez, y mostramos cómo se debe derivar el código de tasa para que coincida con el comportamiento de la neurona puntiaguda discreta, cuando se promedie a lo largo del tiempo (es importante que nuestras aproximaciones sean válidas en el sentido de que coincidan con el comportamiento biológico más detallado donde sea posible, aun cuando proporcionen algunos simplificación).
Apunte Discreto
Para calcular el comportamiento de aumento del potencial de acción discreto a partir de las ecuaciones neuronales que tenemos hasta ahora, necesitamos determinar cuándo el potencial de membrana supera el umbral de disparo, y luego emitir un pico, y posteriormente restablecer el potencial de membrana de nuevo a un valor, desde el cual luego puede volver a subir y activar otra espiga otra vez, etc. Esto en realidad se expresa mejor como una especie de programa de computadora simple:
- si (Vm > θ) entonces: y = 1; Vm = VM_r; de lo contrario y = 0
donde y es el valor de salida de activación de la neurona, y VM_r es el potencial de reinicio al que se restablece el potencial de membrana después de que se active un pico. Biológicamente, hay canales especiales de potasio (K+) que vuelven a bajar el potencial de la membrana después de un pico.
Este modelo más simple de pinchos no es suficiente para dar cuenta del comportamiento detallado de las neuronas corticales reales. Sin embargo, un modelo un poco más complejo puede dar cuenta de datos reales de picos con gran precisión (como lo demuestran Gerstner y sus colegas (Brette & Gerstner, 2005), ¡y ganando varias competiciones internacionales incluso!). Este modelo es conocido como el modelo Adaptive Exponential o AdEx — da clic en el enlace para leer más sobre él. Normalmente usamos este modelo AdEx cuando simulamos picos discretos, aunque el modelo más simple descrito anteriormente también sigue siendo una opción. La característica crítica del modelo AdEx es que el umbral de disparo efectivo se adapta a lo largo del tiempo, en función de la excitación que entra en la celda y su reciente historial de disparo. El resultado neto es un fenómeno llamado adaptación de tasa de pico, donde la tasa de picos tiende a disminuir con el tiempo para niveles de entrada que de otro modo serían estáticos. De lo contrario, sin embargo, el modelo AdEx es idéntico al descrito anteriormente.
Aproximación del código de velocidad a los picos

A pesar de que las neuronas reales se comunican a través de eventos discretos (potencial de acción), a menudo es útil en nuestros modelos computacionales adoptar una aproximación de código de tasa algo más abstracta, donde la neurona genera continuamente un único valor gradual (normalmente normalizado entre 0-1) que refleja la tasa general de picos que la neurona debería estar exhibiendo dado el nivel de entradas que está recibiendo. En otras palabras, podríamos contar el número de picos discretos que dispara la neurona, y dividirlo por la cantidad de tiempo que hicimos el conteo, y esto nos daría una tasa promedio de picos. En lugar de que la neurona comunique esta tasa de picos distribuidos en picos discretos durante ese período de tiempo, podemos hacer que comunique ese valor de tasa instantáneamente, como un número calificado. Computacionalmente, esto debería ser más eficiente, ya que está comprimiendo la cantidad de tiempo requerido para comunicar una tasa de picos particular, y también tiende a reducir el nivel general de ruido en la red, ya que en lugar de cambiar entre spiking y no-spiking, la neurona puede generar continuamente un valor de código de tasa más constante.
Como se señaló anteriormente, el valor del código de tasa puede considerarse en términos biológicos como la salida de una pequeña población (por ejemplo, 100) de neuronas que generalmente están recibiendo las mismas entradas, y dando respuestas de salida similares, promediando el número de picos en cualquier momento dado en el tiempo sobre esta población de neuronas es aproximadamente equivalente a promediar a lo largo del tiempo de una sola neurona puntiaguda. Como tal, podemos considerar que nuestras neuronas computacionales de código de tasa simulada corresponden a una pequeña población de neuronas puntuales discretas reales.
Para calcular realmente la salida del código de velocidad, necesitamos una ecuación que proporcione un número de valor real que coincida con el número de picos emitidos por una neurona puntiaguda con el mismo nivel de entradas. Curiosamente, no se puede usar el potencial de membrana\(V_{m}\) como entrada a esta ecuación, ¡no tiene una relación uno a uno con la tasa de aumento! Es decir, cuando ejecutamos nuestro modelo de picos y medimos la tasa real de picos para diferentes combinaciones de entrada excitatoria e inhibitoria, y luego graficamos eso contra el\(V_{m}\) valor de equilibrio que producen esos valores de entrada (sin que tenga lugar ningún pico), hay múltiples valores de tasa de picos para cada\(V_{m}\) valor — no se puede predecir el valor correcto de la velocidad de disparo conociendo solo el\(V_{m}\) (Figura 2.5).

En cambio, resulta que la entrada neta excitatoria\(g_{e}\) permite una buena predicción de la tasa de pico real, cuando se compara con un valor umbral apropiado (Figura 2.6). Para el potencial de membrana, sabemos que\(V_{m}\) se compara con el umbral\(\theta\) para determinar cuándo ocurre la salida. ¿Cuál es el umbral apropiado a utilizar para la entrada neta excitatoria? Necesitamos convertirnos de alguna manera\(\theta\) en un\(g_{e}^{\Theta}\) valor, un umbral en términos de entrada excitatoria. Aquí, podemos aprovechar la ecuación de potencial de membrana de equilibrio, derivada anteriormente. Podemos usar esta ecuación para resolver el nivel de conductancia de entrada excitatoria que pondría el potencial de membrana de equilibrio justo en el umbral de disparo\(\theta\):
- equilibrio\(V_{m}\) en el umbral:
\[\Theta=\frac{g_{e}^{\Theta} E_{e}+g_{i} E_{i}+g_{l} E_{l}}{g_{e}^{\Theta}+g_{i}+g_{l}}\]
- resuelto para g_ {e} ^ {\ Theta}:
\[g_{e}^{\Theta}=\frac{g_{i}\left(E_{i}-\Theta\right)+g_{l}\left(E_{l}-\Theta\right)}{\Theta-E_{e}}\]
(ver g_ {e} ^ {\ Theta} derivación para el álgebra para derivar esta solución),
Ahora, podemos decir que nuestro valor de activación de salida codificado por tasa será alguna función de la diferencia entre la entrada neta excitatoria g_ {e} y este valor umbral:
- \(y=f\left(g_{e}-g_{e}^{\Theta}\right)\)
Y todo lo que tenemos que hacer es averiguar cómo debería ser esta función f ().
Hay tres propiedades importantes que esta función debe tener:
- umbral — debe ser 0 (o cerca de él) cuando\(g_{e}\) es menor que su valor umbral (las neuronas no deben responder cuando están por debajo del umbral).
- saturación —cuando\(g_{e}\) se vuelve muy fuerte en relación con el umbral, la neurona en realidad no puede seguir disparando a tasas cada vez más altas— hay un límite superior a qué tan rápido puede aumentar (típicamente alrededor de 100-200 Hz o picos por segundo). Por lo tanto, nuestra función de código de tasa también necesita exhibir esta nivelación o saturación en el extremo superior.
- suavidad — no debería haber ninguna transición abrupta (bordes afilados) a la función, de modo que el comportamiento de la neurona sea suave y continuo.
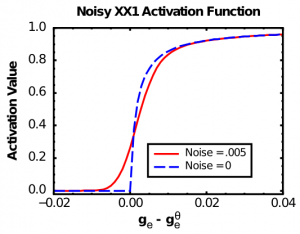
La función X-over-X-plus-1 (XX1) (Figura 2.7, Ruido=0 caso, también conocida como la función cinética Michaelis-Mentina — Enlace Wikipedia) exhibe las dos primeras de estas propiedades:
- \(f_{x x 1}(x)=\frac{x}{x+1}\)
donde x es la porción positiva de , con un factor de ganancia extra
, con un factor de ganancia extra , que simplemente multiplica todo:
, que simplemente multiplica todo:
- \(x=\gamma\left[g_{e}-g_{e}^{\Theta}\right]_{+}\)
Entonces la ecuación completa es:
- \(y=\frac{\gamma\left[g_{e}-g_{e}^{\Theta}\right]_{+}}{\gamma\left[g_{e}-g_{e}^{\Theta}\right]_{+}+1}\)
Que también se puede escribir como:
- \(y=\frac{1}{\left(1+\frac{1}{\gamma\left[g_{c}-g_{e}^{\ominus}\right]_{+}}\right)}\)
Como puede ver en la Figura 2.7 (Ruido=0), la función básica XX1 no es suave en el punto del umbral. Para remediar este problema, convolucionamos la función XX1 con ruido normalmente distribuido (gaussiano), lo que la suaviza como se muestra en el caso Noise=0.005 en la Figura 2.7. Convolucionar equivale a sumar a cada punto de la función alguna contribución de sus vecinos cercanos, ponderada por la curva gaussiana (en forma de campana). Es lo que hacen los programas de edición de fotos cuando hacen “suavizar” o “desenfocar” en una imagen. En el software, realizamos esta operación de convolución y luego almacenamos los resultados en una tabla de valores de búsqueda, para hacer que el cómputo sea muy rápido. Biológicamente, este proceso de convolución refleja el hecho de que las neuronas experimentan una gran cantidad de ruido (fluctuaciones aleatorias en las entradas y el potencial de membrana), de manera que aunque estén ligeramente por debajo del umbral de disparo, una fluctuación aleatoria a veces puede empujarlo por encima del umbral y generar un pico. Por lo tanto, la tasa de picos alrededor del umbral es suave, no aguda como en la función simple XX1.
Por el bien de la integridad, y estrictamente para los matemáticamente inclinados, aquí está la ecuación para la operación de convolución:
- \(y^{*}(x)=\int_{-\infty}^{\infty} \frac{1}{\sqrt{2 \pi} \sigma} e^{-z^{2} /\left(2 \sigma^{2}\right)} y(z-x) d z\)
donde y (z-x) es la función XX1 aplicada a la entrada z-x en lugar de solo x. En la práctica, un núcleo finito de ancho a cada\(3 \sigma\) lado de x se usa en la convolución numérica.
Después de la convolución, la función XX1 (Figura 2.7) se aproxima a la velocidad de disparo promedio de muchos modelos neuronales con agregado discreto, incluyendo AdEx. Una explicación matemática está aquí: Curva de frecuencia-corriente.
Restauración de dinámicas iterativas en la activación
Solo hay un último problema con las ecuaciones como se ha escrito anteriormente. No evolucionan con el tiempo de una manera graduada. Por el contrario, el\(V_{m}\) valor evoluciona de manera graduada en virtud de ser computado iterativamente, donde se aproxima incrementalmente al valor de equilibrio a lo largo de una serie de etapas de tiempo de actualización. En cambio, la activación producida por las ecuaciones anteriores va directamente a su valor de equilibrio muy rápidamente, ya que se calcula en base a la conductancia excitatoria y no toma en cuenta la lentitud con la que los cambios en la conductancia conducen a cambios en los potenciales de membrana (debido a la capacitancia). Como se discutió en la Introducción, el procesamiento gradual es muy importante, y lo podemos ver muy directamente en este caso, porque las ecuaciones anteriores no funcionan muy bien en muchos casos porque carecen de esta evolución gradual a lo largo del tiempo.
Para introducir dinámicas iterativas graduadas en la función de activación, solo usamos el valor de activación (\(y^{*}(x)\)) de la ecuación anterior como una fuerza impulsora a una ecuación de actualización iterativa extendida temporalmente:
\[y(t)=y(t-1)+d t_{v m}\left(y^{*}(x)-y(t-1)\right)\]
Esto hace que la salida de activación del código de tasa final real en el tiempo actual t, y (t) se acerque iterativamente al valor de activación dado por\(y^{*}(x)\), con la misma constante de tiempo\(d t_{v m}\) que se usa para actualizar el potencial de membrana. En la práctica esto funciona extremadamente bien, mejor que cualquier función de activación previa utilizada con Leabra.
| Parámetro | Bio Val |
Norm Val |
Parámetro |
Bio Val | Norm Val | |
|---|---|---|---|---|---|---|
|
Tiempo |
0.001 seg | 1 ms | Voltaje | 0.1 V o 100 mV | -100.. 100 mV = 0.. 2 dV | |
| Actual | \(1 \times 10^{-8}\)A | 10 nA | Conductancia | 1x10^ {-9} S | 1 nS | |
| Capacitancia | \(1 \times 10^{-12}\)F | 1 pF | C (capacitancia memb) | 281 pF | 1/C = .355 = dt.vm | |
| \(g_{l}\)(fuga) | 10 nS | 0.1 | \(g_{i}\)(inhibición) | 100 nS | 1 | |
| \(g_{e}\)(excitación) | 100 nS | 1 | e_rev_l (fuga) y VM_r | -70 mV | 0.3 | |
|
e_rev_i (inhibición) |
-75 mV | 0.25 | e_rev_e (excitación) | 0 mV |
1 |
|
| \(\theta\)(act.thr,\(\mathbf{V}_{\mathbf{T}}\) en AdEx) | -50 mV | 0.5 | spike.spk_thr (límite de exp en AdEx) | 20 mV | 1.2 | |
| spike.exp_slope (\(\Delta_{\mathbf{T}}\)en AdEx) | 2 mV | 0.02 | adapt.dt_time (\(\tau_{W}\)en AdEx) | 144 ms | dt = 0.007 | |
| adapt.vm_gain (a en AdEx) | 4 nS | 0.04 | adapt.spk_gain (b en AdEx) | 0.0805 nA | 0.00805 |
Tabla\(2.1\): Los parámetros utilizados en nuestras simulaciones se normalizan utilizando los factores de conversión anteriores para que los valores típicos que surgen en una simulación caigan dentro del rango normalizado de 0.1. Por ejemplo, el potencial de membrana se representa en el rango entre 0 y 2 donde 0 corresponde a -100 mV y 2 corresponde a +100 mV y 1 es así 0 mV (y la mayoría de los valores de potencial de membrana permanecen dentro de 0-1 en esta escala). Los valores biológicos dados son los valores predeterminados para el modelo AdEx. Otros valores biológicos se pueden ingresar usando el botón BioParams en el LeabraUnitSpec, que los convierte automáticamente en valores normalizados.
En la tabla se\(2.1\) muestran los valores normalizados de los parámetros utilizados en nuestras simulaciones. Utilizamos estos valores normalizados en lugar de los parámetros biológicos normales para que todo encaje naturalmente dentro de un rango 0.. 1, simplificando así muchos aspectos prácticos del trabajo con las simulaciones.
Aquí se muestran las ecuaciones finales utilizadas para actualizar la neurona, en orden computacional, con todas las variables que cambian con el tiempo indicadas en función de (t):
1. Calcule la conductancia de entrada excitatoria (la inhibición sería similar, pero discutiremos esto más en el siguiente capítulo, así que la omitiremos aquí):
- \(g_{e}(t)=\frac{1}{n} \sum_{i} x_{i}(t) w_{i}\)
2. Actualizar el potencial de membrana paso a paso, en función de las conductancias de entrada (separando las conductancias en partes dinámicas y constantes de “barra g”):
- \(V_{m}(t)=V_{m}(t-1)+d t_{v m}\left[\overline{g}_{e} g_{e}(t)\left(E_{e}-V_{m}\right)+\overline{g}_{i} g_{i}(t)\left(E_{i}-V_{m}\right)+g_{l}\left(E_{l}-V_{m}\right)\right]\)
3a. Para picos discretos, compare el potencial de membrana con el umbral y active un pico y reinicie Vm si está por encima del umbral:
- si (Vm (t) > θ) entonces: y (t) = 1; Vm (t) = VM_r; de lo contrario y (t) = 0
3b. Para la aproximación del código de velocidad, calcule la activación de salida como función NXX1 de g_e y Vm:
- \(y^{*}(x)=f_{N X X 1}\left(g_{e}^{*}(t)\right) \approx \frac{1}{\left(1+\frac{1}{\gamma\left[g_{e}-g_{e}^{\Theta}\right]_{+}}\right)}\)(convolución con ruido no mostrado)
- \(y(t)=y(t-1)+d t_{v m}\left(y^{*}(x)-y(t-1)\right)\)(restaurar dinámicas iterativas basadas en la constante de tiempo de los cambios potenciales de membrana)