
11.2: Una visión general del Código Genético
- Page ID
- 54081

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
A. El Código Genético (Casi) Universal y Degenerado
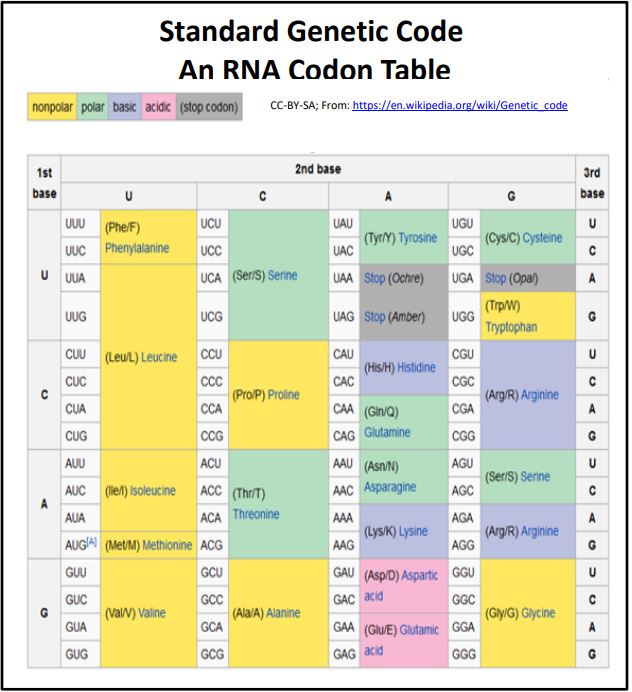
El código genético es la información para unir aminoácidos en polipéptidos en un orden basado en la secuencia de bases de palabras de código de 3 bases (codones) en un gen y su ARN mensajero (ARNm). Con algunas excepciones (algunos procariotas, mitocondrias, cloroplastos), el código genético es universal —es lo mismo en todos los organismos, desde virus y bacterias hasta humanos. En la tabla del Código Genético Universal Estándar de la página siguiente se muestra la versión de ARN de los codones tripletes y sus aminoácidos correspondientes. Hay un solo codón para dos aminoácidos (metionina y triptófano), pero dos o más codones para cada uno de los otros 18 aminoácidos. Por esta última razón, decimos que el código genético es degenerado. Los tres codones de parada en el Código Genético Estándar 'dicen' a los ribosomas la ubicación del último aminoácido para agregar a un polipéptido. El último aminoácido en sí mismo puede ser cualquier aminoácido consistente con la función del polipéptido que se está sintetizando. Sin embargo, la evolución ha seleccionado AUG como codón de inicio para todos los polipéptidos, independientemente de su función, así como para la colocación de metionina dentro de un polipéptido. Así, todos los polipéptidos comienzan la vida con una metionina en su extremo amino-terminal. Como veremos con más detalle, la máquina de traducción de ARNm es el ribosoma y el dispositivo de decodificación es ARNt. Cada aminoácido se une a un ARNt cuya secuencia corta contiene un anticodón de 3 bases que es complementario a un codón de ARNm. Las reacciones enzimáticas catalizan las reacciones de síntesis de deshidratación (condensación) que enlazan aminoácidos en enlaces peptídicos en el orden especificado por los codones en el ARNm.
B. Comentarios sobre la naturaleza y evolución de la información genética
La casi universalidad del código genético de bacterias a humanos implica que el código se originó temprano en la evolución. Es probable que partes del código estuvieran en su lugar incluso antes de que comenzara la vida. Sin embargo, una vez en su lugar, el código genético estuvo altamente restringido contra el cambio evolutivo. La degeneración del código genético permitió y contribuyó a esta restricción al permitir muchos cambios de bases que no afectan al aminoácido codificado en un codón.
La casi universalidad del código genético y su resistencia al cambio son características de nuestros genomas que nos permiten comparar secuencias génicas y otras secuencias de ADN para establecer relaciones evolutivas entre organismos (especies), grupos de organismos (género, familia, orden, etc.) e incluso individuos dentro de una especie.
Además de las restricciones impuestas por un código genético universal, algunos organismos muestran sesgo de codones, una restricción reciente sobre la que utiliza un organismo codones universales. El sesgo de codones se observa en organismos que usan preferiblemente codones ricos en A-T, o en organismos que favorecen codones más ricos en G y C. Curiosamente, el sesgo de codones en genes a menudo acompaña al sesgo genómico de nucleótidos correspondiente. Un organismo con un sesgo de codón AT también puede tener un genoma rico en AT (igualmente codones ricos en CG en genomas ricos en CG). ¡Puedes reconocer el sesgo de nucleótidos del genoma en las proporciones de bases de Chargaff!
Por último, a menudo pensamos en la información genética como genes para proteínas. Ejemplos obvios de información genética no codificante incluyen los genes para ARNr y ARNt, comunes a todos los organismos. La cantidad de este tipo de ADN informativo (es decir, genes para polipéptidos, ARNt y ARNr) como proporción del ADN total puede variar entre especies, aunque es mayor en eucariotas procariotas. Por ejemplo, ~ 88% del cromosoma circular de E. coli codifica polipéptidos, mientras que esa cifra es menor de ~ 1.5% para los humanos. Se transcriben algunas secuencias de ADN informativas menos obvias en organismos superiores (por ejemplo, intrones). Otro ADN informativo en el genoma nunca se transcribe. Estos últimos incluyen secuencias de ADN reguladoras, secuencias de ADN que soportan la estructura cromosómica y otros ADN que contribuyen al desarrollo y fenotipo. En cuanto a esa cantidad de ADN verdaderamente no informativo (inútil) en un genoma eucariota, esa cantidad se está reduciendo constantemente a medida que secuenciamos genomas completos, identificamos nuevas secuencias de ADN y descubrimos nuevos ARN (temas tratados en otras partes de este texto).