
17.9: Ampliación del Enfoque EM
- Page ID
- 54232

Modelo ZOOPS
El enfoque presentado antes (OOPS) se basa en la suposición de que cada secuencia se caracteriza por un solo motivo (por ejemplo, hay exactamente una ocurrencia de motivo en una secuencia dada). El modelo ZOOPS toma en consideración la posibilidad de secuencias que no contengan motivos.
En este caso deja que yo sea una secuencia que no contenga un motivo. Esta información extra se agrega a nuestro modelo anterior usando otro parámetro λ para denotar la probabilidad previa de que cualquier posición en una secuencia sea el inicio de un motivo. A continuación, la probabilidad de que toda la secuencia contenga un motivo es λ = (L − W + 1) ∗ λ
El E-Step
El paso E del modelo ZOOPS calcula el valor esperado de la información faltante, la probabilidad de que una ocurrencia de motivo comience en la posición j de la secuencia Xi. A continuación se dan las fórmulas utilizadas para los tres tipos de modelo.
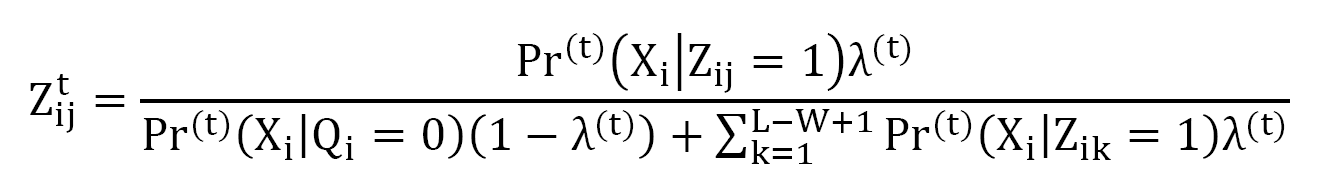
donde λ t es la probabilidad de que la secuencia i tenga un motivo, Pr t (Xi |Q i = 0) es la probabilidad de que Xi se genere a partir de una secuencia i que no contiene un motivo
El M-Step
El paso M de EM en MEME reestima los valores para λ usando las fórmulas anteriores. La matemática sigue siendo la misma que para OOPS, solo actualizamos los valores para λ y γ
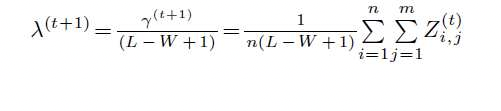
El modelo anterior toma en consideración secuencias que no tienen ningún motivo. El reto es también tomar en consideración la situación en la que hay más de un motivo por secuencia. Esto se puede lograr con el modelo más general TCM. El TCM (modelo de mezcla de dos componentes) se basa en la suposición de que puede haber cero, una o incluso dos ocurrencias de motivo por secuencia.

Encontrar múltiples motivos
Todos los modelos de secuencia anteriores modelan secuencias que contienen un solo motivo (observe que el modelo TCM puede describir secuencias con múltiples ocurrencias del mismo motivo). Para encontrar múltiples motivos diferentes, no superpuestos en un solo conjunto de datos, se incorpora información sobre los motivos ya descubiertos en el modelo actual para evitar redescubrir el mismo motivo. Los tres tipos de modelos de secuencia asumen que las ocurrencias de motivos son igualmente probables en cada posición j en las secuencias x i. Esto se traduce en una distribución de probabilidad previa uniforme sobre las variables de datos faltantes Z ij. Se tuvo que usar un nuevo prior en cada Z ij durante la etapa E que toma en cuenta la probabilidad de que una nueva ocurrencia de motivo Ancho-W comenzando en la posición X ij pudiera superponerse a las ocurrencias de los motivos previamente encontrados. Para ayudar a calcular el nuevo previo en Z ij introducimos variables V ij donde V ij = 1 si una ocurrencia de motivo Ancho-W podría comenzar en la posición j en la secuencia Xi sin solapar una ocurrencia de un motivo encontrado en una pasada previa. De lo contrario V ij = 0.
