
1.6: Expresión Génica- Traducción
- Page ID
- 56635

- Determinar la secuencia de aminoácidos de una proteína dada la secuencia de nucleótidos de un gen.
- Reconocer la conexión biológica entre ARNm, ARNt, aminoácidos y proteínas.
- Comprender el concepto de estructura proteica y su relación con la función proteica.
Introducción
La importancia de la expresión génica es evidente cuando se observan los cambios que atraviesan las plantas durante su ciclo de vida o durante una temporada. Los árboles y arbustos, por ejemplo, tienen cogollos latentes durante el invierno. Las señales ambientales relacionadas con la llegada de la primavera inducen a los genes en los cogollos a encenderse e impulsar los cambios dramáticos del desarrollo y floración de las hojas. Los genes estuvieron siempre presentes en esas células del brote pero fueron controlados para encenderse en el momento adecuado. Entender así la expresión génica requiere un examen de dos procesos, la activación de la expresión génica para hacer un “mensaje” y la lectura de este mensaje para construir una proteína específica.
Los aminoácidos se utilizan para elaborar proteínas
Los aminoácidos son los bloques de construcción de las proteínas. Excepto el aminoácido prolina, todos ellos consisten en un átomo de carbono central unido covalentemente a un grupo amino, un átomo de hidrógeno, un grupo carboxilo y un grupo R variable (Figura 1). En el rango fisiológico, tanto el ácido carboxílico como los grupos amino están completamente ionizados permitiendo que los aminoácidos actúen como un ácido o una base. Por lo tanto, los aminoácidos no asumen una forma neutra en un ambiente acuoso.
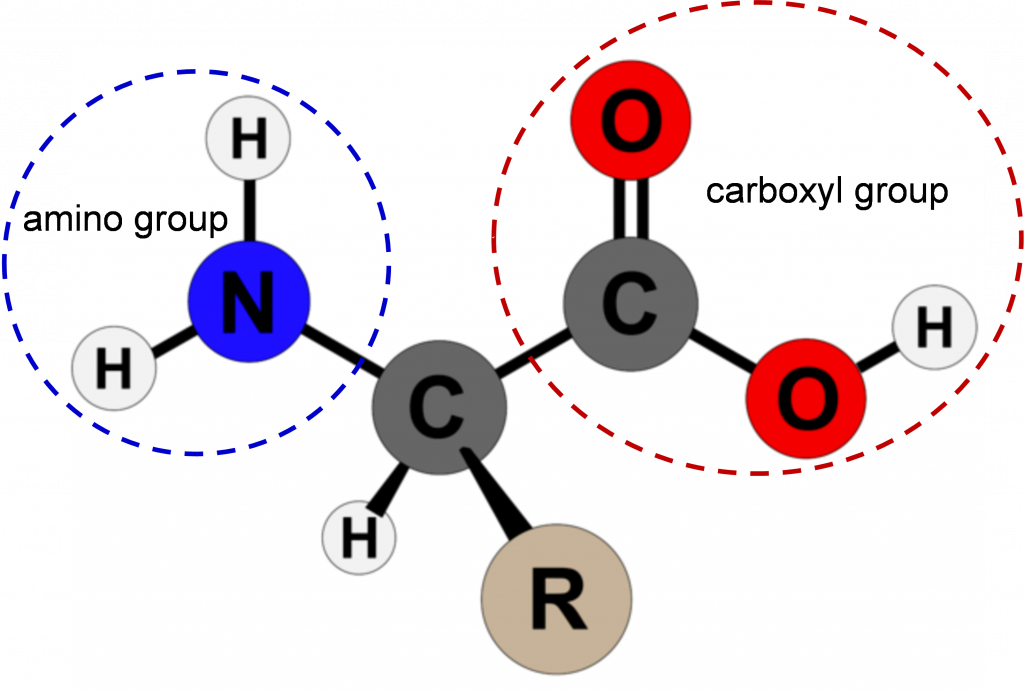
Las propiedades químicas y físicas de las cadenas laterales proporcionan las propiedades funcionalmente importantes a los aminoácidos. Algunas de las propiedades importantes de las cadenas laterales incluyen ácido, básico o neutro, hidrófobo vs hidrófilo, así como el tamaño de las cadenas laterales. Se categorizan según sus grupos laterales como no polares, polares, con carga positiva o negativa o aromáticos. Todas estas propiedades y otras afectan cómo cada aminoácido contribuye a la estructura y función de una proteína madura.
Existen 20 aminoácidos diferentes que conforman las subunidades de proteínas (Cuadro 1). Todas las proteínas se elaboran a partir de diferentes combinaciones de los aminoácidos (Figura 2). Por lo tanto, si vas a elaborar proteínas necesitas o bien hacer aminoácidos primero (Figura 3) o consumir aminoácidos en tu dieta. Los animales consumen algunos de sus aminoácidos (los aminoácidos esenciales), pero las plantas y las bacterias son capaces de elaborar todos sus propios aminoácidos.
| Nombre Completo | Abreviatura (3 Letras) | Abreviatura (1 Letra) |
|---|---|---|
| Alanina | Ala | A |
| Arginina | Arg | R |
| Asparagina | Asn | N |
| Aspartato | Asp | D |
| Cisteina | Cys | C |
| Glutamato | Glu | E |
| Glutamina | Gln | Q |
| Glicina | Gly | G |
| Histidina | Su | H |
| Isoleucina | Ile | I |
| Leucina | Leu | L |
| Lisina | Lys | K |
| Metionina | Met | M |
| Fenilalanina | Phe | F |
| Prolina | Pro | P |
| Serina | Ser | S |
| Treonina | Thr | T |
| Triptófano | Trp | W |
| Tirosina | Tyr | Y |
| Valina | Val | V |
Los codones y el Código Genético
La búsqueda del código genético (Cuadro 2) reveló que la información genética se almacena en tripletes de nucleótidos denominados codones. El código genético es degenerado porque muchos aminoácidos están especificados por más de un codón. Sesenta y una de las 64 combinaciones posibles de las tres bases en un codón se utilizan para codificar aminoácidos específicos. Tres codones de parada, UAA, UAG y UGA no codifican ningún aminoácido, pero especifican la terminación de la síntesis de la cadena peptídica durante la traducción. El codón de inicio AUG se utiliza para iniciar la síntesis de polipéptidos y codifica el aminoácido metionina.
|
Primera posición |
Segunda Posición |
Tercera Posición |
|||
|
U |
C |
A |
G |
||
|
U |
Phe (F) |
Ser (S) |
Tyr (Y) |
Cys (C) |
U |
|
C |
|||||
|
Leu (L) |
Detener |
Detener |
A |
||
|
Detener |
Trp (W) |
G |
|||
|
C |
Leu (L) |
Pro (P) |
Su (H) |
Arg (R) |
U |
|
C |
|||||
|
Gln (Q) |
A |
||||
|
G |
|||||
|
A |
Ile (I) |
Thr (T) |
Asn (N) |
Ser (S) |
U |
|
C |
|||||
|
Lys (K) |
Arg (R) |
A |
|||
|
M y (M) |
G |
||||
|
G |
Val (V) |
Ala (A) |
Asp (D) |
Gly (G) |
U |
|
C |
|||||
|
Glu (E) |
A |
||||
|
G |
|||||
¿Por qué un Código Triplete?
Antes de comprender los detalles de transcripción y traducción, los genetistas predijeron que el ADN podría codificar aminoácidos solo si se usaba un código de al menos tres nucleótidos. La lógica es que el código de nucleótidos debe ser capaz de especificar la ubicación de 20 aminoácidos. Dado que solo hay cuatro nucleótidos, un código de nucleótidos individuales solo representaría cuatro aminoácidos, de tal manera que A, C, G y U podrían traducirse para codificar aminoácidos. Un código doblete podría codificar 16 aminoácidos (4 x 4). Un código triplete podría hacer un código genético para 64 combinaciones diferentes (4 X 4 X 4) código genético y proporcionar mucha información en la molécula de ADN para especificar la ubicación de los 20 aminoácidos. Cuando se realizaron experimentos para descifrar el código genético, se encontró que era un código que era triplete. Estos códigos de tres letras de nucleótidos (AUG, AAA, etc.) se denominan codones.
El código genético solo necesitaba ser descifrado una vez porque es universal (con algunas raras excepciones). Eso significa que todos los organismos utilizan los mismos codones para especificar la colocación de cada uno de los 20 aminoácidos en la formación de proteínas. Por lo tanto, puede construirse una tabla de codones y leerse cualquier región codificante de nucleótidos para determinar la secuencia de aminoácidos de la proteína codificada. Una mirada al código genético en la tabla de codones a continuación revela que el código es redundante, lo que significa que muchos de los aminoácidos pueden ser codificados por cuatro o seis posibles codones. La secuencia de aminoácidos de proteínas de todo tipo de organismos generalmente se determina secuenciando el gen que codifica la proteína y luego leyendo el código genético de la secuencia de ADN
Ribosomas, ARNt y anti-codones
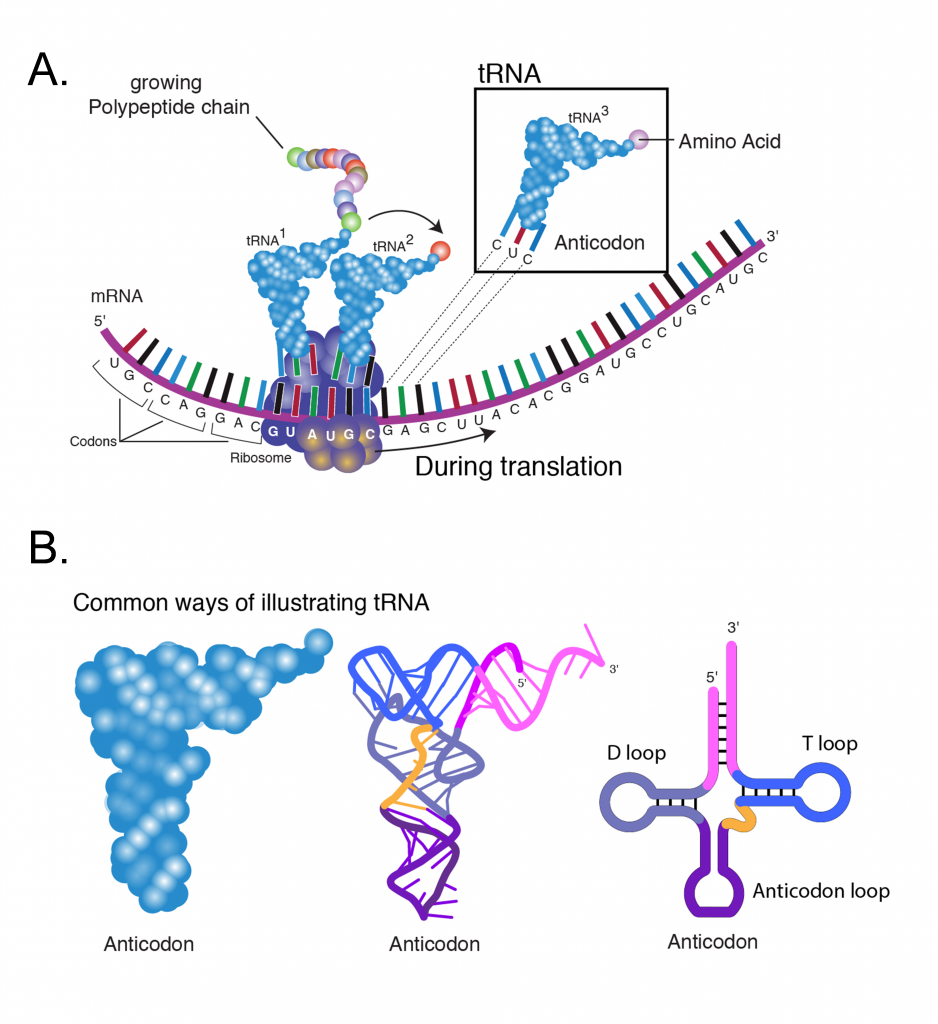
Los ribosomas son grandes complejos moleculares que contienen un ensamblaje de varios ARN ribosómicos (ARNr) y muchas proteínas. Los ribosomas son la maquinaria de la síntesis de proteínas, facilitando la adición ordenada de aminoácidos a una cadena polipeptídica naciente bajo la guía de un molde de ARNm (Figura 5A). Antes del inicio de la síntesis de proteínas, el ribosoma ocurre en dos subunidades separadas de tamaño 60s y 40s (“s” significa unidades de Svedberg y es una medida de una velocidad de sedimentación de partículas durante la centrifugación).
El significado de un codón para un aminoácido específico está determinado por el ARNt (ARN de transferencia). Cada ARNt (Figura 5B) contiene un triplete de nucleótidos denominado anticodón, que es complementario a un codón específico. Para cada uno de los 20 aminoácidos, una enzima específica (aminoacil-ARNt sintetasa) cataliza su enlace al extremo 3' de su adaptador de ARNt específico. La función de la aminoacil-ARNt sintetasa es crítica, ya que proporciona una verificación de la precisión en la síntesis de proteínas al agregar un aminoácido específico a una molécula de ARNt específica. De esta manera, un aminoácido particular se dirige a cada triplete de codones de ARNm.
Formación de cadena peptídica
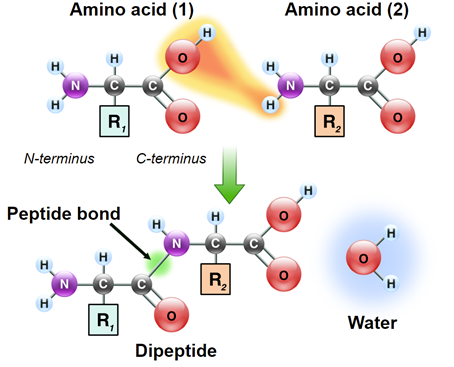
La síntesis de proteínas es iniciada por la subunidad 40s a través de su unión al ARNm y reconocimiento del codón AUG. Esto es seguido por la unión de la subunidad 60s al complejo 40S-ARNm para proporcionar la estructura necesaria para alinear cada ARNt cargado con aminoacilo sucesivo para la transferencia de su aminoácido al polipéptido en crecimiento. Los aminoácidos sucesivos se unen al polipéptido en crecimiento mediante la formación de enlaces peptídicos que se forman entre el grupo carboxilo de un aminoácido y el grupo amino del siguiente.
Al igual que los ácidos nucleicos, los polipéptidos también tienen direccionalidad molecular. Un extremo de una cadena polipeptídica tendrá un grupo amino libre y el extremo opuesto tendrá un grupo carboxi libre. Como tales, estos extremos se denominan el extremo amino o el extremo carboxi, respectivamente. Durante la traducción, los moldes de ARNm se leen desde el extremo 5' hacia el extremo 3'. Las proteínas se sintetizan comenzando en el extremo amino terminal yendo hacia el extremo carboxi terminal.
Estructura y función de las proteínas
Las proteínas asumen estructuras tridimensionales complejas que son esenciales para sus diversas funciones como enzimas, factores reguladores o proteínas estructurales. La estructura general está determinada por interacciones físico-químicas complejas entre los grupos laterales de aminoácidos.
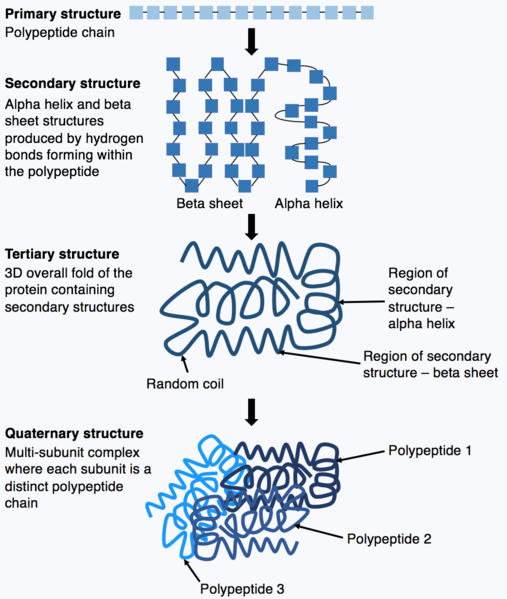
Se consideran varios niveles de estructura (Figura 6). La estructura primaria de una proteína es la secuencia de aminoácidos de sus cadenas polipeptídicas. La estructura secundaria se deriva a través de las interacciones entre aminoácidos vecinos para formar elementos estructurales locales como láminas beta o hélices alfa. La estructura terciaria se refiere a la estructura tridimensional de un polipéptido completo y está determinada por las diversas propiedades de los grupos laterales de aminoácidos. Por ejemplo, en un ambiente acuoso, los aminoácidos hidrófobos a menudo interaccionarán en el núcleo de una estructura proteica, mientras que los grupos hidrófilos pueden estar expuestos en la superficie de la proteína.
Muchas proteínas son multiméricas, compuestas por varias cadenas polipeptídicas llamadas “subunidades”, que se asocian de forma no covalente o en algunos casos a través de enlaces disulfuro. Tales asociaciones espaciales de orden superior entre polipéptidos también son el resultado de interacciones entre aminoácidos y dan como resultado una estructura cuaternaria. Algunas proteínas multiméricas consisten en múltiples copias del mismo polipéptido.
La información genética del ADN se transfiere a través de la transcripción a una molécula intermedia llamada ARN. Las señales para iniciar y detener la transcripción se localizan dentro de la secuencia de ADN, y se denominan secuencias promotoras y terminadoras. La región codificante de un gen está compuesta por una secuencia de nucleótidos que se transcriben en ARN. Estas secuencias incluyen exones e intrones. Los exones son las secuencias que codifican para las proteínas. La región codificante de un gen contiene exones e intrones. Además, el pre-ARNm contiene tanto intrones como exones. Los intrones en el pre-ARNm se eliminan a través de un proceso llamado corte y empalme de intrones. El ARNm se procesa mediante la terminación 5' y la adición de una cola poli (A). Luego, el ARN maduro se traduce en aminoácidos utilizados para construir proteínas.
- Fuente de la mesa: Donald Lee, Universidad de Nebraska-Lincoln