Vale la pena profundizar un poco más en por qué debemos confiar en el proceso inductivo científico, incluso cuando se basa en muestras limitadas que no ofrecen “pruebas” absolutas. Para ello, examinemos una práctica generalizada en la ciencia psicológica: la prueba de significación de hipótesis nula.
Para entender este concepto, comencemos con otro ejemplo de investigación. Imagínese, por ejemplo, que un investigador siente curiosidad por las formas en que la madurez afecta el rendimiento académico. Podría tener la hipótesis de que los estudiantes maduros tienen más probabilidades de ser responsables de estudiar y completar el trabajo en casa y, por lo tanto, les irá mejor en sus cursos. Para probar esta hipótesis, el investigador necesita una medida de madurez y una medida del desempeño del curso. Podría calcular la correlación —o relación— entre la edad del estudiante (su medida de madurez) y los puntos obtenidos en un curso (su mea- seguro de rendimiento académico). En última instancia, el investigador está interesado en la probabilidad —o probabilidad— de que estas dos variables se relacionen estrechamente entre sí. La prueba de significancia de hipótesis nula (NHST) evalúa la probabilidad de que los datos recopilados (las observaciones) sean los mismos si no hubiera relación entre las variables en el estudio. Usando nuestro ejemplo, el NHST probaría la probabilidad de que el investigador encontrara un vínculo entre la edad y el desempeño de clase si en realidad no existiera tal vínculo.
Figura\(\PageIndex{1}\): ¿Existe una relación entre la edad del estudiante y el rendimiento académico? ¿Cómo podríamos investigar esta pregunta? ¿Qué tan seguros podemos estar de que nuestras observaciones reflejen la realidad? [“Centro de Enseñanza y Aprendizaje en la UIS” de Jeremy Wilburn/Flickr está licenciado bajo CC BY-NC-ND 2.0.]
Ahora, aquí es donde se complica un poco. NHST implica una hipótesis nula, una afirmación de que dos variables no están relacionadas (en este caso, que la madurez del estudiante y el rendimiento académico no están relacionados de ninguna manera significativa). NHST también implica una hipótesis alternativa, una afirmación de que dos variables están relacionadas (en este caso, que la madurez estudiantil y el rendimiento académico van de la mano). Para evaluar estas dos hipótesis, el investigador recolecta datos. Luego, la investigadora compara lo que espera encontrar (probabilidad) con lo que realmente encuentra (los datos recopilados) para determinar si puede falsificar, o rechazar, la hipótesis nula a favor de la hipótesis alternativa.
¿Cómo hace esto? Al observar la distribución de los datos. La distribución es la dispersión de valores, en nuestro ejemplo, los valores numéricos de las puntuaciones de los estudiantes en el curso. La investigadora pondrá a prueba su hipótesis comparando la distribución observada de las calificaciones obtenidas por los estudiantes mayores con las obtenidas por estudiantes más jóvenes, reconociendo que algunas distribuciones son más o menos probables. Tu intuición te dice, por ejemplo, que las posibilidades de que cada persona en el curso obtenga una puntuación perfecta son inferiores a las que sus puntuaciones se distribuyen en todos los niveles de rendimiento.
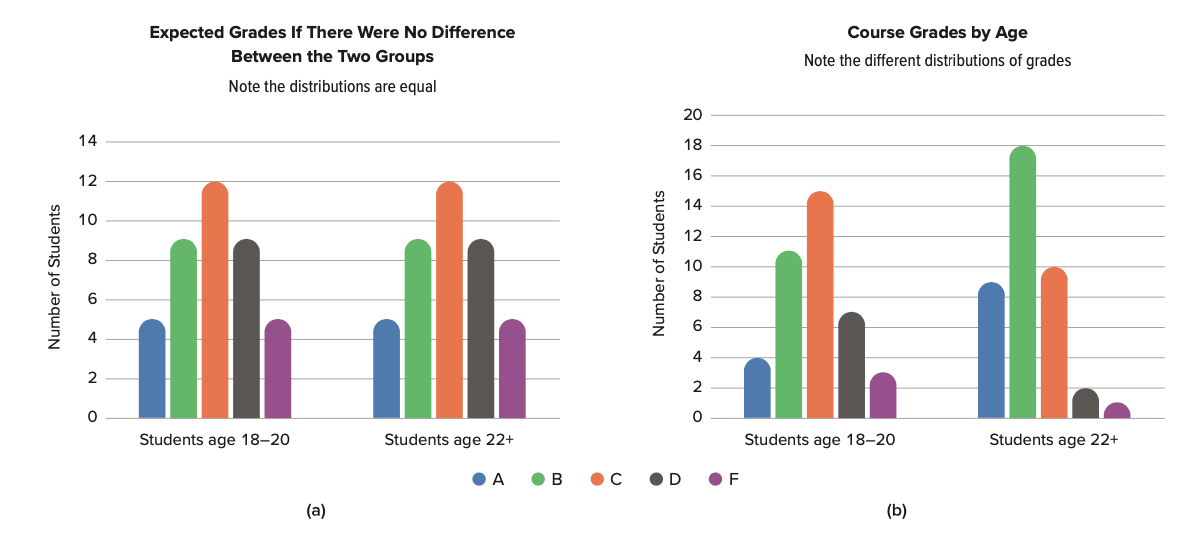
La investigadora puede utilizar una tabla de probabilidad para evaluar la probabilidad de cualquier distribución que encuentre en su clase. Estas tablas reflejan el trabajo, a lo largo de los últimos 200 años, de matemáticos y científicos de diversos campos. Se puede ver, en la Figura\(\PageIndex{2}\)(a), un ejemplo de una distribución esperada si las calificaciones se distribuyeron normalmente (la mayoría son promedio, y relativamente pocas son increíbles o terribles). En la Figura\(\PageIndex{2}\)(b), se pueden ver posibles resultados de este estudio imaginario y se puede ver claramente en qué se diferencian de la distribución esperada.
En el proceso de probar estas hipótesis, hay cuatro posibles resultados. Estos están determinados por dos factores: (1) la realidad, y (2) lo que encuentra el investigador (ver Figura\(\PageIndex{3}\)). El mejor resultado posible es la detección precisa. Esto quiere decir que la conclusión del investigador refleja la realidad. En nuestro ejemplo, pretendamos que los estudiantes más maduros rinden un poco mejor. Si esto es lo que la investigadora encuentra en sus datos, su análisis califica como una detección precisa de la realidad. Otra forma de detección precisa es cuando un investigador no encuentra evidencia de un fenómeno, ¡pero ese fenómeno en realidad no existe de todos modos! Usando este mismo ejemplo, pretendamos ahora que la madurez no tiene nada que ver con el rendimiento académico. Quizás el rendimiento académico se relaciona en cambio con la inteligencia o los hábitos de estudio. Si la investigadora no encuentra evidencia de un vínculo entre madurez y calificaciones y no existe realmente ninguna, también habrá logrado una detección precisa.
Figura\(\PageIndex{2}\): Distribuciones de calificaciones en un estudio imaginario. a) Calificaciones esperadas si no hubo diferencia entre los dos grupos. b) Calificaciones reales del curso por edad. [Esta obra, “Distribuciones de calificaciones”, está licenciada bajo CC BY-SA 4.0 de Judy Schmitt. Es un derivado de “Tabla 2” de Erin I. Smith/Noba, el cual está licenciado bajo CC BY-NC-SA 4.0.]
Hay un par de formas en que las conclusiones de la investigación podrían estar equivocadas. A uno se le denomina error Tipo I —cuando el investigador concluye que existe una relación entre dos variables pero, en realidad, no la hay. Volvamos a nuestro ejemplo: Ahora pretendamos que no hay relación entre madurez y calificaciones, pero el investigador aún encuentra una. ¿Por qué sucede esto? Puede ser que su muestra, por casualidad, incluya a estudiantes mayores que también tienen mejores hábitos de estudio y se desempeñan mejor: El investigador ha “encontrado” una relación (los datos parecen mostrar que la edad se correlaciona significativamente con el rendimiento académico), pero lo cierto es que la relación aparente es puramente coincidente—el resultado de que estos estudiantes mayores específicos en esta muestra en particular tienen hábitos de estudio superiores a la media (la causa real de la relación). Es posible que siempre hayan tenido hábitos de estudio superiores, incluso cuando eran jóvenes.
Otro posible resultado de NHST es un error Tipo II, cuando los datos no muestran una relación entre variables que realmente existe. En nuestro ejemplo, esta vez pretendemos que la madurez está —en realidad— asociada con el rendimiento académico, pero la investigadora no la encuentra en su muestra. Quizás fue solo su mala suerte que sus alumnos mayores solo estén teniendo un día libre, padeciendo ansiedad ante las pruebas, o fueran incaracterísticamente descuidados con su tarea: Las peculiaridades de su particular muestra, por casualidad, impiden que la investigadora identifique la relación real entre madurez y rendimiento académico.
Figura\(\PageIndex{3}\): Detección precisa y errores en la investigación
Este tipo de errores te pueden preocupar, que simplemente no hay forma de saber si los datos son buenos o no. Los investigadores comparten sus preocupaciones y las abordan mediante el uso de valores de probabilidad (valores p) para establecer un umbral para los errores de Tipo I o Tipo II. Cuando los investigadores escriben que un hallazgo particular es “significativo a un nivel p < .05”, están diciendo que si el mismo estudio se repitiera 100 veces, deberíamos esperar que este resultado ocurra —por casualidad— menos de cinco veces. Es decir, en este caso, es poco probable que se produzca un error de Tipo I. Los estudiosos a veces discuten sobre el umbral exacto que debe usarse para la probabilidad. Los más comunes en la ciencia psicológica son .05 (5% de probabilidad), .01 (1% de probabilidad) y .001 (1/10 de 1% de probabilidad). Recuerde, la ciencia psico-lógica no se basa en pruebas definitivas; se trata de la probabilidad de ver un resultado específico. Esta es también la razón por la que es tan importante que los hallazgos científicos se repliquen en estudios adicionales.
Es por tales metodologías que la ciencia es generalmente confiable. No todas las afirmaciones y explicaciones son iguales; algunas conclusiones son mejores apuestas, por así decirlo. Las afirmaciones científicas tienen más probabilidades de ser correctas y predecir resultados reales que las opiniones de “sentido común” y las anécdotas personales. Esto se debe a que los investigadores consideran la mejor manera de preparar y asegurar a sus sujetos, recopilar sistemáticamente datos de muestras grandes e, idealmente, representativas, y probar sus hallazgos contra la probabilidad.