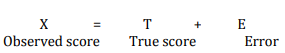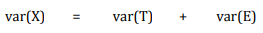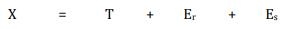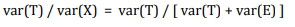Ahora que conocemos los diferentes tipos de confiabilidad y validez, intentemos sintetizar nuestra comprensión de la confiabilidad y validez de una manera matemática utilizando la teoría de pruebas clásica, también llamada teoría de puntaje verdadero. Se trata de una teoría psicométrica que examina cómo funciona la medición, qué mide y qué no mide. Esta teoría postula que cada observación tiene una verdadera puntuación T que se puede observar con precisión si no hubo errores en la medición. Sin embargo, la presencia de errores de medición E da como resultado una desviación de la puntuación observada X de la puntuación verdadera de la siguiente manera:
A través de un conjunto de puntuaciones observadas, la varianza de las puntuaciones observadas y verdaderas se puede relacionar usando una ecuación similar:
El objetivo del análisis psicométrico es estimar y minimizar si es posible la varianza de error var (E), de manera que la puntuación observada X sea una buena medida de la verdadera puntuación T.
Los errores de medición pueden ser de dos tipos: error aleatorio y error sistemático. El error aleatorio es el error que puede atribuirse a un conjunto de factores externos desconocidos e incontrolables que influyen aleatoriamente en algunas observaciones pero no en otras. Como ejemplo, durante el tiempo de medición, algunos encuestados pueden estar en un estado de ánimo más agradable que otros, lo que puede influir en cómo responden a los ítems de medición. Por ejemplo, los encuestados en un estado de ánimo más agradable pueden responder más positivamente a construcciones como la autoestima, la satisfacción y la felicidad que aquellos que están de mal humor. Sin embargo, no es posible anticipar qué sujeto se encuentra en qué tipo de estado de ánimo o control para el efecto del estado de ánimo en estudios de investigación. Asimismo, a nivel organizacional, si estamos midiendo el desempeño de la empresa, los cambios regulatorios o ambientales pueden afectar el desempeño de algunas firmas en una muestra observada pero no otras. Por lo tanto, el error aleatorio se considera “ruido” en la medición y generalmente se ignora.
El error sistemático es un error que se introduce por factores que afectan sistemáticamente todas las observaciones de un constructo a través de una muestra completa de manera sistemática. En nuestro ejemplo anterior de desempeño de la firma, dado que la reciente crisis financiera impactó el desempeño de las firmas financieras desproporcionadamente más que cualquier otro tipo de firmas como las empresas manufactureras o de servicios, si nuestra muestra consistió únicamente en firmas financieras, podemos esperar una reducción sistemática de desempeño de todas las firmas de nuestra muestra debido a la crisis financiera. A diferencia del error aleatorio, que puede ser positivo negativo, o cero, a través de la observación en una muestra, los errores sistemáticos tienden a ser consistentemente positivos o negativos en toda la muestra. De ahí que el error sistemático a veces se considere como “sesgo” en la medición y debe corregirse.
Dado que una puntuación observada puede incluir errores aleatorios y sistemáticos, nuestra ecuación de puntuación verdadera puede modificarse como:
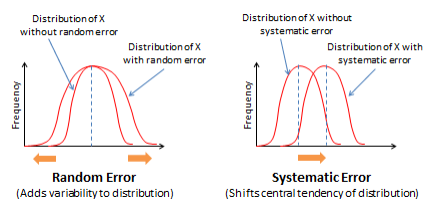
Figura 7.3.Figura 7.3. Efectos de errores aleatorios y sistemáticos
¿Qué implica el error aleatorio y sistemático para los procedimientos de medición? Al aumentar la variabilidad en las observaciones, el error aleatorio reduce la confiabilidad de la medición. En contraste, al cambiar la medida de tendencia central, el error sistemático reduce la validez de la medición. Las preocupaciones de validez son problemas mucho más serios en la medición que los problemas de confiabilidad, porque una medida inválida probablemente está midiendo un constructo diferente al que pretendíamos, y por lo tanto los problemas de validez arrojan serias dudas sobre los hallazgos derivados del análisis estadístico.
Tenga en cuenta que la confiabilidad es una relación o una fracción que captura qué tan cerca está la puntuación verdadera en relación con la puntuación observada. Por lo tanto, la confiabilidad se puede expresar como:
Si var (T) = var (X), entonces la puntuación verdadera tiene la misma variabilidad que la puntuación observada, y la confiabilidad es 1.0.