El muestreo probabilístico es una técnica en la que cada unidad de la población tiene una probabilidad (probabilidad distinta de cero) de ser seleccionada en la muestra, y esta oportunidad se puede determinar con precisión. Las estadísticas muestrales así producidas, como la media muestral o la desviación estándar, son estimaciones imparciales de los parámetros poblacionales, siempre y cuando las unidades muestreadas se ponderen de acuerdo a su probabilidad de selección. Todos los muestreos probabilísticos tienen dos atributos en común: (1) cada unidad de la población tiene una probabilidad conocida distinta de cero de ser muestreada, y (2) el procedimiento de muestreo implica una selección aleatoria en algún momento. Los diferentes tipos de técnicas de muestreo probabilístico incluyen:
Muestreo aleatorio simple. En esta técnica, a todos los subconjuntos posibles de una población (más exactamente, de un marco de muestreo) se les da la misma probabilidad de ser seleccionados. La probabilidad de seleccionar cualquier conjunto de n unidades de un total de N unidades en una trama de muestreo es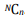 . Por lo tanto, las estadísticas muestrales son estimaciones imparciales de los parámetros poblacionales, sin ninguna ponderación. El muestreo aleatorio simple implica seleccionar aleatoriamente a los encuestados de un marco de muestreo, pero con marcos de muestreo grandes, generalmente se usa una tabla de números aleatorios o un generador computarizado de números aleatorios. Por ejemplo, si deseas seleccionar 200 firmas para encuestar de una lista de 1000 firmas, si esta lista se ingresa en una hoja de cálculo como Excel, puedes usar la función RAND () de Excel para generar números aleatorios para cada uno de los 1000 clientes de esa lista. A continuación, ordena la lista en orden creciente de su número aleatorio correspondiente y selecciona los primeros 200 clientes de esa lista ordenada. Esta es la más simple de todas las técnicas de muestreo probabilístico; sin embargo, la simplicidad es también la fuerza de esta técnica. Debido a que el marco de muestreo no está subdividido o dividido, la muestra es imparcial y las inferencias son más generalizables entre todas las técnicas de muestreo probabilístico.
. Por lo tanto, las estadísticas muestrales son estimaciones imparciales de los parámetros poblacionales, sin ninguna ponderación. El muestreo aleatorio simple implica seleccionar aleatoriamente a los encuestados de un marco de muestreo, pero con marcos de muestreo grandes, generalmente se usa una tabla de números aleatorios o un generador computarizado de números aleatorios. Por ejemplo, si deseas seleccionar 200 firmas para encuestar de una lista de 1000 firmas, si esta lista se ingresa en una hoja de cálculo como Excel, puedes usar la función RAND () de Excel para generar números aleatorios para cada uno de los 1000 clientes de esa lista. A continuación, ordena la lista en orden creciente de su número aleatorio correspondiente y selecciona los primeros 200 clientes de esa lista ordenada. Esta es la más simple de todas las técnicas de muestreo probabilístico; sin embargo, la simplicidad es también la fuerza de esta técnica. Debido a que el marco de muestreo no está subdividido o dividido, la muestra es imparcial y las inferencias son más generalizables entre todas las técnicas de muestreo probabilístico.
Muestreo sistemático. En esta técnica, el marco de muestreo se ordena de acuerdo con algunos criterios y los elementos se seleccionan a intervalos regulares a través de esa lista ordenada. El muestreo sistemático implica un inicio aleatorio y luego procede con la selección de cada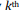 elemento a partir de ese punto, donde k = N/n, donde k es la relación del tamaño de trama de muestreo N y el tamaño de muestra deseado n, y se denomina formalmente el relación de muestreo. Es importante que el punto de partida no sea automáticamente el primero en la lista, sino que se elija aleatoriamente dentro de los primeros k elementos de la lista. En nuestro ejemplo anterior de seleccionar 200 firmas de una lista de 1000 firmas, puede ordenar las 1000 firmas en orden creciente (o decreciente) de su tamaño (es decir, recuento de empleados o ingresos anuales), seleccionar aleatoriamente una de las primeras cinco firmas en la lista ordenada, y luego seleccionar cada quinta firma de la lista. Este proceso asegurará que no haya una sobrerrepresentación de empresas grandes o pequeñas en su muestra, sino que las firmas de todos los tamaños generalmente estén representadas de manera uniforme, ya que está en su marco de muestreo. Es decir, la muestra es representativa de la población, al menos con base en el criterio de clasificación.
elemento a partir de ese punto, donde k = N/n, donde k es la relación del tamaño de trama de muestreo N y el tamaño de muestra deseado n, y se denomina formalmente el relación de muestreo. Es importante que el punto de partida no sea automáticamente el primero en la lista, sino que se elija aleatoriamente dentro de los primeros k elementos de la lista. En nuestro ejemplo anterior de seleccionar 200 firmas de una lista de 1000 firmas, puede ordenar las 1000 firmas en orden creciente (o decreciente) de su tamaño (es decir, recuento de empleados o ingresos anuales), seleccionar aleatoriamente una de las primeras cinco firmas en la lista ordenada, y luego seleccionar cada quinta firma de la lista. Este proceso asegurará que no haya una sobrerrepresentación de empresas grandes o pequeñas en su muestra, sino que las firmas de todos los tamaños generalmente estén representadas de manera uniforme, ya que está en su marco de muestreo. Es decir, la muestra es representativa de la población, al menos con base en el criterio de clasificación.
Muestreo estratificado. En el muestreo estratificado, el marco de muestreo se divide en subgrupos homogéneos y no superpuestos (llamados “estratos”), y se dibuja una muestra aleatoria simple dentro de cada subgrupo. En el ejemplo anterior de seleccionar 200 firmas de una lista de 1000 firmas, puede comenzar categorizando las firmas en función de su tamaño como grandes (más de 500 empleados), medianas (entre 50 y 500 empleados) y pequeñas (menos de 50 empleados). Luego puedes seleccionar aleatoriamente 67 firmas de cada subgrupo para formar tu muestra de 200 firmas. Sin embargo, dado que hay muchas más pequeñas empresas en un marco de muestreo que las grandes, tener un número igual de pequeñas, medianas y grandes empresas hará que la muestra sea menos representativa de la población (es decir, sesgada a favor de las grandes empresas que son menos en número en la población objetivo). Esto se denomina muestreo estratificado no proporcional porque la proporción de muestra dentro de cada subgrupo no refleja las proporciones en el marco de muestreo (o la población de interés), y el subgrupo más pequeño (empresas de gran tamaño) está sobremuestreado. Una técnica alternativa será seleccionar muestras de subgrupos en proporción a su tamaño en la población. Por ejemplo, si hay 100 grandes firmas, 300 medianas y 600 pequeñas, se pueden muestrear 20 firmas del grupo “grande”, 60 del grupo “mediano” y 120 del grupo “pequeño”. En este caso, la distribución proporcional de las empresas en la población se retiene en la muestra, y de ahí que esta técnica se denomina muestreo estratificado proporcional. Obsérvese que el enfoque no proporcional es particularmente efectivo en la representación de subgrupos pequeños, como las empresas de gran tamaño, y no necesariamente es menos representativo de la población en comparación con el enfoque proporcional, siempre y cuando los hallazgos del enfoque no proporcional se ponderen de acuerdo con un proporción del subgrupo en la población general.
Muestreo por conglomerados Si tienes una población dispersa en una amplia región geográfica, puede que no sea factible realizar un muestreo aleatorio simple de toda la población. En tal caso, puede ser razonable dividir la población en “racimos” (generalmente a lo largo de los límites geográficos), muestrear aleatoriamente algunos conglomerados y medir todas las unidades dentro de ese clúster. Por ejemplo, si deseas probar gobiernos municipales en el estado de Nueva York, en lugar de viajar por todo el estado para entrevistar a funcionarios clave de la ciudad (como quizás tengas que ver con una simple muestra aleatoria), puedes agrupar estos gobiernos en función de sus condados, seleccionar aleatoriamente un conjunto de tres condados y luego entrevistar a funcionarios de cada funcionario de esos condados. Sin embargo, dependiendo de las diferencias entre conglomerados, la variabilidad de las estimaciones de muestra en una muestra de conglomerado generalmente será mayor que la de una muestra aleatoria simple, y por lo tanto los resultados son menos generalizables a la población que los obtenidos de muestras aleatorias simples.
Muestreo por pares coincidentes. En ocasiones, los investigadores pueden querer comparar dos subgrupos dentro de una población con base en un criterio específico. Por ejemplo, ¿por qué algunas firmas son consistentemente más rentables que otras? Para llevar a cabo dicho estudio, habría que categorizar un marco de muestreo de empresas en firmas “de alta rentabilidad” y “empresas de baja rentabilidad” en función de los márgenes brutos, ganancias por acción o alguna otra medida de rentabilidad. Luego seleccionaría una muestra aleatoria simple de firmas en un subgrupo, y emparejaría cada firma de este grupo con una firma del segundo subgrupo, en función de su tamaño, segmento de industria y/u otros criterios de coincidencia. Ahora, tiene dos muestras emparejadas de firmas de alta rentabilidad y baja rentabilidad que puede estudiar con mayor detalle. Esta técnica de muestreo de pares emparejados suele ser una forma ideal de entender las diferencias bipolares entre diferentes subgrupos dentro de una población determinada.
Muestreo multietapa. Las técnicas de muestreo probabilístico descritas anteriormente son ejemplos de técnicas de muestreo de una sola etapa. Dependiendo de sus necesidades de muestreo, puede combinar estas técnicas de una sola etapa para realizar un muestreo multietapa. Por ejemplo, puede estratificar una lista de negocios en función del tamaño de la empresa y luego realizar un muestreo sistemático dentro de cada estrato. Se trata de una combinación de dos etapas de muestreo estratificado y sistemático. De igual manera, puedes comenzar con un grupo de distritos escolares en el estado de Nueva York, y dentro de cada clúster, seleccionar una muestra aleatoria simple de escuelas; dentro de cada escuela, seleccionar una muestra aleatoria simple de niveles de grado; y dentro de cada nivel de grado, seleccionar una muestra aleatoria simple de estudiantes para su estudio. En este caso, se tiene un proceso de muestreo de cuatro etapas que consiste en muestreo por conglomerado y muestreo aleatorio simple.

