
10.8: t Distribución
- Page ID
- 151998

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Objetivos de aprendizaje
- Indicar la diferencia entre la forma de la\(t\) distribución y la distribución normal
- Indicar cómo la diferencia entre la forma de la\(t\) distribución y la distribución normal se ve afectada por los grados de libertad
- Usar una\(t\) tabla para encontrar el valor de\(t\) usar en un intervalo de confianza
- Use la\(t\) calculadora para encontrar el valor de\(t\) usar en un intervalo de confianza
En la introducción a las distribuciones normales se demostró que\(95\%\) del área de una distribución normal se encuentra dentro de las desviaciones\(1.96\) estándar de la media. Por lo tanto, si muestreaste aleatoriamente un valor de una distribución normal con una media de\(100\), la probabilidad de que estuviera dentro\(1.96\sigma \) de\(100\) es\(0.95\). De igual manera, si\(N\) muestrea valores de la población, la probabilidad de que la media muestral (\(M\)) esté dentro\(1.96\sigma _M\) de\(100\) es\(0.95\).
Ahora considera el caso en el que tienes una distribución normal pero no conoces la desviación estándar. \(N\)Muestrea los valores y calcula la media muestral (\(M\)) y estimas el error estándar de la media (\(\sigma _M\)) con\(s_M\). ¿Cuál es la probabilidad de\(M\) que esté dentro\(1.96 s_M\) de la población media (\(\mu\))?
Este es un problema difícil porque hay dos formas en las que\(M\) podría ser más que\(1.96 s_M\) de\(\mu\):
- \(M\)podría, por casualidad, ser muy alto o muy bajo y
- \(s_M\)podría, por casualidad, ser muy bajo.
Intuitivamente, tiene sentido que la probabilidad de estar dentro de los errores\(1.96\) estándar de la media sea menor que en el caso en que se conozca la desviación estándar (y no se pueda subestimar). Pero exactamente ¿cuánto más pequeño? Afortunadamente, la manera de resolver este tipo de problemas fue resuelta a principios de\(20^{th}\) siglo por W. S. Gosset quien determinó la distribución de una media dividida por una estimación de su error estándar. Esta distribución se llama\(t\) distribución del Estudiante o a veces solo la\(t\) distribución. Gosset trabajó la\(t\) distribución y las pruebas estadísticas asociadas mientras trabajaba para una cervecería en Irlanda. Debido a un acuerdo contractual con la cervecería, publicó el artículo bajo el seudónimo de “Estudiante”. Es por ello que la\(t\) prueba se llama la “\(t\)Prueba de estudiante”.
La\(t\) distribución es muy similar a la distribución normal cuando la estimación de varianza se basa en muchos grados de libertad, pero tiene relativamente más puntuaciones en sus colas cuando hay menos grados de libertad. La figura\(\PageIndex{1}\) muestra\(t\) distribuciones con\(2\)\(4\), y\(10\) grados de libertad y la distribución normal estándar. Observe que la distribución normal tiene relativamente más puntuaciones en el centro de la distribución y la\(t\) distribución tiene relativamente más en las colas. Por lo tanto, la\(t\) distribución es leptokúrtica. La\(t\) distribución se acerca a la distribución normal a medida que aumentan los grados de libertad.
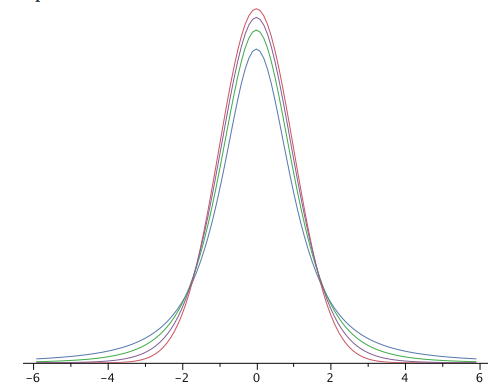
Dado que la\(t\) distribución es leptokúrtica, el porcentaje de la distribución dentro de las desviaciones\(1.96\) estándar de la media es menor que el\(95\%\) de la distribución normal. En la tabla se\(\PageIndex{1}\) muestra el número de desviaciones estándar de la media requerida para contener\(95\%\) y\(99\%\) del área de\(t\) distribución para diversos grados de libertad. Estos son los valores de los\(t\) que usas en un intervalo de confianza. Los valores correspondientes para la distribución normal son\(1.96\) y\(2.58\) respectivamente. Observe que con pocos grados de libertad, los valores de\(t\) son muy superiores a los valores correspondientes para una distribución normal y que la diferencia disminuye a medida que aumentan los grados de libertad. Los valores en Tabla se\(\PageIndex{1}\) pueden obtener de la calculadora “Buscar\(t\) para un intervalo de confianza”.
Tabla \(\PageIndex{1}\):\(t\) Tabla abreviada
| df | 0.95 | 0.99 |
|---|---|---|
| 2 | 4.303 | 9.925 |
| 3 | 3.182 | 5.841 |
| 4 | 2.776 | 4.604 |
| 5 | 2.571 | 4.032 |
| 8 | 2.306 | 3.355 |
| 10 | 2.228 | 3.169 |
| 20 | 2.086 | 2.845 |
| 50 | 2.009 | 2.678 |
| 100 | 1.984 | 2.626 |
Volviendo al problema planteado al inicio de esta sección, supongamos que muestreó\(9\) valores de una población normal y estimó el error estándar de la media (\(\sigma _M\)) con\(s_M\). ¿Cuál es la probabilidad de\(M\) que esté dentro\(1.96 s_M\) de\(\mu\)? Ya que el tamaño de la muestra es\(9\), los hay\(N - 1 = 8 df\). De Tabla se\(\PageIndex{1}\) puede ver que con\(8 df\) la probabilidad es\(0.95\) que la media esté dentro\(2.306 s_M\) de\(\mu\). Por lo tanto, la probabilidad de que esté dentro\(1.96 s_M\) de\(\mu\) es menor que\(0.95\).
Como se muestra en la Figura\(\PageIndex{2}\), la calculadora de "\(t\)distribución” puede ser utilizada para encontrar que\(0.086\) del área de una\(t\) distribución es más que las desviaciones\(1.96\) estándar de la media, por lo que la probabilidad de que\(M\) sería menor que\(1.96 s_M\) de\(\mu\) es\(1 - 0.086 = 0.914\).
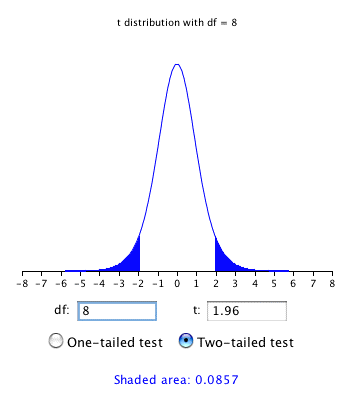
Como era de esperar, esta probabilidad es menor a la\(0.95\) que se habría obtenido si se\(\sigma _M\) hubiera conocido en lugar de estimado.