
7.2: Aproximaciones de distribución
- Page ID
- 151034

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Distribuciones binomiales, Poisson, gamma y gaussianas
La aproximación de Poisson a la distribución binomial
La siguiente aproximación es clásica. Deseamos demostrar que para pequeños\(p\) y suficientemente grandes\(n\)
\[P(X = k) = C(n, k)p^k (1 - p)^{n - k} \approx e^{-np} \dfrac{np}{k!}\]
Supongamos\(p = \mu/n\) con\(n\) grandes y\(\mu/n < 1\). Entonces,
\[P(X = k) = C(n, k) (\mu/n)^k (1 - \mu/n)^{n-k} = \dfrac{n(n - 1) \cdot \cdot \cdot (n - k + 1)}{n^k} (1 - \dfrac{\mu}{n})^{-k} (1 - \dfrac{\mu}{n})^n \dfrac{\mu^k}{k!}\]
El primer factor en la última expresión es la relación de polinomios en\(n\) del mismo grado\(k\), que debe acercarse a uno a medida que\(n\) se vuelve grande. El segundo factor se acerca a uno a medida que\(n\) se vuelve grande. Según una propiedad bien conocida del exponencial
\[(1 - \dfrac{\mu}{n})^n \to e^{-\mu}\]
como\(n \to \infty\).
El resultado es que para grandes\(n\),\(P(X = k) \approx e^{-\mu} \dfrac{\mu^k}{k!}\), dónde\(\mu = np\).
Las distribuciones de Poisson y Gamma
Supongamos que\(Y~\) Poisson (\(\lambda t\)). Ahora\(X~\) gamma (\(\alpha, \lambda\)) iff
\[P(X \le t) = \dfrac{\lambda^{\alpha}}{\Gamma (\alpha)} \int_{0}^{1} x^{\alpha - 1} e^{-\lambda x}\ dx = \dfrac{1}{\Gamma (\alpha)} \int_{0}^{t} (\lambda x)^{\alpha - 1} e^{\lambda x} d(\lambda x) = \dfrac{1}{\Gamma (\alpha)} \int_{0}^{\lambda t} u^{\alpha - 1} e^{-\mu}\ du\]
Una integral definida bien conocida, obtenida por integración por partes, es
\[int_{\alpha}^{\infty} t^{n -1} e^{-t}dt = \Gamma (n) e^{-a} \sum_{k = 1}^{n - 1} \dfrac{a^k}{k!}\]
con\(\Gamma (n) = (n - 1)!\).
Señalando que\(1 = e^{-a}e^{a} = e^{-a} \sum_{k = 0}^{\infty} \dfrac{a^k}{k!}\) encontramos después de algunos álgebra simple que
\[\dfrac{1}{\Gamma(n)} \int_{0}^{a} t^{n -1} e^{-t}\ dt = e^{-a} \sum_{k = n}^{\infty} \dfrac{a^k}{k!}\]
Para\(a = \lambda t\) y\(\alpha = n\), tenemos la siguiente igualdad iff\(X~\) gamma (\(\alpha, \lambda\))
\[P(X \le t) = \dfrac{1}{\Gamma(n)} \int_{0}^{\lambda t} u^{n -1}d^{-u}\ du = e^{-\lambda t} \sum_{k = n}^{\infty} \dfrac{(\lambda t)^k}{k!}\]
Ahora
\[P(Y \ge n) = e^{-\lambda t} \sum_{k = n}^{\infty} \dfrac{(\lambda t)^k}{k!}\]
iff\(Y~\) Poisson (\(\lambda t\).
La aproximación gaussiana (normal)
El teorema del límite central, referido en la discusión de la distribución gaussiana o normal anterior, sugiere que las distribuciones binomial y de Poisson deben ser aproximadas por la gaussiana. El número de éxitos en n ensayos tiene la distribución binomial (n, p). Esta variable aleatoria puede ser expresada
\[X = \sum_{i = 1}^{n} I_{E_i}\]
Dado que el valor medio de\(X\) es\(np\) y la varianza es\(npq\), la distribución debe ser aproximadamente\(N(np, npq)\).
El uso de la función generadora muestra que la suma de variables aleatorias de Poisson independientes es Poisson. Ahora si\(X~) Poisson (\(\mu\)), entonces\(X\) puede considerarse la suma de variables aleatorias\(n\) independientes, cada Poisson (\(\mu/n\)). Dado que el valor medio y la varianza son ambos\(\mu\), es razonable suponer que supongamos que\(X\) es aproximadamente\(N(\mu, \mu)\).
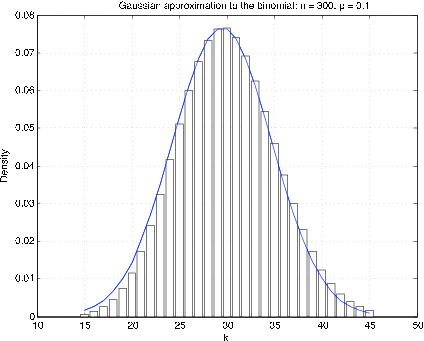
Por lo general, es mejor comparar las funciones de distribución. Dado que las distribuciones binomial y Poisson son de valor entero, resulta que la mejor aproximación gaussiana se obtiene haciendo una “corrección de continuidad”. Para obtener una aproximación a una densidad para una variable aleatoria de valor entero, la probabilidad at\(t = k\) se representa por un rectángulo de altura\(p_k\) y unidad de ancho, con\(k\) como punto medio. La Figura 1 muestra una gráfica de la “densidad” y la densidad gaussiana correspondiente para\(n = 300\),\(p = 0.1\). Es evidente que la densidad gaussiana está compensada aproximadamente 1/2. Para aproximar la probabilidad\(X \le k\), tome el área bajo la curva desde\(k\) + 1/2; esto se denomina corrección de continuidad.
Uso de m-procedimientos para comparar
Tenemos dos procedimientos m para hacer las comparaciones. En primer lugar, consideramos la aproximación de la
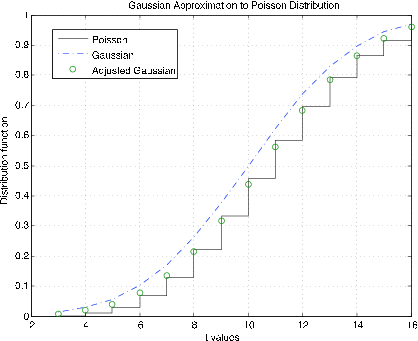
Figura 7.2.9. Aproximación gaussiana a la función de distribución de Poisson\(\mu\) = 10.
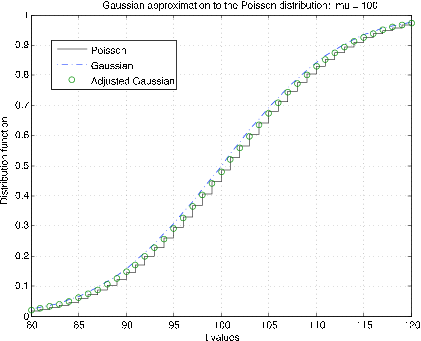
Distribución de Poisson (\(\mu\)). El poissapp m-procedimiento requiere un valor de\(\mu\), selecciona un rango adecuado sobre\(k = \mu\) y traza la función de distribución para la distribución de Poisson (escaleras) y la distribución normal (gaussiana) (punto de guión) para\(N(\mu, \mu)\). Además, la corrección de continuidad se aplica a la distribución gaussiana en valores enteros (círculos). La Figura 7.2.10 muestra parcelas para\(\mu\) = 10. Es claro que la corrección de continuidad proporciona una aproximación mucho mejor. Las parcelas de la Figura 7.2.11 son para\(\mu\) = 100. Aquí la corrección de continuidad proporciona la mejor aproximación, pero no tanto como para los más pequeños\(\mu\).
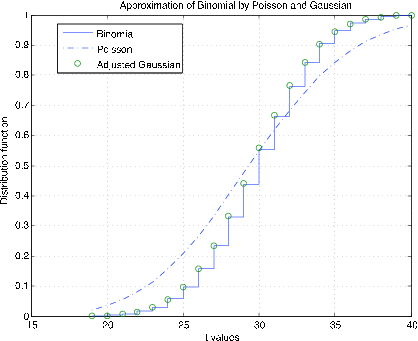
El bincomp m-procedimiento compara las distribuciones binomial, gaussiana y Poisson. Pide valores de\(n\) y\(p\), selecciona\(k\) valores adecuados y traza la función de distribución para el binomio, una aproximación continua a la función de distribución para el Poisson y valores ajustados de continuidad de la función de distribución gaussiana en los valores enteros. La Figura 7.2.11 muestra parcelas para\(n = 1000\),\(p = 0.03\). El buen acuerdo de las tres funciones de distribución es evidente. La Figura 7.2.12 muestra parcelas para\(n = 50, p = 0.6\). Todavía hay un buen acuerdo entre el binomio y el gaussiano ajustado. Sin embargo, la distribución de Poisson no rastrea muy bien. La dificultad, como vemos en la unidad Varianza, es la diferencia en varianzas,\(npq\) para el binomio en comparación con\(np\) para el Poisson.
Aproximación de una variable aleatoria real por variables aleatorias simples
Las variables aleatorias simples juegan un papel importante, tanto en teoría como en aplicaciones. En la unidad Variables Aleatorias, mostramos cómo una variable aleatoria simple está determinada por el conjunto de puntos en la línea real que representan los valores posibles y el conjunto correspondiente de probabilidades de que cada uno de estos valores sea tomado. Esto describe la distribución de la variable aleatoria y hace posibles cálculos de probabilidades de eventos y parámetros para la distribución.
Una variable aleatoria continua se caracteriza por un conjunto de valores posibles distribuidos continuamente a lo largo de un intervalo o colección de intervalos. En este caso, la probabilidad también se extiende sin problemas. La distribución es descrita por una función de densidad de probabilidad, cuyo valor en cualquier punto indica “la probabilidad por unidad de longitud” cerca del punto. Se obtiene una aproximación simple subdividiendo un intervalo que incluye el rango (el conjunto de valores posibles) en subintervalos lo suficientemente pequeños para que la densidad sea aproximadamente constante en cada subintervalo. Se selecciona un punto en cada subintervalo y se le asigna la masa de probabilidad en su subintervalo. La combinación de los puntos seleccionados y las probabilidades correspondientes describe la distribución de una variable aleatoria simple aproximada. Los cálculos basados en esta distribución aproximan los cálculos correspondientes sobre la distribución continua.
Antes de examinar un procedimiento de aproximación general que tiene consecuencias significativas para tratamientos posteriores, consideramos algunos ejemplos ilustrativos.
Ejemplo\(\PageIndex{10}\): Simple approximation to Poisson
Una variable aleatoria con la distribución de Poisson no tiene límites. Sin embargo, para un parámetro dado valor μ, la probabilidad de\(k \ge n\),\(n\) suficientemente grande, es insignificante. Experimento indica\(n = \mu + 6\sqrt{\mu}\) (es decir, seis desviaciones estándar más allá de la media) es un valor razonable para\(5 \le \mu \le 200\).
Solución
>> mu = [5 10 20 30 40 50 70 100 150 200];
>> K = zeros(1,length(mu));
>> p = zeros(1,length(mu));
>> for i = 1:length(mu)
K(i) = floor(mu(i)+ 6*sqrt(mu(i)));
p(i) = cpoisson(mu(i),K(i));
end
>> disp([mu;K;p*1e6]')
5.0000 18.0000 5.4163 % Residual probabilities are 0.000001
10.0000 28.0000 2.2535 % times the numbers in the last column.
20.0000 46.0000 0.4540 % K is the value of k needed to achieve
30.0000 62.0000 0.2140 % the residual shown.
40.0000 77.0000 0.1354
50.0000 92.0000 0.0668
70.0000 120.0000 0.0359
100.0000 160.0000 0.0205
150.0000 223.0000 0.0159
200.0000 284.0000 0.0133
Un procedimiento m para aproximación discreta
Si\(X\) está acotado, absolutamente continuo con la función de densidad\(f_X\), el procedimiento m tappr establece la distribución para una variable aleatoria simple aproximada. Un intervalo que contiene el rango de\(X\) se divide en un número especificado de subdivisiones iguales. La masa de probabilidad para cada subintervalo se asigna al punto medio. Si\(dx\) es la longitud de los subintervalos, entonces la integral de la función de densidad sobre el subintervalo se aproxima por\(f_X(t_i) dx\). donde\(t_i\) está el punto medio. En efecto, la gráfica de la densidad sobre el subintervalo se aproxima por un rectángulo de longitud\(dx\) y altura\(f_X(t_i)\). Una vez establecida la distribución simple de aproximación, se realizan cálculos como para variables aleatorias simples.
Ejemplo\(\PageIndex{11}\): a numerical example
Supongamos\(f_X(t) = 3t^2\),\(0 \le t \le 1\). Determinar\(P(0.2 \le X \le 0.9)\).
Solución
En este caso, una solución analítica es fácil. \(F_X(t) = t^3\)en el intervalo [0, 1], entonces
\(P = 0.9^3 - 0.2^3 = 0.7210\). Usamos tappr de la siguiente manera.
>> tappr Enter matrix [a b] of x-range endpoints [0 1] Enter number of x approximation points 200 Enter density as a function of t 3*t.^2 Use row matrices X and PX as in the simple case >> M = (X >= 0.2)&(X <= 0.9); >> p = M*PX' p = 0.7210
Debido a la regularidad de la densidad y al número de puntos de aproximación, el resultado concuerda bastante bien con el valor teórico.
El siguiente ejemplo es uno más complejo. En particular, la distribución no está acotada. Sin embargo, es fácil determinar un límite más allá del cual la probabilidad es insignificante.
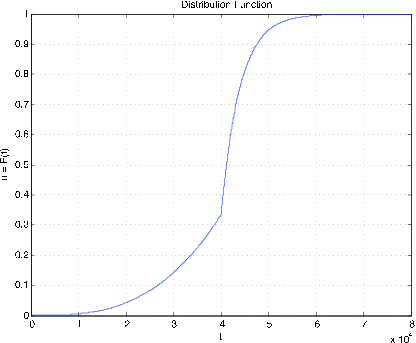
Figura 7.2.13. Función de distribución para Ejemplo 7.2.12.
Ejemplo\(\PageIndex{12}\): Radial tire mileage
La vida (en millas) de cierta marca de llantas radiales puede estar representada por una variable aleatoria\(X\) con densidad
\(f_X(t) = \begin{cases} t^2/a^3 & \text{for}\ \ 0 \le t < a \\ (b/a) e^{-k(t-a)} \text{for}\ \ a \le t \end{cases}\)
dónde\(a = 40,000\),\(b = 20/3\), y\(k = 1/4000\). Determinar\(P(X \ge 45,000\).
>> a = 40000; >> b = 20/3; >> k = 1/4000; >> % Test shows cutoff point of 80000 should be satisfactory >> tappr Enter matrix [a b] of x-range endpoints [0 80000] Enter number of x approximation points 80000/20 Enter density as a function of t (t.^2/a^3).*(t < 40000) + ... (b/a)*exp(k*(a-t)).*(t >= 40000) Use row matrices X and PX as in the simple case >> P = (X >= 45000)*PX' P = 0.1910 % Theoretical value = (2/3)exp(-5/4) = 0.191003 >> cdbn Enter row matrix of VALUES X Enter row matrix of PROBABILITIES PX % See Figure 7.2.14 for plot
En este caso, utilizamos un número bastante grande de puntos de aproximación. Como consecuencia, los resultados son bastante precisos. En el caso de una sola variable, la designación de un gran número de puntos de aproximación generalmente no causa ningún problema de memoria de computadora.
El procedimiento general de aproximación
Mostramos ahora que cualquier variable aleatoria real delimitada puede aproximarse tan cerca como se desee por una variable aleatoria simple (es decir, una que tenga un conjunto finito de valores posibles). Para el caso no acotado, la aproximación es cercana excepto en una porción del rango que tiene probabilidad total arbitrariamente pequeña.
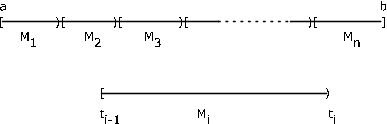
Limitamos nuestra discusión al caso acotado, en el que el rango de\(X\) está limitado a un intervalo limitado\(I = [a, b]\). Supongamos que\(I\) se divide en\(n\) subintervalos por puntos\(t_i\)\(1 \le i \le n - 1\),, con\(a = t_0\) y\(b = t_n\). \(M_i = [t_{i- 1}, t_i)\)Sea el subintervalo\(i\) th,\(1 \le i \le n - 1\) y\(M_n = [t_{n - 1}, t_n]\) (ver Figura 7.14). Ahora la variable aleatoria\(X\) puede mapearse en cualquier punto del intervalo, y por lo tanto en cualquier punto en cada subintervalo\(M_i\). Dejar\(E_i X^{-1} (M_i)\) ser el conjunto de puntos mapeados en\(M_i\) por\(X\). Entonces la\(E_i\) forma una partición del espacio básico\(\Omega\). Para la subdivisión dada, formamos una variable aleatoria simple de la\(X_s\) siguiente manera. En cada subintervalo, elija un punto\(s_i\),\(t_{i - 1} \le s_i \le t_i\). Considera la variable aleatoria simple\(X_s = \sum_{i = 1}^{n} s_i I_{E_i}\).
Esta variable aleatoria está en forma canónica. Si\(\omega \in E_i\), entonces\(X(\omega) \in M_i\) y\(X_s (\omega) = s_i\). Ahora el valor absoluto de la diferencia satisface
\(|X(\omega) - X_s (\omega)| < t_i - t_{i - 1}\)la longitud del subintervalo\(M_i\)
Como esto es cierto para cada uno\(\omega\) y el subintervalo correspondiente, tenemos el hecho importante
\(|X(\omega) - X_s (\omega)|<\)longitud máxima del\(M_i\)
Al hacer los subintervalos lo suficientemente pequeños al aumentar el número de puntos de subdivisión, podemos hacer la diferencia lo más pequeña que queramos.
Si bien la elección del\(s_i\) es arbitraria en cada uno\(M_i\), la selección de\(s_i = t_{i - 1}\) (el punto final izquierdo) conduce a la propiedad\(X_s(\omega) \le X(\omega) \forall \omega\). En este caso, si sumamos puntos de subdivisión para disminuir el tamaño de algunos o todos los\(M_i\), la nueva aproximación simple\(Y_s\) satisface
\(X_s(\omega) = Y_s(\omega) \le X(\omega)\)\(\forall \omega\)
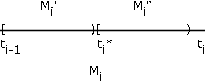
Para ver esto, considere\(t_i^{*} \in M_i\) (ver Figura 7.15). \(M_i\)se divide en\(M_i^{'} \bigcup M_i^{''}\) y\(E_i\) se divide en\(E_i^{'} \bigcup E_i^{''}\). \(X\)mapas\(E_i^{'}\) en\(M_i^{'}\) y\(E_i^{''}\) en\(M_i^{''}\). \(Y_s\)mapas\(E_i^{'}\)\(t_i\) y mapas\(E_i^{''}\) en\(t_i^{''}\) > t_i\). \(X_s\)mapas tanto\(E_i^{'}\) como\(E_i^{''}\) en\(t_i\). Así, la desigualdad afirmada debe mantenerse para cada una\(\omega\) Al tomar una secuencia de particiones en la que cada partición sucesiva refina la anterior (es decir, suma puntos de subdivisión) de tal manera que la longitud máxima del subintervalo vaya a cero, podemos formar una secuencia no decreciente de variables aleatorias simples \(X_n\)que aumentan a\(X\) para cada uno\(\omega\).
Este último resultado puede extenderse a variables aleatorias no delimitadas anteriormente. Simplemente deje que\(N\) el conjunto de puntos de subdivisión se extienda de\(a\) a\(N\), haciendo el último subintervalo\([N, \infty)\). Los subintervalos de\(a\) a\(N\) se hacen cada vez más cortos. El resultado es una secuencia no decreciente\(\{X_N: 1 \le N\}\) de variables aleatorias simples, con\(X_N(\omega) \to X(\omega)\) as\(N \to \infty\), para cada una\(\omega \in \Omega\).
Para los cálculos de probabilidad, simplemente seleccionamos un intervalo lo suficientemente\(I\) grande como para que la probabilidad exterior\(I\) sea insignificante y usamos una simple aproximación sobre\(I\).