
5.2: Capacitación y Pruebas



- Última actualización
- 31 oct 2022
- Guardar como PDF

( \newcommand{\kernel}{\mathrm{null}\,}\)
Con el conjunto de datos dividido en dos porciones seleccionadas aleatoriamente, podemos entrenar el modelo en la primera porción y probarlo en la segunda porción. La Figura 5.1 muestra el flujo general de este proceso de entrenamiento y prueba. A continuación te explicamos los detalles de este proceso para entrenar y probar el modelo que desarrollamos previamente para los resultados del benchmark Int2000.
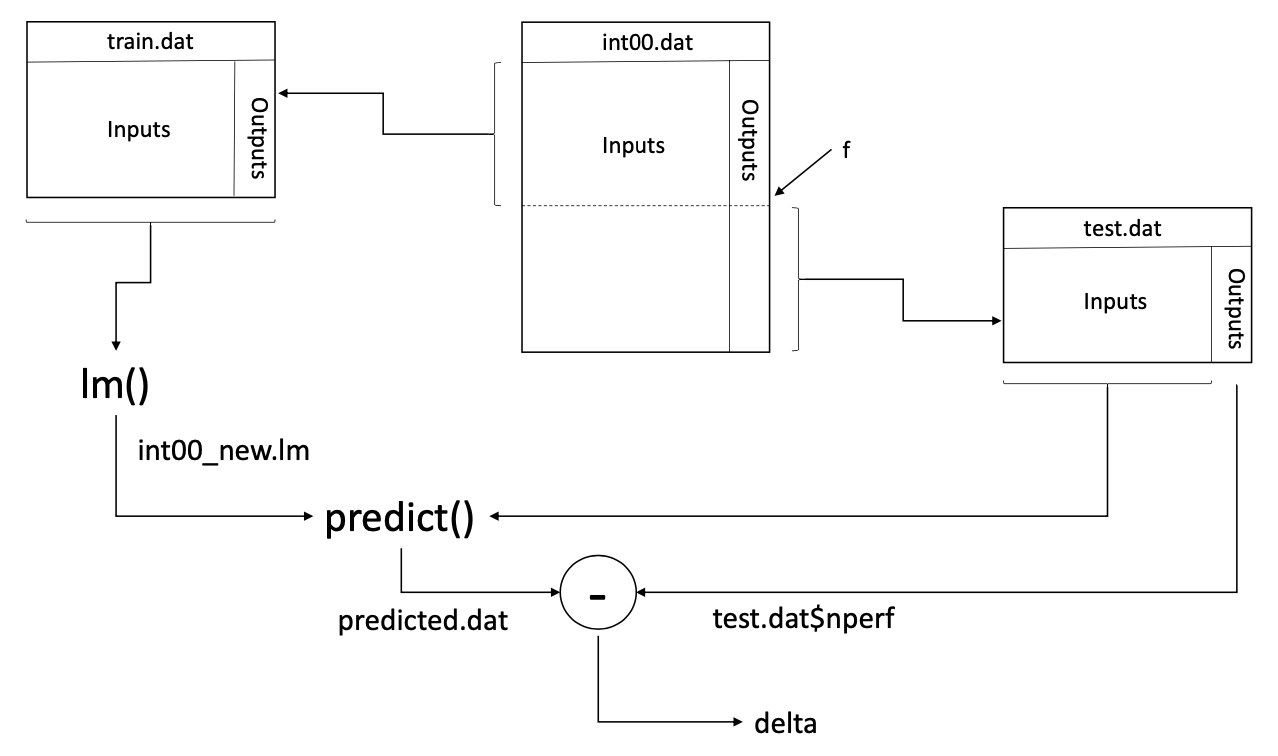
La siguiente declaración llama a la función lm () para generar un modelo de regresión utilizando los predictores que identificamos en el Capítulo 4 y el marco de datos train.dat que extraemos en la sección anterior. Luego asigna este modelo a la variable int00_new.lm. Nos referimos a este proceso de cálculo de los coeficientes del modelo como entrenamiento del modelo de regresión.
int00_new.lm <lm(nperf ~ clock + cores + voltage + channel + L1icache +
sqrt(L1icache) + L1dcache + sqrt(L1dcache) + L2cache + sqrt(L2cache), data = train.dat)La función predict () toma este nuevo modelo como uno de sus argumentos. Utiliza este modelo para calcular las salidas predichas cuando usamos el marco de datos test.dat como entrada, de la siguiente manera:
predicted.dat <predict(int00_new.lm, newdata=test.dat)Definimos la diferencia entre el rendimiento predicho y medido para cada procesador i para que sea i = Predictedi − Medido i, donde Predicho i es el valor predicho por el modelo, que se almacena en el marco de datos predicted.dat, y Medido i es la respuesta real del rendimiento medido, que previamente asignamos al marco de datos test.dat. La siguiente instrucción calcula el vector completo de estos valores de i y asigna el vector a la variable delta.
delta <predicted.dat test.dat$nperfTenga en cuenta que usamos la notación $ para seleccionar la columna con el valor de salida, nperf, del marco de datos test.dat.
La media de estas diferencias para n procesadores diferentes es:
ˉΔ=1n∑ni=1Δi
Un intervalo de confianza calculado para esta media nos dará alguna indicación de qué tan bien un modelo entrenado en el conjunto de datos train.dat predijo el rendimiento de los procesadores en el conjunto de datos test.dat. La función t.test () calcula un intervalo de confianza para el nivel de confianza deseado de estos valores de i de la siguiente manera:
> t.test(delta, conf.level = 0.95)
One Sample t-test
data: delta
t = -0.65496, df = 41, p-value = 0.5161
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:-2.232621 1.139121
sample estimates: mean of x -0.5467502Si la predicción fuera perfecta, entonces ∆i = 0. Si ∆i > 0, entonces el modelo predijo que el rendimiento sería mayor de lo que realmente era. A ∆i < 0, por otro lado, significa que el modelo predijo que el rendimiento fue menor de lo que realmente era. En consecuencia, si las predicciones fueran razonablemente buenas, esperaríamos ver un estrecho intervalo de confianza alrededor de cero. En este caso, se obtiene un intervalo de confianza del 95 por ciento de [-2.23, 1.14]. Dado que nperf se escala entre 0 y 100, este es un intervalo de confianza razonablemente estrecho que incluye cero. Por lo tanto, concluimos que el modelo es razonablemente bueno para predecir valores en el conjunto de datos test.dat cuando se entrena en el conjunto de datos train.dat.
Otra forma de obtener una idea de la calidad de las predicciones es generar una gráfica de dispersión de los valores de i usando la función plot ():
plot(delta)Esta llamada a la función produce la gráfica que se muestra en la Figura 5.2. Las buenas predicciones producirían una estrecha banda de valores uniformemente dispersos alrededor de cero. En esta cifra, sí vemos tal distribución, aunque hay algunos valores atípicos que están a más de diez puntos por encima o por debajo de cero.
Es importante darse cuenta de que la función sample () devolverá una permutación aleatoria diferente cada vez que la ejecutemos. Estas diferentes permutaciones particionarán diferentes procesadores (es decir, filas en el marco de datos) en el tren y conjuntos de prueba. Por lo tanto, si volvemos a ejecutar este experimento con exactamente las mismas entradas, es probable que obtengamos un intervalo de confianza diferente y un diagrama de dispersión de ∆i. Por ejemplo, cuando repetimos la misma prueba cinco veces con entradas idénticas, obtenemos los siguientes intervalos de confianza: [-1.94, 1.46], [-1.95, 2.68], [-2.66, 3.81], [-6.13, 0.75], [-4.21, 5.29]. De igual manera, variando la fracción de los datos que asignamos al tren y los conjuntos de prueba cambiando f = 0.5 también cambia los resultados.
Es una buena práctica ejecutar este tipo de experimentos varias veces y observar cómo cambian los resultados. Si ves que los resultados varían salvajemente cuando vuelves a ejecutar estas pruebas, tienes un buen motivo de preocupación. Por otro lado, una serie de resultados similares no significa necesariamente que tus resultados sean buenos, solo que sean reproducibles de manera consistente. A menudo es más fácil detectar un mal modelo que determinar que un modelo es bueno.
Con base en los resultados de intervalos de confianza repetidos y la gráfica de dispersión correspondiente, similar a la Figura 5.2, concluimos que este modelo es razonablemente bueno para predecir el rendimiento de un conjunto de procesadores cuando el modelo se entrena en un conjunto diferente de procesadores que ejecutan el mismo programa de referencia. No es perfecto, pero tampoco está tan mal. Si las diferencias son lo suficientemente grandes como para justificar preocupación depende de usted.
