
9.4: La distribución binomial
- Page ID
- 151637

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Como se puede imaginar, las distribuciones de probabilidad varían enormemente, y hay una enorme gama de distribuciones por ahí. Sin embargo, no todos son igualmente importantes. De hecho, la gran mayoría del contenido de este libro se basa en una de cinco distribuciones: la distribución binomial, la distribución normal, la distribución t, la distribución χ 2 (“chi-cuadrado”) y la distribución F. Ante esto, lo que voy a hacer en las próximas secciones es dar una breve introducción a las cinco, prestando especial atención al binomio y a lo normal. Comenzaré con la distribución binomial, ya que es la más simple de las cinco.
Introduciendo el binomio
La teoría de la probabilidad se originó en el intento de describir cómo funcionan los juegos de azar, por lo que parece apropiado que nuestra discusión sobre la distribución binomial implique una discusión sobre rodar dados y voltear monedas. Imaginemos un simple “experimento”: en mi manita caliente sostengo 20 dados idénticos de seis caras. En una cara de cada dado hay una imagen de una calavera; las otras cinco caras están todas en blanco. Si procedo a tirar los 20 dados, ¿cuál es la probabilidad de que obtenga exactamente 4 cráneos? Asumiendo que los dados son justos, sabemos que la probabilidad de que alguien muera subiendo cráneos es de 1 en 6; para decirlo de otra manera, la probabilidad de calavera para un solo dado es aproximadamente .167. Esta es información suficiente para responder a nuestra pregunta, así que echemos un vistazo a cómo se hace.
Como es habitual, vamos a querer introducir algunos nombres y alguna notación. Dejaremos que N denote el número de tiradas de dados en nuestro experimento; que a menudo se conoce como el parámetro de tamaño de nuestra distribución binomial. También usaremos θ para referirnos a la probabilidad de que un solo dado surja cráneos, una cantidad que generalmente se llama la probabilidad de éxito del binomio. 143 Por último, usaremos X para referirnos a los resultados de nuestro experimento, es decir, el número de cráneos que obtengo cuando ruedo los dados. Dado que el valor real de X se debe al azar, nos referimos a él como una variable aleatoria. En cualquier caso, ahora que tenemos toda esta terminología y notación, podemos utilizarla para exponer el problema un poco más precisamente. La cantidad que queremos calcular es la probabilidad de que X=4 dado que sabemos que θ=.167 y N=20. La “forma” general de la cosa que me interesa calcular podría escribirse como
P (X | θ, N)
y nos interesa el caso especial donde X=4, θ=.167 y N=20. Sólo hay una pieza más de notación a la que quiero referirme antes de pasar a discutir la solución al problema. Si quiero decir que X se genera aleatoriamente a partir de una distribución binomial con los parámetros θ y N, la notación que usaría es la siguiente:
X~Binomial (θ, N)
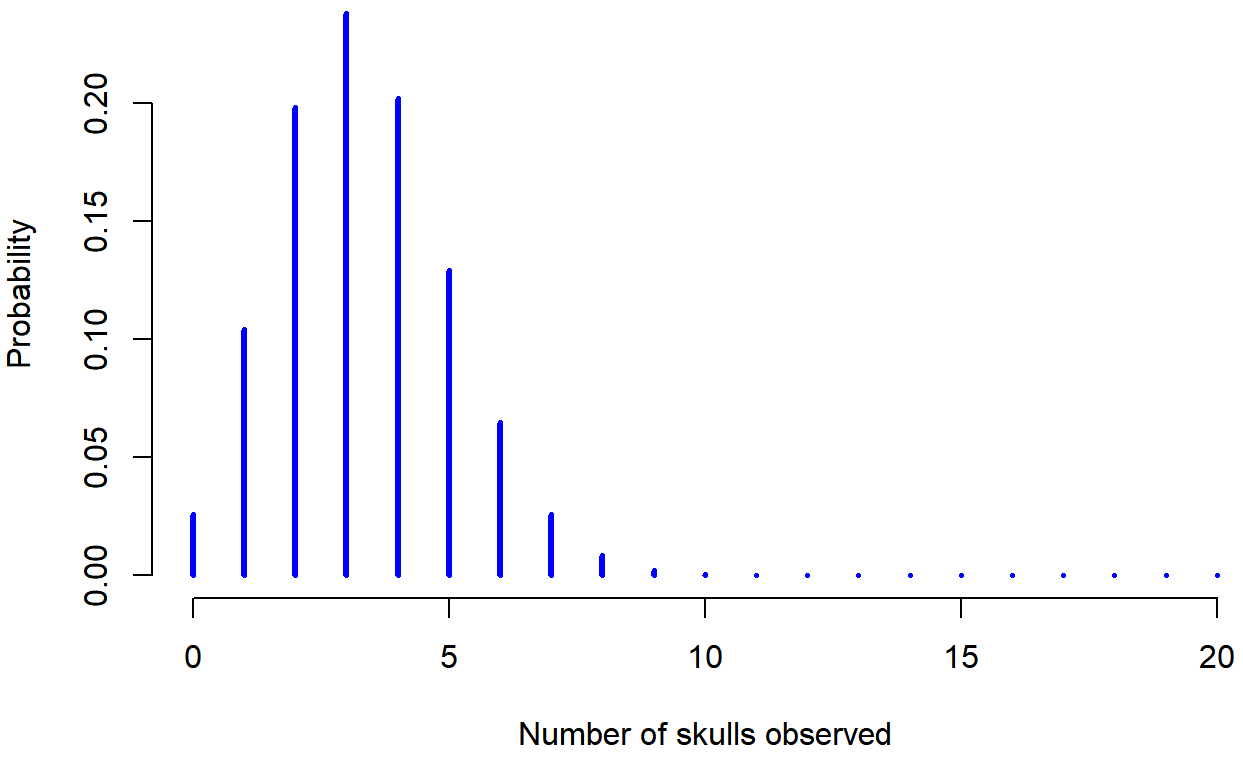
Sí, sí. Sé lo que estás pensando: notación, notación, notación. En serio, ¿a quién le importa? Muy pocos lectores de este libro están aquí por la notación, así que probablemente debería seguir adelante y hablar sobre cómo usar la distribución binomial. He incluido la fórmula para la distribución binomial en la Tabla 9.2, ya que algunos lectores pueden querer jugar con ella ellos mismos, pero como a la mayoría de la gente probablemente no le importa tanto y porque no necesitamos la fórmula en este libro, no voy a hablar de ello con ningún detalle. En cambio, solo quiero mostrarte cómo es la distribución binomial. Para ello, la Figura 9.3 traza las probabilidades binomiales para todos los valores posibles de X para nuestro experimento de lanzamiento de dados, desde X=0 (sin cráneos) hasta X=20 (todos los cráneos). Tenga en cuenta que esto es básicamente un gráfico de barras, y no es diferente a la gráfica de “probabilidad de pantalones” que dibujé en la Figura 9.2. En el eje horizontal tenemos todos los eventos posibles, y en el eje vertical podemos leer la probabilidad de cada uno de esos eventos. Entonces, la probabilidad de rodar 4 cráneos de 20 veces es de aproximadamente 0.20 (la respuesta real es 0.2022036, como veremos en un momento). En otras palabras, esperarías que eso suceda alrededor del 20% de las veces que repitiste este experimento.
Trabajando con la distribución binomial en R
Aunque a algunas personas les resulta útil conocer las fórmulas en la Tabla 9.2, la mayoría de la gente solo quiere saber cómo usar las distribuciones sin preocuparse demasiado por las matemáticas. Para ello, R tiene una función llamada dbinom () que calcula probabilidades binomiales para nosotros. Los principales argumentos a la función son
x. Este es un número, o vector de números, especificando los resultados cuya probabilidad estás tratando de calcular.tamaño. Este es un número que le dice a R el tamaño del experimento.prob. Esta es la probabilidad de éxito para cualquier ensayo en el experimento.
Entonces, para calcular la probabilidad de obtener x = 4 cráneos, a partir de un experimento de tamaño = 20 ensayos, en el que la probabilidad de obtener un cráneo en cualquier ensayo es prob = 1/6... bueno, el comando que usaría es simplemente este:
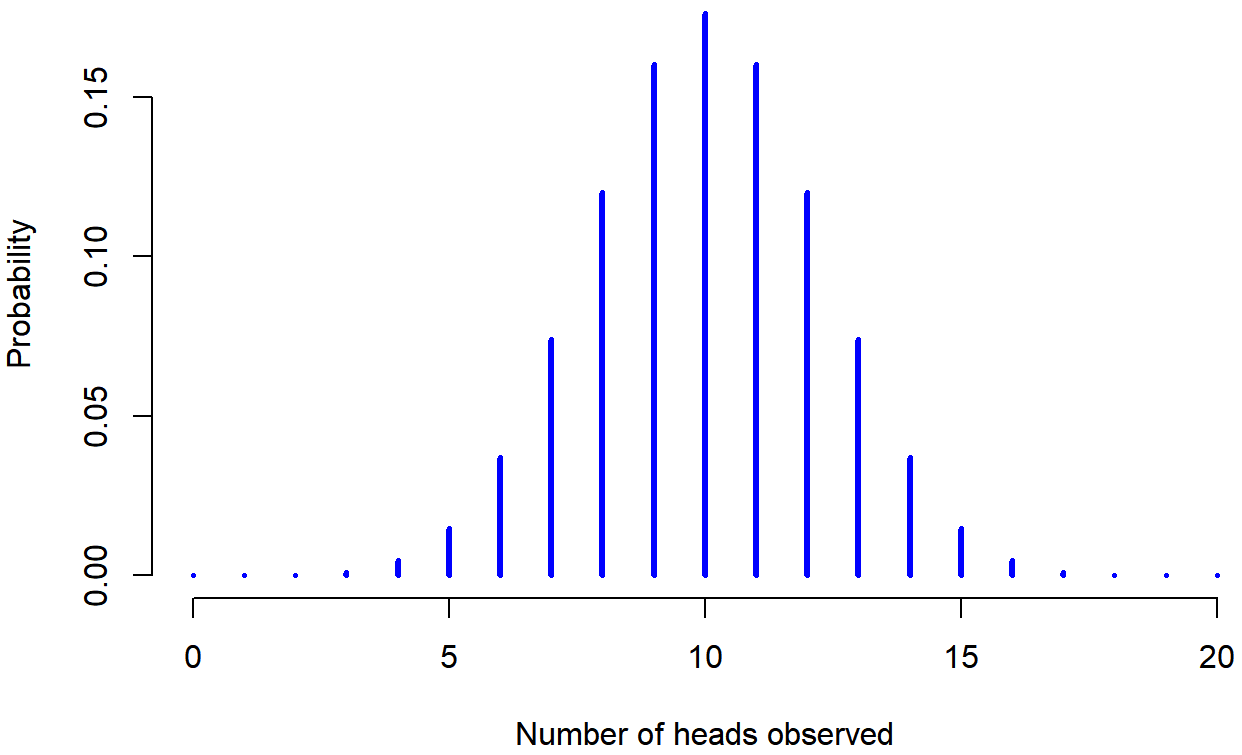
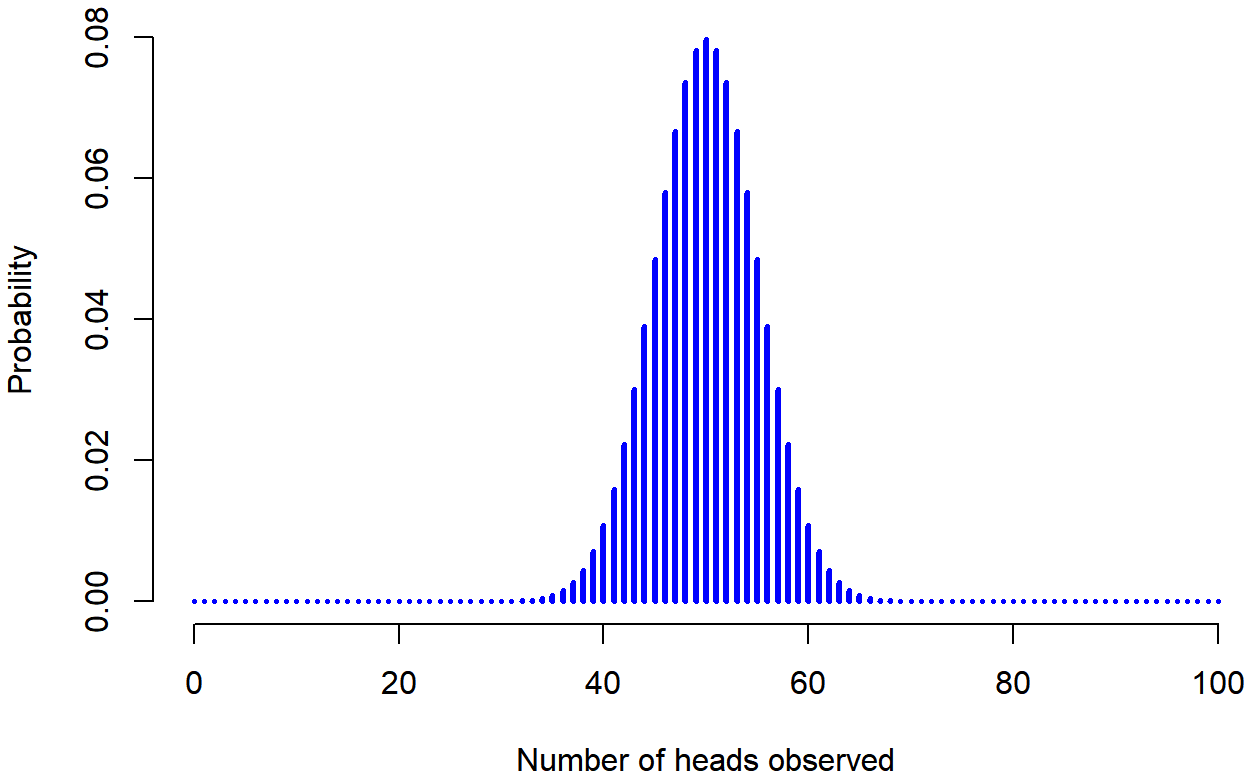
dbinom( x = 4, size = 20, prob = 1/6 )## [1] 0.2022036Para darle una idea de cómo cambia la distribución binomial cuando alteramos los valores de θ y N, supongamos que en lugar de tirar dados, en realidad estoy volteando monedas. En esta ocasión, mi experimento consiste en voltear una moneda justa repetidamente, y el resultado que me interesa es el número de cabezas que observo. En este escenario, la probabilidad de éxito es ahora θ=1/2. Supongamos que iba a voltear la moneda N=20 veces. En este ejemplo, he cambiado la probabilidad de éxito, pero mantuve igual el tamaño del experimento. ¿Qué le hace esto a nuestra distribución binomial? Bueno, como muestra la Figura 9.4, el efecto principal de esto es desplazar toda la distribución, como cabría esperar. Bien, ¿y si volteamos una moneda N=100 veces? Bueno, en ese caso, obtenemos la Figura 9.5. La distribución se mantiene aproximadamente en el medio, pero hay un poco más de variabilidad en los posibles resultados.
knitr::kable(data.frame(stringsAsFactors=FALSE, Binomial = c("$P(X | \\theta, N) = \\displaystyle\\dfrac{N!}{X! (N-X)!}
\\theta^X (1-\\theta)^{N-X}$"),
Normal = c("$p(X | \\mu, \\sigma) = \\displaystyle\\dfrac{1}{\\sqrt{2\\pi}\\sigma} \\exp \\left( -\\dfrac{(X - \\mu)^2}
{2\\sigma^2} \\right)$ ")), caption = "Formulas for the binomial and normal distributions. We don't really use these
formulas for anything in this book, but they're pretty important for more advanced work, so I thought it might be best
to put them here in a table, where they can't get in the way of the text. In the equation for the binomial, $X!$ is the
factorial function (i.e., multiply all whole numbers from 1 to $X$), and for the normal distribution \"exp\" refers to
the exponential function, which we discussed in the Chapter on Data Handling. If these equations don't make a lot of
sense to you, don't worry too much about them.")Cuadro 9.2: Fórmulas para las distribuciones binomiales y normales. Realmente no usamos estas fórmulas para nada en este libro, pero son bastante importantes para un trabajo más avanzado, así que pensé que sería mejor ponerlas aquí en una mesa, donde no puedan interponerse en el camino del texto. En la ecuación para el binomio, ¡X! es la función factorial (es decir, multiplicar todos los números enteros del 1 al X), y para la distribución normal “exp” se refiere a la función exponencial, que discutimos en el Capítulo sobre Manejo de Datos. Si estas ecuaciones no tienen mucho sentido para ti, no te preocupes demasiado por ellas.
| Binomial | Normal |
|---|---|
| $$ P (X |\ theta, N) =\ dfrac {N!} {X! (N-X)!} \ theta^ {X} (1-\ theta) ^ {N-X} \ nonumber$$ |
$$ p (X |\ mu,\ sigma) =\ dfrac {1} {\ sqrt {2\ pi}\ sigma}\ exp\ izquierda (-\ dfrac {(X-\ mu) ^ {2}} {2\ sigma^ {2}}\ derecha) \ nonúmera$$ |
Cuadro 9.3: El sistema de nomenclatura para las funciones de distribución de probabilidad R. Cada distribución de probabilidad implementada en R está realmente asociada con cuatro funciones separadas, y hay una forma bastante estandarizada de nombrar estas funciones.
| ¿Qué hace? | Prefijo | Normal.distribución | Binomial.Distribución |
|---|---|---|---|
| probabilidad (densidad) de | d | dnorm () | dbinom () |
| probabilidad acumulativa de | p | dnorm () | pbinom () |
| generar número aleatorio a partir de | r | rnorm () | rbinom () |
| q qnorm () qbinom () | q | qnorm () | qbinom ( |
En este punto, probablemente debería explicar el nombre de la función dbinom (). Obviamente, la parte “binom” viene del hecho de que estamos trabajando con la distribución binomial, pero el prefijo “d” probablemente sea un poco misterioso. En esta sección voy a dar una explicación parcial: específicamente, voy a explicar por qué hay un prefijo. En cuanto a por qué es una “d” específicamente, tendrás que esperar hasta la siguiente sección. Lo que está pasando aquí es que R en realidad proporciona cuatro funciones en relación con la distribución binomial. Estas cuatro funciones son dbinom (), pbinom (), rbinom () y qbinom (), y cada una calcula una cantidad diferente de interés. No sólo eso, R hace lo mismo por cada distribución de probabilidad que implemente. No importa de qué distribución estés hablando, hay una función d, una función p, una función q y una función r. Esto se ilustra en el Cuadro 9.3, utilizando como ejemplos la distribución binomial y la distribución normal.
Echemos un vistazo a lo que hacen las cuatro funciones. En primer lugar, las cuatro versiones de la función requieren que especifiques los argumentos size y prob: no importa lo que estés tratando de obtener R para calcular, necesita saber cuáles son los parámetros. No obstante, difieren en cuanto a lo que es el otro argumento, y cuál es la salida. Entonces vamos a verlos uno a la vez.
- La forma
dque ya hemos visto: se especifica un resultado en particularx, y la salida es la probabilidad de obtener exactamente ese resultado. (la “d” es la abreviatura de densidad, pero ignora eso por ahora). - La forma
pcalcula la probabilidad acumulada. Se especifica un cuantil particularq, y éste le indica la probabilidad de obtener un resultado menor o igual aq. - La forma
qcalcula los cuantiles de la distribución. Usted especifica un valor de probabilidadp, y le da el percentil correspondiente. Es decir, el valor de la variable para la que existe una probabilidadpde obtener un resultado menor que ese valor. - La forma
res un generador de números aleatorios: específicamente, generanresultados aleatorios a partir de la distribución.
Esto es un poco abstracto, así que veamos algunos ejemplos concretos. Nuevamente, ya hemos cubierto dbinom () así que centrémonos en las otras tres versiones. Empezaremos con pbinom (), y volveremos al ejemplo cráneo-dado. Nuevamente, estoy rodando 20 dados, y cada dado tiene una probabilidad de 1 en 6 de subir cráneos. Supongamos, sin embargo, que quiero saber la probabilidad de rodar 4 o menos cráneos. Si quisiera, podría usar la función dbinom () para calcular la probabilidad exacta de rodar 0 cráneos, 1 calavera, 2 cráneos, 3 cráneos y 4 cráneos y luego sumar estos, pero hay una manera más rápida. En cambio, puedo calcular esto usando la función pbinom (). Aquí está el comando:
pbinom( q= 4, size = 20, prob = 1/6)## [1] 0.7687492Es decir, hay un 76.9% de posibilidades de que ruede 4 o menos cráneos. O, para decirlo de otra manera, R nos está diciendo que un valor de 4 es en realidad el percentil 76.9 de esta distribución binomial.
A continuación, consideremos la función qbinom (). Digamos que quiero calcular el percentil 75 de la distribución binomial. Si nos quedamos con nuestro ejemplo de cráneos, usaría el siguiente comando para hacer esto:
qbinom( p = 0.75, size = 20, prob = 1/6)## [1] 4Hm. Aquí está pasando algo extraño. Pensemos esto bien. Lo que la función qbinom () parece estar diciéndonos es que el percentil 75 de la distribución binomial es 4, aunque vimos a partir de la función pbinom () que 4 es en realidad el percentil 76.9º. Y definitivamente es la función pbinom () la que es correcta. Lo prometo. La rareza aquí viene del hecho de que nuestra distribución binomial realmente no tiene un percentil 75. En realidad no. ¿Por qué no? Bueno, hay un 56.7% de probabilidad de rodar 3 o menos cráneos (puedes escribir pbinom (3, 20, 1/6) para confirmar esto si quieres), y un 76.9% de probabilidad de rodar 4 o menos cráneos. Entonces hay un sentido en el que el percentil 75 debería estar “entre” 3 y 4 cráneos. ¡Pero eso no tiene ningún sentido! No se puede tirar 20 dados y obtener 3.9 de ellos subir cráneos. Este problema se puede manejar de diferentes maneras: podrías reportar un valor intermedio (o valor interpolado, para usar el nombre técnico) como 3.9, podrías redondear hacia abajo (a 3) o podrías redondear hacia arriba (a 4). La función qbinom () redondea hacia arriba: si pides un percentil que en realidad no existe (como el 75 en este ejemplo), R encuentra el valor más pequeño para el que el rango del percentil es al menos lo que pediste. En este caso, dado que el “verdadero” percentil 75 (lo que sea que eso signifique) se encuentra en algún lugar entre 3 y 4 cráneos, R redondea y te da una respuesta de 4. Esta sutileza es tediosa, lo admito, pero por suerte solo es un problema para distribuciones discretas como el binomio (ver Sección 2.2.5 para una discusión de continuo versus discreto). Las otras distribuciones de las que voy a hablar (normal, t, χ 2 y F) son todas continuas, y así R siempre puede devolver un cuantil exacto cada vez que lo pidas.
Por último, tenemos el generador de números aleatorios. Para usar la función rbinom (), se especifica cuántas veces R debe “simular” el experimento usando el argumento n, y generará resultados aleatorios a partir de la distribución binomial. Entonces, por ejemplo, supongamos que iba a repetir mi experimento de laminación de troqueles 100 veces. Podría obtener R para simular los resultados de estos experimentos usando el siguiente comando:
rbinom( n = 100, size = 20, prob = 1/6 )## [1] 3 3 3 2 3 3 3 2 3 3 6 2 5 3 1 1 4 7 5 3 3 6 3 4 3 4 5 3 3 3 7 4 5 1 2
## [36] 1 2 4 2 5 5 4 4 3 1 3 0 2 3 2 2 2 2 1 3 4 5 0 3 2 5 1 2 3 1 5 2 4 3 2
## [71] 1 2 1 5 2 3 3 2 3 3 4 2 1 2 6 2 3 2 3 3 6 2 1 1 3 3 1 5 4 3Como puede ver, estos números son más o menos lo que esperaría dada la distribución que se muestra en la Figura 9.3. La mayoría de las veces ruedo en algún lugar entre 1 y 5 cráneos. Hay muchas sutilezas asociadas a la generación de números aleatorios usando una computadora, 144 pero para los fines de este libro no necesitamos preocuparnos demasiado por ellas.