
3.1: Caracterización de datos
- Page ID
- 150181

¿Qué significa caracterizar tus datos? Primero, significa saber cuántas observaciones están contenidas en tus datos y la distribución de esas observaciones en el rango de tu (s) variable (s). ¿Qué tipo de medidas (intervalo, ordinal, nominal) tiene y cuáles son los rangos de medidas válidas para cada variable? ¿Cuántos casos de faltantes (sin datos) o mal codificados (medidas que caen fuera del rango válido) tiene? ¿Qué representan los valores codificados? Si bien parece trivial, verificar y evaluar sus datos para estos atributos puede ahorrarle mayores dolores de cabeza más adelante. Por ejemplo, los valores que faltan para una observación suelen obtener un código especial —digamos, “-99 ”— para distinguirlos de las observaciones válidas. Si descuidas tratar estos valores adecuadamente, R (o cualquier otro programa de estadísticas) tratará ese valor como si fuera válido y con ello convertirá tus resultados en una bola de pelo real. Conocemos casos en los que incluso estudiosos cuantitativos experimentados han cometido el vergonzoso error de no manejar adecuadamente los valores faltantes en sus análisis. En al menos un caso, un artículo publicado tuvo que ser retraído por esta razón. ¡Así que no escatimes en las formas más básicas de caracterización de datos!
El conjunto de datos utilizado con fines ilustrativos en esta versión de este texto está tomado de una encuesta a habitantes de Oklahoma, realizada en 2016, por el Centro de Gestión de Riesgos y Crisis de OU. La redacción de la pregunta de la encuesta y los antecedentes se proporcionarán en clase. Sin embargo, para efectos de este capítulo, señalar que la medida de ideología consiste en un autoreporte de ideología política en una escala que va desde 1 (fuerte liberal) hasta 7 (fuerte conservador); la medida del riesgo percibido de cambio climático va de cero (sin riesgo) a 10 ( riesgo extremo). La edad se midió en años.
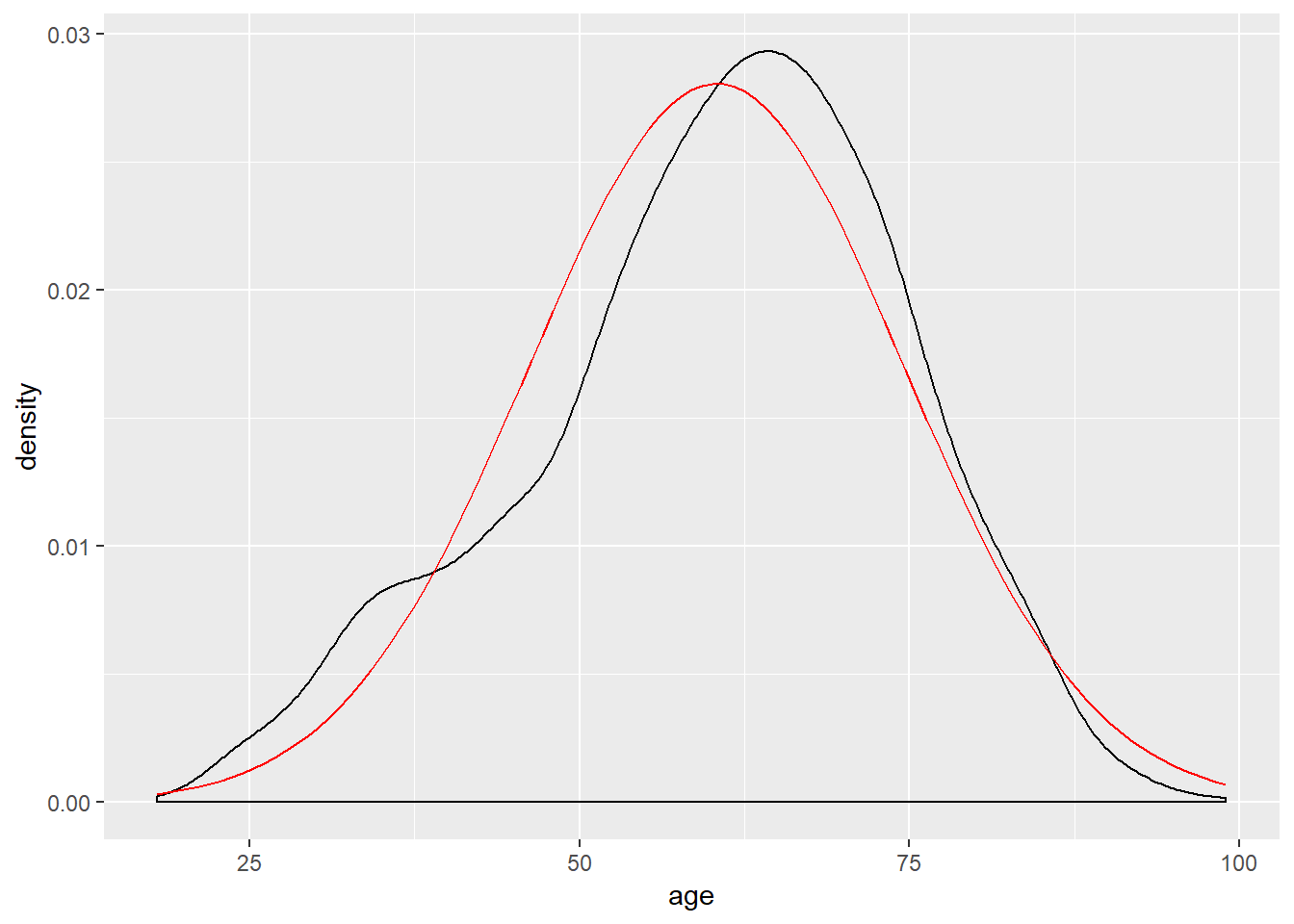
A menudo es útil graficar las variables en tu conjunto de datos para tener una mejor idea de su distribución. Además, es posible que queramos comparar la distribución de una variable con una distribución teórica (típicamente una distribución normal). Esto se puede lograr de varias maneras, pero aquí mostraremos dos: un histograma y una curva de densidad, y se discutirán más en capítulos posteriores. Por ahora, examinamos la distribución de la variable que mide la edad. La línea roja en la visualización de densidad presenta la distribución normal dada la media y desviación estándar de nuestra variable.
Un histograma crea intervalos de igual longitud, llamados bins, y muestra la frecuencia de observaciones en cada uno de los bins. Para producir un histograma en R simplemente use el comando geom_histogram en el paquete ggplot2. A continuación, se grafica la densidad de los datos observados junto con una curva normal. Esto se puede hacer con el comando geom_density en el paquete ggplot2.
library(ggplot2)
ggplot(ds, aes(age)) +
geom_histogram() 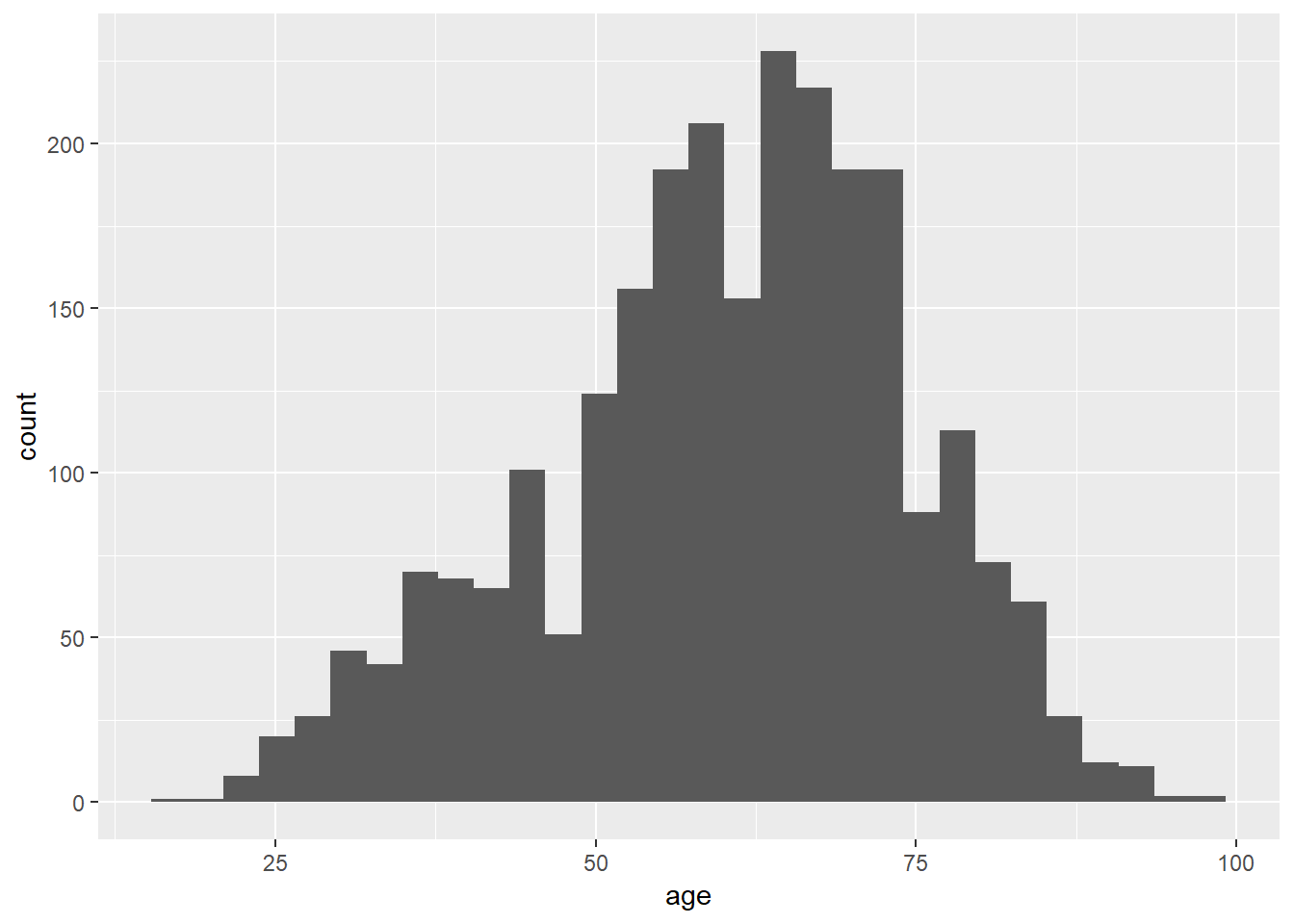
ggplot(ds, aes(age)) +
geom_density() +
stat_function(fun = dnorm, args = list(mean = mean(ds$age, na.rm = T),
sd = sd(ds$age, na.rm = T)), color = "red")
También puede obtener una visión general de sus datos utilizando una tabla conocida como distribución de frecuencias. La distribución de frecuencia resume la frecuencia con la que cada valor de su variable ocurre en el conjunto de datos. Si tu variable tiene un número limitado de valores que puede tomar, puedes reportar todos los valores, pero si tiene un gran número de valores posibles (por ejemplo, edad del encuestado), entonces querrás crear categorías, o bins, para reportar esas frecuencias. En tales casos, generalmente es más fácil darle sentido a la distribución porcentual. El Cuadro 3.3 es una distribución de frecuencias para la variable ideológica. De esa tabla vemos, por ejemplo, que alrededor de un tercio de todos los encuestados son moderados. Vemos que los números disminuyen a medida que nos alejamos de esa categoría, pero no de manera uniforme. Hay algunas personas más en el extremo conservador que en el lado liberal y que el número de personas que se colocan en las penúltimas categorías en cada extremo es mayor que las que están hacia el medio. El histograma y la curva de densidad, por supuesto, mostrarían el mismo patrón.
La otra cosa a tener en cuenta aquí (o en los gráficos) es si hay una observación inusual. Si una persona anotó 17 en esta tabla, podrías estar bastante seguro de que se cometió un error de codificación en alguna parte. No puedes encontrar todos tus errores de esta manera, pero puedes encontrar algunos, incluidos los que tienen el potencial de afectar negativamente más seriamente tu análisis.
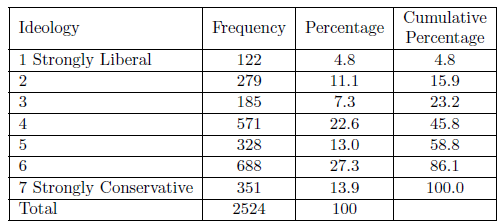
Figura\(\PageIndex{3}\): Distribución de frecuencias para ideología
En R, podemos obtener los datos para la tabla anterior con las siguientes funciones:
# frequency counts for each level
table(ds$ideol)##
## 1 2 3 4 5 6 7
## 122 279 185 571 328 688 351# To view percentages
library(dplyr)
table(ds$ideol) %>% prop.table()##
## 1 2 3 4 5 6
## 0.04833597 0.11053883 0.07329635 0.22622821 0.12995246 0.27258320
## 7
## 0.13906498# multiply the numbers by 100
table(ds$ideol) %>% prop.table() * 100 ##
## 1 2 3 4 5 6 7
## 4.833597 11.053883 7.329635 22.622821 12.995246 27.258320 13.906498Habiendo obtenido una muestra, es importante poder caracterizar esa muestra. En particular, es importante entender las distribuciones de probabilidad asociadas a cada variable en la muestra.
3.1.1 Tendencia Central
Las medidas de tendencia central son útiles porque se puede usar un solo estadístico para describir la distribución. Nos enfocamos en tres medidas de tendencia central: la media, la mediana y el modo.
Medidas de Tendencia Central
La Media: El promedio aritmético de los valores
La mediana: El valor en el centro de la distribución
El modo: El valor que ocurre con más frecuencia
Nos basaremos principalmente en la media, por su propiedad eficiente de representar los datos. Pero las medianas —particularmente cuando se usan junto con la media— pueden decirnos mucho sobre la forma de la distribución de nuestros datos. Volveremos a este punto en breve.
3.1.2 Nivel de Medición y Tendencia Central
Cada una de las tres medidas de tendencia central —la media, la mediana y el modo— nos dice algo diferente sobre nuestros datos, pero cada una tiene algunas limitaciones también (especialmente cuando se usa sola). Conocer el modo nos dice qué es lo más común, pero no sabemos qué tan común y, usándolo solo, ni siquiera nos dejaría seguros de que es un indicador de algo muy central. Al rodar en sus datos, generalmente es una buena idea rodar en todas las estadísticas descriptivas que pueda para tener una buena idea de ellos.
Sin embargo, un problema es que su capacidad para usar cualquier estadística depende del nivel de medición de la variable. La media requiere que sumes todas tus observaciones juntas. Pero no se pueden realizar funciones matemáticas en medidas de nivel ordinal o nominal. Tus datos deben medirse a nivel de intervalo para calcular una media significativa. (Si le pides a R que calcule el número medio de identificación de estudiante, lo hará, pero lo que obtengas será una tontería). Encontrar el ítem medio en un listado ordenado de tus observaciones (la mediana) requiere la capacidad de ordenar tus datos, por lo que tu nivel de medición debe ser al menos ordinal. Por lo tanto, si tienes datos de nivel nominal, solo puedes reportar el modo (pero sin mediana o media), por lo que es fundamental que también mires más allá de la tendencia central a la distribución general de los datos.
3.1.3 Momentos
Además de las medidas de tendencia central, los “momentos” son formas importantes de caracterizar la forma de la distribución de una variable muestral. Los momentos son aplicables cuando los datos medidos son de tipo intervalo (el nivel de medición). Los primeros cuatro momentos son los que se utilizan con mayor frecuencia.
- Valor esperado: El valor esperado de una variable, E (X) es su media.
E (X) =¯X=Xin