
Apéndice E - El glosario corto de R
- Page ID
- 150054

Este glosario muy corto ayudará a encontrar el comando R correspondiente para los términos estadísticos más extendidos. Esto es similar al “índice inverso” que podría ser útil cuando sabes qué hacer pero no sabes qué comando R usar.
Criterio de información de Akaike, AIC — AIC () — criterio de la optimalidad del modelo; el mejor modelo suele corresponder con AIC mínimo.
análisis de varianza, ANOVA — aov () — la familia de pruebas paramétricas, utilizadas para comparar múltiples muestras.
análisis de covarianza, ANCOVA — lm (respuesta ~ influencia*factor) — sólo otra variante de modelos lineales, compara varias líneas de regresión.
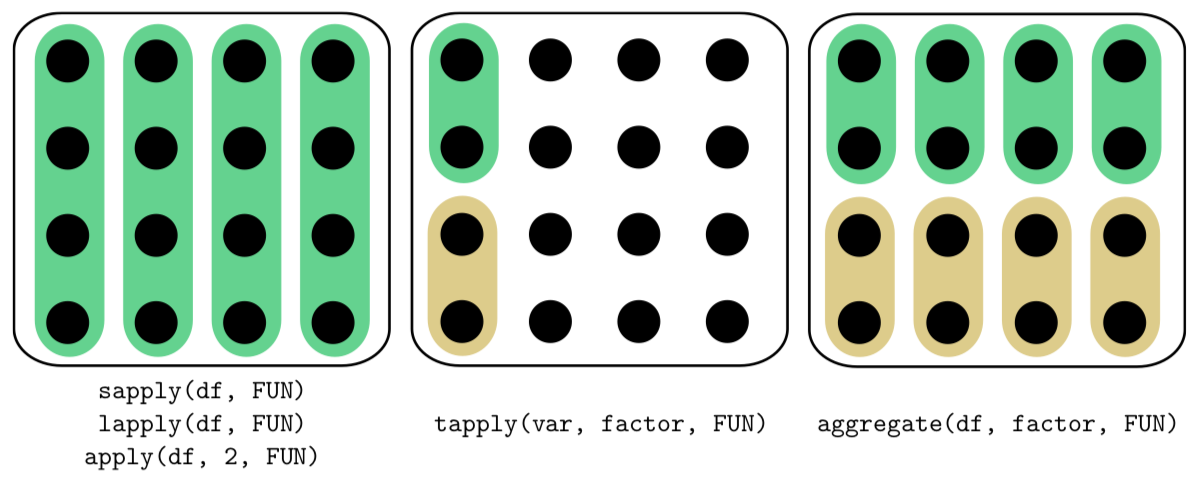
“apply family” — aggregate (), apply (), lapply (), sapply (), tapply () y otros — Funciones R que ayudan a evitar bucles, repeticiones de la misma secuencia de comandos. Las diferencias entre las funciones más utilizadas de esta familia (aplicadas en el marco de datos) se muestran en la Figura\(\PageIndex{1}\).
media aritmética, media, promedio — media () — suma de todos los valores de muestra se divide en su número.
gráfico de barras — barplot () — el diagrama para representar varios valores numéricos (por ejemplo, recuentos).
Prueba de Bartlett — bartlett.test () — comprueba el nulo si las varianzas de las muestras son iguales (supuesto ANOVA).
bootstrap — sample () y muchos otros — técnica de submuestreo muestral para estimar estadísticas de población.
boxplot — boxplot () — el diagrama para representar las características principales de una o varias muestras.
Prueba de chi-cuadrado — chisq.test () — ayuda a verificar si hay una asociación entre filas y columnas en la tabla de contingencia.
análisis de conglomerados, jerárquico — hclust () — visualización de las diferencias de objetos como dendrograma (árbol).
intervalo de confianza — el rango donde se puede ubicar algún valor poblacional (media, mediana, etc.) con una probabilidad dada.
análisis de correlación — cor.test () — grupo de métodos que permiten describir la determinación entre varias muestras.
matriz de correlación — cor () — devuelve coeficientes de correlación para todos los pares de muestras.
tipos de datos — hay una lista (con sinónimos):
- medición:
- continuo;
- merístico, discreto, discontinuo;
- clasificado, ordinal;
- categórico, nominal.
matriz de distancia — dist (), daisy (), vegdist () — calcula la distancia (disimilitud) entre objetos.
distribución — el “layout”, la “forma” de los datos; la distribución teórica muestra cómo deben verse los datos mientras que la distribución muestra cómo se ven los datos en la realidad.
F-test — var.test () — prueba paramétrica utilizada para comparar variaciones en dos muestras.
Prueba exacta de Fisher — fisher.test () — similar a chi-cuadrado pero calcula (no estima) valor p; recomendado para datos pequeños.
modelos lineales generalizados — glm () — extensión de modelos lineales permitiendo (por ejemplo) la respuesta binaria; esta última es la regresión logística.
histograma — hist () — diagrama para mostrar frecuencias de diferentes valores en la muestra.
rango intercuartil — IQR () — la distancia entre el segundo y cuarto cuartil, el método robusto para mostrar variabilidad.
Prueba de Kolmogorov-Smirnov — ks.test () — utilizada para comparar dos distribuciones, incluyendo la comparación entre distribución muestral y distribución normal.
Prueba de Kruskal-Wallis — kruskal.test () — utilizada para comparar múltiples muestras, esto es reemplazo no paramétrico de ANOVA.
análisis discriminante lineal — lda () — método multivariado, permite crear una clasificación basada en la muestra de entrenamiento.
regresión lineal — lm () — investiga la relación lineal (regresión lineal) entre objetos.
long form — stack (); unstack () — la variante de representación de datos donde los ID de grupo (entidad) y los datos son verticales, en columnas:
SEXO TALLA
M 1 M 1
F 2
F 1
LOESS — loess.smooth () — Suavizado de gráfica de dispersión ponderada localmente.
Prueba de McNemar — mcnemar.test () — similar a chi-cuadrado pero permite verificar la asociación en caso de observaciones pareadas.
Prueba de Mann-Whitney — wilcox.test () — ver la prueba de Wilcoxon.
mediana — mediana () — el valor dividiendo la muestra en dos mitades.
fórmulas modelo — formula () — la manera de describir brevemente el modelo estadístico:
- respuesta ~ influencia: análisis de la regresión;
- respuesta ~ influencia1 + influencia2: análisis de regresión múltiple, modelo aditivo;
- factor de respuesta ~: ANOVA de un factor;
- respuesta ~ factor1 + factor2: ANOVA multifactor;
- respuesta ~ influencia * factor: análisis de covariación, modelo con interacciones, se expande en “respuesta ~ influencia + influencia: factor”.
Operadores utilizados en fórmulas:
- todos los predictores (influencias y factores) del modelo anterior (utilizados junto con update ());
- añade factor o influencia;
- elimina factor o influencia;
- interacción;
- todas las combinaciones lógicas de factores e influencias;
- inclusión, “factor1/factor2” significa que factor2 está incrustado en factor1 (como calle está “incrustado” en distrito y distrito en ciudad);
- condición, “factor1 | factor2” significa “factor de división 1 por los niveles de factor2”;
- interceptar, entonces respuesta ~ influencia - 1 significa modelo lineal sin intercepción;
- devuelve valores aritméticos para todo entre paréntesis. También se utiliza en el comando data.frame () para omitir la conversión en factor para columnas de caracteres.
escalado multidimensional, MDS — cmdscale () — construye algo así como un mapa a partir de la matriz de distancia.
comparaciones múltiples — p.ajustar () — consulte el cómic XKCD para obtener la mejor explicación (Figura\(\PageIndex{2}\)).
no paramétrico — no relacionado con una distribución teórica específica, útil para el análisis de datos arbitrarios.
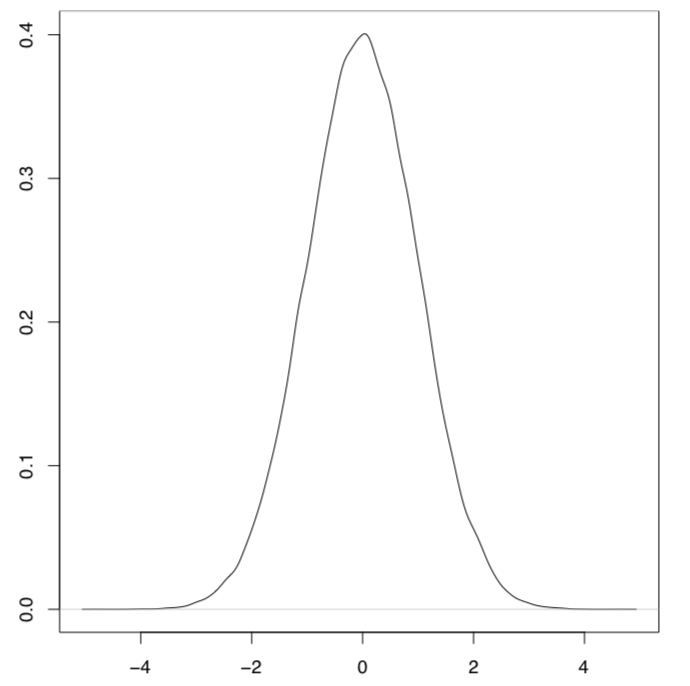
parcela de distribución normal — parcela (densidad (rnorm (1000000))) — “campana”, “sombrero” (Figura\(\PageIndex{3}\)).
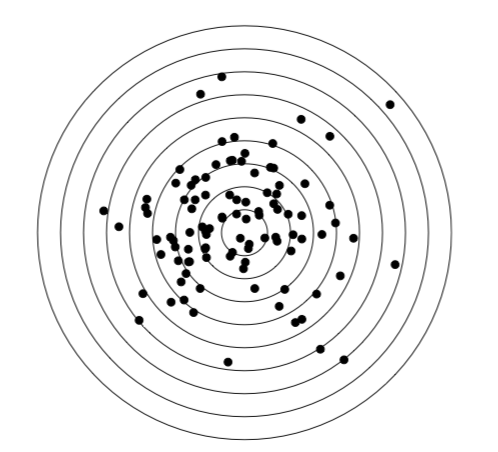
distribución normal — rnorm () — la distribución teórica más importante, el basamento de los métodos paramétricos; aparece, por ejemplo si uno disparará al objetivo durante mucho tiempo y luego medirá todas las distancias al centro (Figura\(\PageIndex{4}\)):

Código\(\PageIndex{1}\) (R):
prueba unidireccional — oneway.test () — similar al ANOVA simple pero omite la homogeneidad de la suposición de varianzas.
prueba t por pares — par.t.test () — prueba paramétrica post hoc con ajuste para comparaciones múltiples.
prueba de Wilcoxon por pares — par.wilcox.test () — prueba post hoc no paramétrica con ajuste para comparaciones múltiples.
paramétrico — correspondiente a la distribución conocida (en este libro: normal, ver), adecuada para el análisis de los datos normalmente distribuidos.
post hoc — pruebas que verifican todos los grupos por pares; contrario al nombre, no es necesario ejecutarlos después de otra cosa.
análisis de componentes principales — princomp (), prcomp () — método multivariado “proyectado” nube multivariante sobre el plano de componentes principales.
prueba de proporción — prop.test () — comprueba si las proporciones son iguales.
p-value — probabilidad de obtener el valor estimado si la hipótesis nula es verdadera; si el valor p está por debajo del umbral, entonces la hipótesis nula debe ser rechazada (consulte el capítulo “datos bidimensionales” para la explicación sobre las hipótesis estadísticas).
robustos: no son tan sensibles a los valores atípicos, muchos métodos robustos también son no paramétricos.
quantile — quantile () — devuelve valores de cuantiles (por defecto, valores que cortan 0, 25, 50, 75 y 100% de la muestra).
scatterplot — plot (x, y) — plot que muestra la correspondencia entre dos variables.
Prueba de Shapiro-Wilk — shapiro.test () — prueba para verificar la normalidad de la muestra.
forma corta — stack (); unstack () — la variante de representación de datos donde los ID de grupo son horizontales (son columnas):
M.TALLA F.TALLA
1 2
1 1
desviación estándar — sd () — raíz cuadrada de la varianza.
error estándar, SE — sd (x) /sqrt (longitud (x)) — varianza normalizada.
Gráfica tallo y hoja — tallo () — gráfica textual que muestra frecuencias de valores en la muestra, alternativa para histograma.
t-test — t.test () — la familia de pruebas paramétricas que se utilizan para estimar y/o comparar valores medios de una o dos muestras.
Tukey HSD — TukeyHSD () — prueba paramétrica post hoc para comparaciones múltiples que calcula las diferencias significativas honestas de Tukey (intervalos de confianza).
La relación lineal de Tukey — línea () — se ajusta robustamente, con medianas de subgrupos.
distribución uniforme — runif () — distribución donde cada valor tiene la misma probabilidad.
varianza — var () — la diferencia promediada entre la media y todos los demás valores de la muestra.
Prueba de Wilcoxon — wilcox.test () — utilizada para estimar y/o comparar medianas de una o dos muestras, este es el reemplazo no paramétrico de la prueba t.