
2.7: Detalle - El Código Genético*
- Page ID
- 82291
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)El componente básico de tu cuerpo es una célula. Dos o más grupos de células forman tejidos, como el hueso o el músculo; los tejidos se organizan para formar órganos, como el corazón o el cerebro; los órganos forman sistemas de órganos, como el sistema circulatorio o el sistema nervioso; los sistemas de órganos juntos te forman, el organismo. Las células pueden clasificarse como células eucariotas o procariotas, con o sin núcleo, respectivamente. Las células que componen tu cuerpo y las de todos los animales, plantas y hongos son eucariotas. Los procariotas son bacterias y cianobacterias.
El núcleo forma un compartimento separado del resto del cuerpo celular; este compartimento sirve como centro de almacenamiento central para toda la información hereditaria de las células eucariotas. Toda la información genética que forma el libro de la vida se almacena en cromosomas individuales que se encuentran dentro del núcleo. En humanos sanos hay 23 pares de cromosomas (46 en total). Cada uno de los cromosomas contiene una molécula de ácido desoxirribonucleico (ADN) filiforme. Los genes son las regiones funcionales a lo largo de estas cadenas de ADN, y son las unidades físicas fundamentales que transportan información hereditaria de una generación a la siguiente. En los procariotas los cromosomas flotan libremente en el cuerpo celular ya que no hay núcleo.
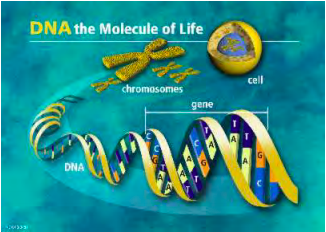
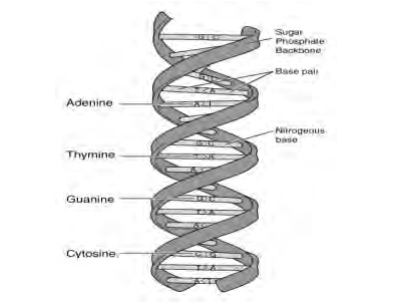
Las moléculas de ADN están compuestas por dos cadenas interconectadas de nucleótidos que forman una cadena de ADN. Cada nucleótido está compuesto por un azúcar, fosfato y una de cuatro bases. Las bases son adenina, guanina, citosina y timina. Por conveniencia cada nucleótido es referenciado por su base; en lugar de decir monofosfato de desoxiguanosina simplemente diríamos guanina (o G) cuando nos referimos al nucleótido individual. Así podríamos escribir CCACCA para indicar una cadena de nucleótidos interconectados citosina-citosina-adenina-citosina-citosina-citosinaadenina.
Las cadenas de nucleótidos individuales están interconectadas a través del emparejamiento de sus bases nucleotídicas en una sola estructura de doble hélice. Las reglas para el emparejamiento son que la citosina siempre se empareja con guanina y la timina siempre se empareja con adenina. Estas cadenas de ADN se replican durante la división celular somática (es decir, la división de todas las células excepto las destinadas a ser células sexuales) y la información genética completa se transmite a las células resultantes
Los genes forman parte de los cromosomas y están codificados en las cadenas de ADN. Las secciones funcionales individuales del ADN filiforme se denominan genes. La información codificada en los genes dirige el mantenimiento y desarrollo de la célula y el organismo. Esta información recorre un camino desde la entrada hasta la salida: ADN (genes) ⇒ ARNm (ácido ribonucleico mensajero) ⇒ ribosoma/ARNt ⇒ Proteína. En esencia la proteína es la salida final que se genera a partir de los genes, que sirven como planos para las proteínas individuales.
Las proteínas en sí mismas pueden ser componentes estructurales de tu cuerpo (como las fibras musculares) o componentes funcionales (enzimas que ayudan a regular miles de procesos bioquímicos en tu cuerpo). Las proteínas se construyen a partir de cadenas polipeptídicas, que son solo cadenas de aminoácidos (una sola cadena polipeptídica constituye una proteína, pero a menudo las proteínas funcionales están compuestas por múltiples cadenas polipeptídicas).
El mensaje genético se comunica desde el ADN del núcleo celular a los ribosomas fuera del núcleo a través del ARN mensajero (los ribosomas son componentes celulares que ayudan en la eventual construcción de la proteína final). La transcripción es el proceso en el que se genera ARN mensajero a partir del ADN. El ARN mensajero es una copia de una sección de una sola cadena de nucleótidos. Se trata de una sola hebra, exactamente igual que el ADN excepto por diferencias en el azúcar nucleotídico y que la base timina es reemplazada por uracilo. El ARN mensajero se forma por la misma regla de emparejamiento de bases que el ADN excepto que T se reemplaza por U (C a G, U a A).
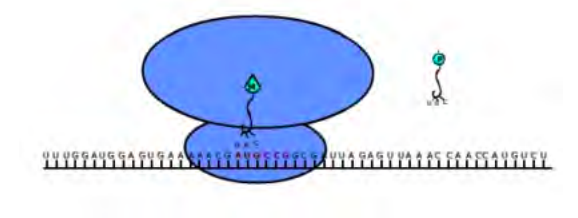
Este ARN mensajero se traduce en el cuerpo celular, con la ayuda de ribosomas y ARNt, en una cadena de aminoácidos (una proteína). El ribosoma mantiene el ARN mensajero en su lugar y el ARN de transferencia coloca el aminoácido apropiado en la proteína formadora, ilustrada esquemáticamente en la Figura 2.4.
El ARN mensajero se traduce en una proteína acoplándose primero con un ribosoma. Un ARNt iniciador se une al ribosoma en un punto correspondiente a un codón de inicio en la cadena de ARNm, en humanos esto corresponde al codón AUG. Esta molécula de ARNt lleva el aminoácido apropiado llamado por el codón y coincide con la cadena de ARNm en otra ubicación a lo largo de su cadena de nucleótidos llamada anticodón. Los enlaces se forman a través de la misma regla de emparejamiento de bases para ARNm y ADN (hay algunas excepciones de emparejamiento que se ignorarán por simplicidad). Entonces una segunda molécula de ARNt se acoplará en el ribosoma de la ubicación vecina indicada por el siguiente codón. También estará portando el aminoácido correspondiente que el codón requiera. Una vez que ambas moléculas de ARNt están acopladas en el ribosoma, los aminoácidos que llevan se unen entre sí. La molécula inicial de ARNt se desprenderá dejando atrás su aminoácido en una cadena de aminoácidos que ahora crece. Luego, el ribosoma se desplazará sobre una ubicación en la cadena de ARNm para dejar espacio para que otra molécula de ARNt se acople con otro aminoácido. Este proceso continuará hasta que se lea un codón de parada en el ARNm; en humanos los factores de terminación son UAG, UAA y UGA. Cuando se lee el codón de parada, la cadena de aminoácidos (proteína) se liberará sobre la estructura del ribosoma.
¿Qué son los aminoácidos? Son compuestos orgánicos con un átomo de carbono central, al que está unido por enlaces covalentes
- un solo átomo de hidrógeno H
- un grupo amino NH\(_2\)
- un grupo carboxilo COOH
- una cadena lateral, diferente para cada aminoácido
Las cadenas laterales varían en complejidad desde un solo átomo de hidrógeno (para el aminoácido glicina), hasta estructuras que incorporan hasta 18 átomos (arginina). Así cada aminoácido contiene entre 10 y 27 átomos. Exactamente veinte aminoácidos diferentes (a veces llamados los “aminoácidos comunes”) se utilizan en la producción de proteínas como se describió anteriormente. Diez de estos se consideran “esenciales” porque no se fabrican en el cuerpo humano y por lo tanto deben adquirirse a través de la alimentación (la arginina es esencial para lactantes y niños en crecimiento). Nueve aminoácidos son hidrofílicos (solubles en agua) y ocho son hidrofóbicos (los otros tres se llaman “especiales”). De los aminoácidos hidrofílicos, dos tienen carga neta negativa en sus cadenas laterales y por lo tanto son ácidos, tres tienen una carga neta positiva y por lo tanto son básicos; y cuatro tienen cadenas laterales no cargadas. Por lo general, las cadenas laterales consisten completamente en átomos de hidrógeno, nitrógeno, carbono y oxígeno, aunque dos (cisteína y metionina) también tienen azufre.
Hay veinte aminoácidos comunes diferentes que necesitan ser codificados y solo cuatro bases diferentes. ¿Cómo se hace esto? Como entidades individuales los nucleótidos (A, C, T o G) sólo podían codificar para cuatro aminoácidos, obviamente no lo suficiente. Como pares podrían codificar para 16 (4\(^2\)) aminoácidos, nuevamente no lo suficiente. Con tripletes podríamos codificar 64 (4\(^3\)) posibles aminoácidos — así es como se hace realmente en el cuerpo, y la cadena de tres nucleótidos juntos se llama codón. ¿Por qué se hace esto? ¿Cómo ha desarrollado la evolución un código tan ineficiente con tanta redundancia? Existen múltiples codones para un solo aminoácido por dos razones biológicas principales: existen múltiples especies de ARNt con diferentes anticodones para llevar ciertos aminoácidos al ribosoma, y pueden ocurrir errores/apareamiento descuidado durante la traducción (esto se llama bamboleo).
Los codones, cadenas de tres nucleótidos, codifican así los aminoácidos. En las tablas a continuación se encuentran el código genético, desde el codón de ARN mensajero hasta el aminoácido, y diversas propiedades de los aminoácidos\(^1\) En las tablas siguientes * significa (U, C, A o G); así CU* podría ser CUU, CUC, CUA, o CUG.
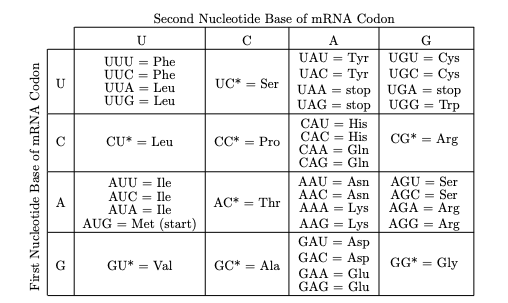
Tabla 2.5: Gráfico condensado de aminoácidos
| Símbolos | Aminoácido | M Wt | Propiedades | Codón (s) | ||
|---|---|---|---|---|---|---|
| Ala | A | Alanina | 89.09 | No esencial | hidrofóbico | GC* |
| Arg | R | Arginina | 174.20 | Esencial | Hidrofílico, básico | CG* AGA AGG |
| Asn | N | Asparagina | 132.12 | No esencial | Hidrofílico, sin carga | AAU AAC |
| Asp | D | Ácido aspártico | 133.10 | No esencial | Hidrofílico, ácido | GAU GAC |
| Cys | C | Cisteina | 121.15 | No esencial | Especial | UGU UGC |
| Gln | Q | Glutamina | 146.15 | No esencial | Hidrofílico, sin carga | CAA CAG |
| Glu | E | Ácido glutámico | 147.13 | No esencial | Hidrofílico, ácido | GAA MORDAZA |
| Gly | G | Glicina | 75.07 | No esencial | Especial | GG* |
| Su | H | Histidina | 155.16 | Esencial | Hidrofílico, sin carga | CAU CAC |
| Ile | I | Isoleucina | 131.17 | Esencial | Hidrofílico, ácido | AUU AUC AUA |
| Leu | L | Leucina | 131.17 | Esencial | Especial | UUA UUG CU* |
| Lys | K | Lisina | 146.19 | Esencial | Hidrofílico, básico | AAA AAG |
| Met | M | Metionina | 149.21 | Esencial | Hidrofóbico | AGO |
| Phe | F | Fenilalanina | 165.19 | Esencial | Hidrofóbico | UUU UUC |
| Pro | P | Prolina | 115.13 | No esencial | Especial | CC* |
| Ser | S | Serina | 105.09 | No esencial | Hidrofílico, sin carga | UC* AGU AGC |
| Thr | T | Treonina | 119.12 | Esencial | Hidrofílico, sin carga | AC* |
| Trp | W | Triptófano | 204.23 | Esencial | Hidrofóbico | UGG |
| Tyr | Y | Tirosina | 181.19 | No esencial | Hidrofóbico | UAU UAC |
| Val | V | Valina | 117.15 | Esencial | Hidrofóbico | GU* |
| iniciar | Metionina | AGO | ||||
| detener | UAA UAG UGA | |||||
*Esta sección está basada en notas escritas por Tim Wagner
\(^1\)shown are the one-letter abbreviation for each, its molecular weight, and some of its properties, taken from H. Lodish, D. Baltimore, A. Berk, S. L. Zipursky, P. Matsudaira, and J. Darnell, “Molecular Cell Biology,” third edition, W. H. Freeman and Company, New York, NY; 1995.