
5: Probabilidad




- Última actualización
- 30 oct 2022
- Guardar como PDF

( \newcommand{\kernel}{\mathrm{null}\,}\)
Hemos estado considerando un modelo de un sistema de manejo de información en el que los símbolos de una entrada se codifican en bits, que luego se envían a través de un “canal” a un receptor y se vuelven a decodificar en símbolos. Ver Figura 5.1.
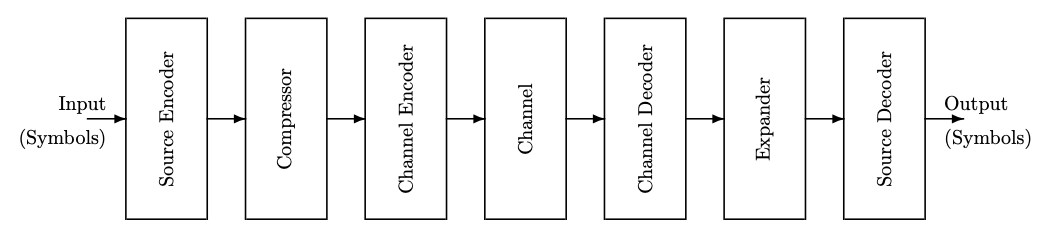
En capítulos anteriores de estas notas hemos mirado diversos componentes de este modelo. Ahora volvemos a la fuente y la modelizamos de manera más completa, en términos de distribuciones de probabilidad.
La fuente proporciona un símbolo o una secuencia de símbolos, seleccionados de algún conjunto. El proceso de selección puede ser un experimento, como voltear una moneda o rodar dados. O podría ser la observación de acciones no provocadas por el observador. O la secuencia de símbolos podría ser de una representación de algún objeto, como caracteres de texto, o píxeles de una imagen.
Consideramos solo casos con un número finito de símbolos para elegir, y solo casos en los que los símbolos son ambos mutuamente excluyentes (solo se puede elegir uno a la vez) y exhaustivos (uno es realmente elegido). Cada elección constituye un “resultado” y nuestro objetivo es rastrear la secuencia de resultados, y la información que los acompaña, a medida que la información viaja de la entrada a la salida. Para ello, necesitamos poder decir cuál es el resultado, y también nuestro conocimiento sobre algunas propiedades del resultado.
Si conocemos el resultado, tenemos una manera perfectamente buena de denotar el resultado. Podemos simplemente nombrar al símbolo elegido, e ignorar el resto de los símbolos, que no fueron elegidos. Pero, ¿y si aún no conocemos el resultado, o somos inciertos en algún grado? ¿Cómo se supone que debemos expresar nuestro estado de conocimiento si hay incertidumbre? Utilizaremos las matemáticas de probabilidad para este propósito.
Para ilustrar esta importante idea, utilizaremos ejemplos basados en las características de los estudiantes del MIT. El recuento oficial de alumnos en el MIT1 para el otoño de 2007 incluye los datos en la Tabla 5.1, que se reproduce en formato de diagrama de Venn en la Figura 5.2.
| Mujeres | Hombres | Total | |
| Estudiantes de primer año | 496 | 577 | 1,073 |
| Graduados | 1,857 | 2,315 | 4,172 |
| Estudiantes de Posgrado | 1,822 | 4,226 | 6,048 |
| Total Alumnos | 3,679 | 6,541 | 10,220 |
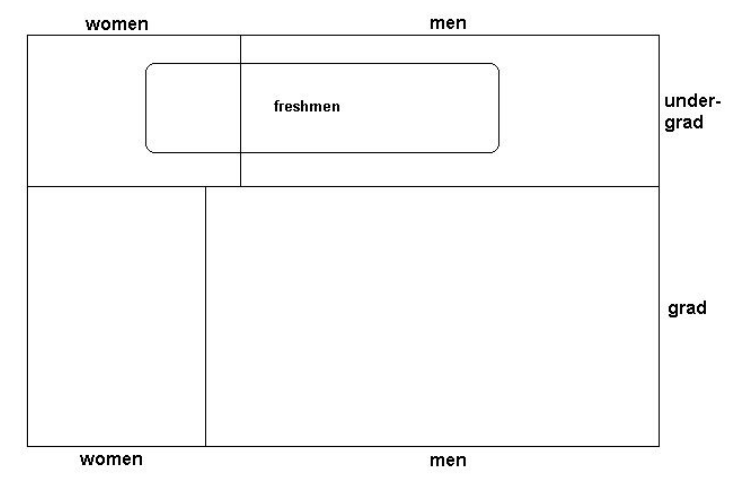
Supongamos que se selecciona un estudiante de primer año del MIT (el símbolo que se elige es un estudiante individual, y el conjunto de símbolos posibles son los estudiantes de primer año de 1073), y no se le informa quién es. Te preguntas si es una mujer o un hombre. Por supuesto que si conocieras la identidad del alumno seleccionado, sabrías el género. Pero si no, ¿cómo podrías caracterizar tus conocimientos? ¿Cuál es la probabilidad, o probabilidad, de que se haya seleccionado a una mujer?
Tenga en cuenta que 46% de la clase de primer año de 2007 (496/1,073) son mujeres. Se trata de un hecho, o una estadística, que puede representar o no la probabilidad de que el estudiante de primer año elegido sea una mujer. Si tuvieras razones para creer que todos los estudiantes de primer año tenían la misma probabilidad de ser elegidos, podrías decidir que la probabilidad de que sea mujer es del 46%. Pero, ¿y si te dicen que la selección se hace en el pasillo de McCormick Hall (un dormitorio de mujeres)? En ese caso la probabilidad de que el estudiante de primer año elegido sea una mujer probablemente sea superior al 46%. Tanto las estadísticas como las probabilidades pueden describirse usando las mismas matemáticas (que se desarrollarán a continuación), pero son cosas diferentes.
1todas las alumnas: http://web.mit.edu/registrar/www/sta...portfinal.html, todas las mujeres: http://web.mit.edu/registrar/www/sta...omenfinal.html