
17.1: Ajuste de datos en ausencia de ruido y sesgo
- Page ID
- 87812

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Motivamos nuestra discusión reconsiderando el ejemplo de coeficiente de fricción del Capítulo 15. Recordamos que, según Amontons, la fricción estática,\(F_{\mathrm{f}, \text { static }}\), y la fuerza normal aplicada\(F_{\text {normal, applied, }}\),, están relacionados por\[F_{\mathrm{f}, \text { static }} \leq \mu_{\mathrm{s}} F_{\text {normal, applied }}\] aquí\(\mu_{\mathrm{s}}\) es el coeficiente de fricción, que sólo depende de los dos materiales en contacto. En particular, la fricción estática máxima es una función lineal de la fuerza normal aplicada, es decir,\[F_{\mathrm{f}, \text { static }}^{\max }=\mu_{\mathrm{s}} F_{\text {normal, applied }} .\] deseamos deducir\(\mu_{\mathrm{s}}\) midiendo la fricción estática máxima alcanzable para varios valores diferentes de la fuerza normal aplicada.
Nuestro enfoque de este problema es elegir primero la forma de un modelo basado en principios físicos y luego deducir los parámetros a partir de un conjunto de mediciones. En particular, consideremos un modelo afín simple\[y=Y_{\text {model }}(x ; \beta)=\beta_{0}+\beta_{1} x .\] La variable\(y\) es la cantidad predicha, o la salida, que es la fricción estática máxima\(F_{\mathrm{f}, \text { static }}^{\max }\). La variable\(x\) es la variable independiente, o la entrada, que es la fuerza normal máxima\(F_{\text {normal, applied }}\). La función\(Y_{\text {model }}\) es nuestro modelo predictivo el cual es parametrizado por un parámetro\(\beta=\left(\beta_{0}, \beta_{1}\right)\). Tenga en cuenta que la ley de Amontons es un caso particular de nuestro modelo afín general con\(\beta_{0}=0\) y\(\beta_{1}=\mu_{\mathrm{s}}\). Si tomamos medidas\(m\) sin ruido y la ley de Amontons es exacta, entonces esperamos que\[F_{\mathrm{f}, \text { static } i}^{\max }=\mu_{\mathrm{S}} F_{\text {normal, applied } i}, \quad i=1, \ldots, m\] la ecuación se satisfaga exactamente para cada una de las\(m\) mediciones. En consecuencia, también hay una solución única a nuestro problema de identificación de modelo-parámetro\[y_{i}=\beta_{0}+\beta_{1} x_{i}, \quad i=1, \ldots, m,\] con la solución dada por\(\beta_{0}^{\text {true }}=0\) y\(\beta_{1}^{\text {true }}=\mu_{\mathrm{s}}\).
Debido a que la dependencia de la salida\(y\) sobre los parámetros del modelo\(\left\{\beta_{0}, \beta_{1}\right\}\) es lineal, podemos escribir el sistema de ecuaciones como una ecuación\(m \times 2\) matricial\[\underbrace{\left(\begin{array}{cc} 1 & x_{1} \\ 1 & x_{2} \\ \vdots & \vdots \\ 1 & x_{m} \end{array}\right)}_{X} \underbrace{\left(\begin{array}{c} \beta_{0} \\ \beta_{1} \end{array}\right)}_{\beta}=\underbrace{\left(\begin{array}{c} y_{1} \\ y_{2} \\ \vdots \\ y_{m} \end{array}\right)}_{Y},\] o, de manera más compacta,\[X \beta=Y .\] Usando la interpretación de fila de la multiplicación matriz-vector, nosotros recuperar inmediatamente el conjunto original de ecuaciones,\[X \beta=\left(\begin{array}{c} \beta_{0}+\beta_{1} x_{1} \\ \beta_{0}+\beta_{1} x_{2} \\ \vdots \\ \beta_{0}+\beta_{1} x_{m} \end{array}\right)=\left(\begin{array}{c} y_{1} \\ y_{2} \\ \vdots \\ y_{m} \end{array}\right)=Y .\] O, utilizando la interpretación de columnas, vemos que nuestro problema de ajuste de parámetros corresponde a elegir los dos pesos para que los dos\(m\) -vectores coincidan con el lado derecho,\[X \beta=\beta_{0}\left(\begin{array}{c} 1 \\ 1 \\ \vdots \\ 1 \end{array}\right)+\beta_{1}\left(\begin{array}{c} x_{1} \\ x_{2} \\ \vdots \\ x_{m} \end{array}\right)=\left(\begin{array}{c} y_{1} \\ y_{2} \\ \vdots \\ y_{m} \end{array}\right)=Y .\] enfatizamos que el sistema lineal \(X \beta=Y\)está sobredeterminado, es decir, más ecuaciones que incógnitas\((m>n)\). (Estudiamos esto con más detalle en la siguiente sección.) Sin embargo, aún podemos encontrar una solución al sistema porque se cumplen las siguientes dos condiciones:
Imparcial: Nuestro modelo incluye la verdadera dependencia funcional\(y=\mu_{\mathrm{s}} x\), y así el modelo es capaz de representar esta verdadera dependencia funcional subyacente. Este no sería el caso si, por ejemplo, consideramos un modelo constante\(y(x)=\beta_{0}\) porque nuestro modelo sería incapaz de representar la dependencia lineal de la fuerza de fricción sobre la fuerza normal. Claramente, la suposición de no sesgo es una suposición muy fuerte dada la complejidad del mundo físico.
Sin ruido: Tenemos medidas perfectas: cada medición\(y_{i}\) correspondiente a la variable independiente\(x_{i}\) proporciona el valor “exacto” de la fuerza de fricción. Obviamente esto vuelve a ser bastante naïve y tendrá que estar relajado.
Bajo estos supuestos, existe un parámetro\(\beta^{\text {true }}\) que describe completamente las mediciones, es decir\[y_{i}=Y_{\text {model }}\left(x ; \beta^{\text {true }}\right), \quad i=1, \ldots, m .\] (El\(\beta^{\text {true }}\) será único si las columnas de\(X\) son independientes.) En consecuencia, nuestro modelo predictivo es perfecto, y podemos predecir exactamente el resultado experimental para cualquier elección de\(x\), es decir,\[Y(x)=Y_{\text {model }}\left(x ; \beta^{\text {true }}\right), \quad \forall x,\] dónde\(Y(x)\) está la medición experimental correspondiente a la condición descrita por\(x\). Sin embargo, en la práctica, los supuestos libres de sesgos y sin ruido rara vez se satisfacen, y nuestro modelo nunca es un predictor perfecto de la realidad.
En el Capítulo 19, desarrollaremos una herramienta probabilística para cuantificar el efecto del ruido y el sesgo; el capítulo actual se enfoca en desarrollar una técnica de mínimos cuadrados para resolver un sistema lineal sobredeterminado (en el contexto determinista) que es esencial para resolver estos problemas de ajuste de datos. En particular consideraremos una estrategia para resolver sistemas lineales sobredeterminados de la forma\[B z=g,\] donde\(B \in \mathbb{R}^{m \times n}, z \in \mathbb{R}^{n}\), y\(g \in \mathbb{R}^{m}\) con\(m>n\).
Antes de discutir la estrategia de mínimos cuadrados, consideremos otro ejemplo de sistemas sobredeterminados en el contexto del ajuste polinómico. Consideremos una partícula que experimenta una aceleración constante, por ejemplo, debido a la gravedad. Sabemos que la posición\(y\) de la partícula en el tiempo\(t\) es descrita por una función cuadrática\[y(t)=\frac{1}{2} a t^{2}+v_{0} t+y_{0},\] donde\(a\) está la aceleración,\(v_{0}\) es la velocidad inicial, y\(y_{0}\) es la posición inicial. Supongamos que no conocemos los tres parámetros\(a, v_{0}\), y\(y_{0}\) que gobiernan el movimiento de la partícula y nos interesa determinar los parámetros. Podríamos hacer esto midiendo primero la posición de la partícula en varios momentos diferentes y registrando los pares\(\left\{t_{i}, y\left(t_{i}\right)\right\}\). Entonces, podríamos ajustar nuestras mediciones al modelo cuadrático para deducir los parámetros.
El problema de encontrar los parámetros que gobiernan el movimiento de la partícula es un caso especial de un problema más general: el ajuste polinómico. Consideremos un polinomio cuadrático, es decir,\[y(x)=\beta_{0}^{\text {true }}+\beta_{1}^{\text {true }} x+\beta_{2}^{\text {true }} x^{2},\] dónde\(\beta^{\text {true }}=\left\{\beta_{0}^{\text {true }}, \beta_{1}^{\text {true }}, \beta_{2}^{\text {true }}\right\}\) está el conjunto de parámetros verdaderos que caracterizan el fenómeno modelado. Supongamos que no sabemos\(\beta^{\text {true }}\) pero sí sabemos que nuestra salida depende de la entrada de\(x\) manera cuadrática. Así, consideramos un modelo de la forma\[Y_{\text {model }}(x ; \beta)=\beta_{0}+\beta_{1} x+\beta_{2} x^{2},\] y determinamos los coeficientes midiendo la salida\(y\) para varios valores diferentes de\(x\). Somos libres de elegir el número de medidas\(m\) y los puntos de medición\(x_{i}, i=1, \ldots, m\). En particular, al elegir los puntos de medición y tomar una medición en cada punto, obtenemos un sistema de ecuaciones lineales,\[y_{i}=Y_{\text {model }}\left(x_{i} ; \beta\right)=\beta_{0}+\beta_{1} x_{i}+\beta_{2} x_{i}^{2}, \quad i=1, \ldots, m,\] donde\(y_{i}\) está la medición correspondiente a la entrada\(x_{i}\).
Obsérvese que la ecuación es lineal en nuestras incógnitas\(\left\{\beta_{0}, \beta_{1}, \beta_{2}\right\}\) (la aparición de\(x_{i}^{2}\) solo afecta la manera en que los datos ingresan a la ecuación). Debido a que la dependencia de los parámetros es lineal, podemos escribir el sistema como ecuación matricial,\[\underbrace{\left(\begin{array}{c} y_{1} \\ y_{2} \\ \vdots \\ y_{m} \end{array}\right)}_{Y}=\underbrace{\left(\begin{array}{ccc} 1 & x_{1} & x_{1}^{2} \\ 1 & x_{2} & x_{2}^{2} \\ \vdots & \vdots & \vdots \\ 1 & x_{m} & x_{m}^{2} \end{array}\right)}_{X} \underbrace{\left(\begin{array}{c} \beta_{0} \\ \beta_{1} \\ \beta_{2} \end{array}\right)}_{\beta},\] o, de manera más compacta,\[Y=X \beta .\] Tenga en cuenta que esta matriz en particular\(X\) tiene una estructura bastante especial - cada fila forma una serie geométrica y se da la\(i j\) -ésima entrada por\(B_{i j}=x_{i}^{j-1}\). Las matrices con esta estructura se denominan matrices Vandermonde.
Al igual que en el ejemplo del coeficiente de fricción considerado anteriormente, la interpretación de fila del producto matriz-vector recupera el conjunto original de ecuaciones\[Y=\left(\begin{array}{c} y_{1} \\ y_{2} \\ \vdots \\ y_{m} \end{array}\right)=\left(\begin{array}{c} \beta_{0}+\beta_{1} x_{1}+\beta_{2} x_{1}^{2} \\ \beta_{0}+\beta_{1} x_{2}+\beta_{2} x_{2}^{2} \\ \vdots \\ \beta_{0}+\beta_{1} x_{m}+\beta_{2} x_{m}^{2} \end{array}\right)=X \beta .\] Con la interpretación de columna, inmediatamente reconocemos que esto es un problema de encontrar los tres coeficientes, o parámetros, de la combinación lineal que produce el\(m\) -vector deseado\(Y\), es decir\[Y=\left(\begin{array}{c} y_{1} \\ y_{2} \\ \vdots \\ y_{m} \end{array}\right)=\beta_{0}\left(\begin{array}{c} 1 \\ 1 \\ \vdots \\ 1 \end{array}\right)+\beta_{1}\left(\begin{array}{c} x_{1} \\ x_{2} \\ \vdots \\ x_{m} \end{array}\right)+\beta_{2}\left(\begin{array}{c} x_{1}^{2} \\ x_{2}^{2} \\ \vdots \\ x_{m}^{2} \end{array}\right)=X \beta .\] Sabemos que si tenemos tres o más mediciones no degeneradas (i.e.,\(m \geq 3\)), entonces podemos encontrar la solución única al sistema lineal. Además, la solución son los coeficientes del polinomio subyacente,\(\left(\beta_{0}^{\text {true }}, \beta_{1}^{\text {true }}, \beta_{2}^{\text {true }}\right)\).
Ejemplo 17.1.1 Un polinomio cuadrático
Consideremos un caso más específico, donde el polinomio subyacente es de la forma\[y(x)=-\frac{1}{2}+\frac{2}{3} x-\frac{1}{8} c x^{2} .\] Reconocemos que\(y(x)=Y_{\text {model }}\left(x ; \beta^{\text {true }}\right)\) for\(Y_{\text {model }}(x ; \beta)=\beta_{0}+\beta_{1} x+\beta_{2} x^{2}\) y los verdaderos parámetros\[\beta_{0}^{\text {true }}=-\frac{1}{2}, \quad \beta_{1}^{\text {true }}=\frac{2}{3}, \quad \text { and } \quad \beta_{2}^{\text {true }}=-\frac{1}{8} c\] El parámetro\(c\) controla el grado de dependencia cuadrática; en particular, \(c=0\)da como resultado una función afín.
Primero, consideramos el caso con\(c=1\), lo que resulta en una fuerte dependencia cuadrática, es decir,\(\beta_{2}^{\text {true }}=-1 / 8\). El resultado de medir\(y\) en tres puntos no degenerados\((m=3)\) se muestra en la Figura\(17.1(\mathrm{a})\). Resolviendo el sistema\(3 \times 3\) lineal con los coeficientes como lo desconocido, obtenemos\[\beta_{0}=-\frac{1}{2}, \quad \beta_{1}=\frac{2}{3}, \quad \text { and } \quad \beta_{2}=-\frac{1}{8} .\]
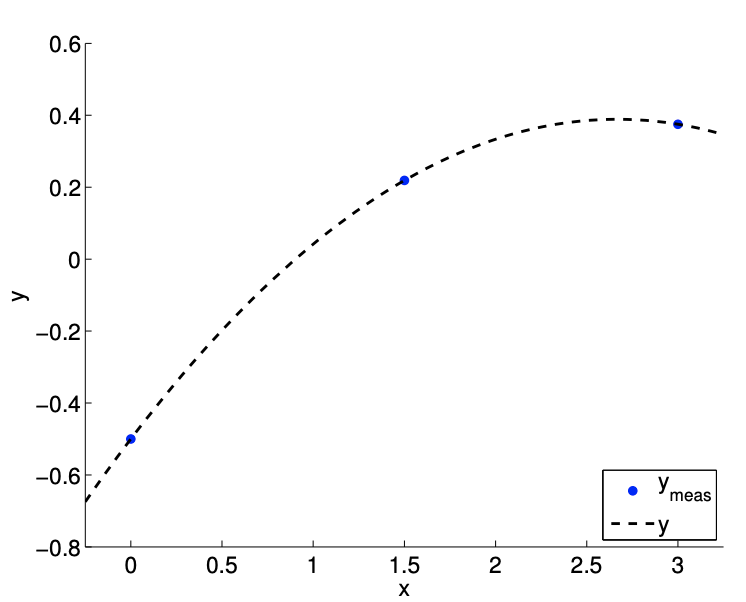
(a)\(m=3\)

b)\(m=7\)
Figura 17.1: Deduciendo los coeficientes de un polinomio con una fuerte dependencia cuadrática.
No es sorprendente que podamos encontrar los verdaderos coeficientes de la ecuación cuadrática usando tres puntos de datos.
Supongamos que tomamos más medidas. Un ejemplo de tomar siete mediciones\((m=7)\) se muestra en la Figura 17.1 (b). Ahora tenemos siete puntos de datos y tres incógnitas, por lo que debemos resolver el sistema\(7 \times 3\) lineal, es decir, encontrar el conjunto\(\beta=\left\{\beta_{0}, \beta_{1}, \beta_{2}\right\}\) que satisfaga las siete ecuaciones. La solución al sistema lineal, por supuesto, viene dada por\[\beta_{0}=-\frac{1}{2}, \quad \beta_{1}=\frac{2}{3}, \quad \text { and } \quad \beta_{2}=-\frac{1}{8} .\] El resultado es correcto\(\left(\beta=\beta^{\text {true }}\right)\) y, en particular, no difiere del resultado para el\(m=3\) caso.
Podemos modificar ligeramente el polinomio subyacente y repetir el mismo ejercicio. Por ejemplo, consideremos el caso con\(c=1 / 10\), lo que resulta en una dependencia cuadrática mucho más débil de\(y\) on\(x\), es decir,\(\beta_{2}^{\text {true }}=-1 / 80\). Como se muestra en la Figura 17.1.1, podemos tomar cualquiera\(m=3\) o\(m=7\) mediciones. Similar al\(c=1\) caso, identificamos los coeficientes verdaderos,\[\beta_{0}=-\frac{1}{2}, \quad \beta_{1}=\frac{2}{3}, \quad \text { and } \beta_{2}=-\frac{1}{80},\] utilizando cualquiera\(m=3\) o\(m=7\) (de hecho usando tres o más mediciones no degeneradas).
En la determinación del coeficiente de fricción y los problemas de identificación polinómica (movimiento de partículas), hemos visto que podemos encontrar una solución al sistema\(m \times n\) sobredeterminado\((m>n)\) si
(a) nuestro modelo incluye la dependencia funcional subyacente insumo-producto, sin sesgo;
(b) y las mediciones son perfectas, sin ruido.
Como ya se dijo, en la práctica, estos dos supuestos rara vez se satisfacen; es decir, los modelos suelen estar (de hecho, siempre) incompletos y las mediciones suelen ser inexactas. (Por ejemplo, en nuestro modelo de movimiento de partículas, hemos descuidado la fricción). Todavía podemos construir un sistema\(m \times n\) lineal\(B z=g\) usando nuestro modelo y mediciones, pero la solución al sistema en general no existe. Sabiendo que no podemos encontrar la “solución” al sistema lineal sobredeterminado, nuestro objetivo es

(a)\(m=3\)

b)\(m=7\)
Figura 17.2: Deduciendo los coeficientes de un polinomio con una dependencia cuadrática débil.
para encontrar una solución que esté “cerca” de satisfacer la solución. En la siguiente sección, definiremos la noción de “cercanía” adecuada para nuestro análisis e introduciremos un procedimiento general para encontrar la solución “más cercana” a un sistema general sobredeterminado de la forma\[B z=g,\] donde\(B \in \mathbb{R}^{m \times n}\) con\(m>n\). Posteriormente abordaremos el significado y la interpretación de esta (no) solución.